牛客面试题
Spring-牛客面经八股
1. 说说 Spring Boot 常用的注解
@SpringBootApplication:组合注解(@Configuration+@EnableAutoConfiguration+@ComponentScan),应用入口常放在主类上。@Configuration/@Bean:定义配置类和显式创建 Bean。@Component/@Service/@Repository/@Controller/@RestController:组件扫描管理类;@RestController = @Controller + @ResponseBody。@Autowired/@Qualifier/@Value/@Resource:依赖注入、按类型/按名称注入、读取配置。@ConfigurationProperties:将一组配置绑定到 POJO(推荐用于复杂配置)。@EnableAutoConfiguration(隐含在@SpringBootApplication中):启用自动配置。- 条件注解(常用于自动配置类):
@ConditionalOnClass、@ConditionalOnMissingBean、@ConditionalOnProperty、@ConditionalOnBean等。 @Transactional:声明式事务。@RestControllerAdvice/@ControllerAdvice:统一异常/全局处理。- 测试相关:
@SpringBootTest、@WebMvcTest、@DataJpaTest等。 - 其他:
@EnableScheduling、@EnableCaching、@EnableFeignClients、@EnableDiscoveryClient等(看用到的组件)。
示例:
1 |
|
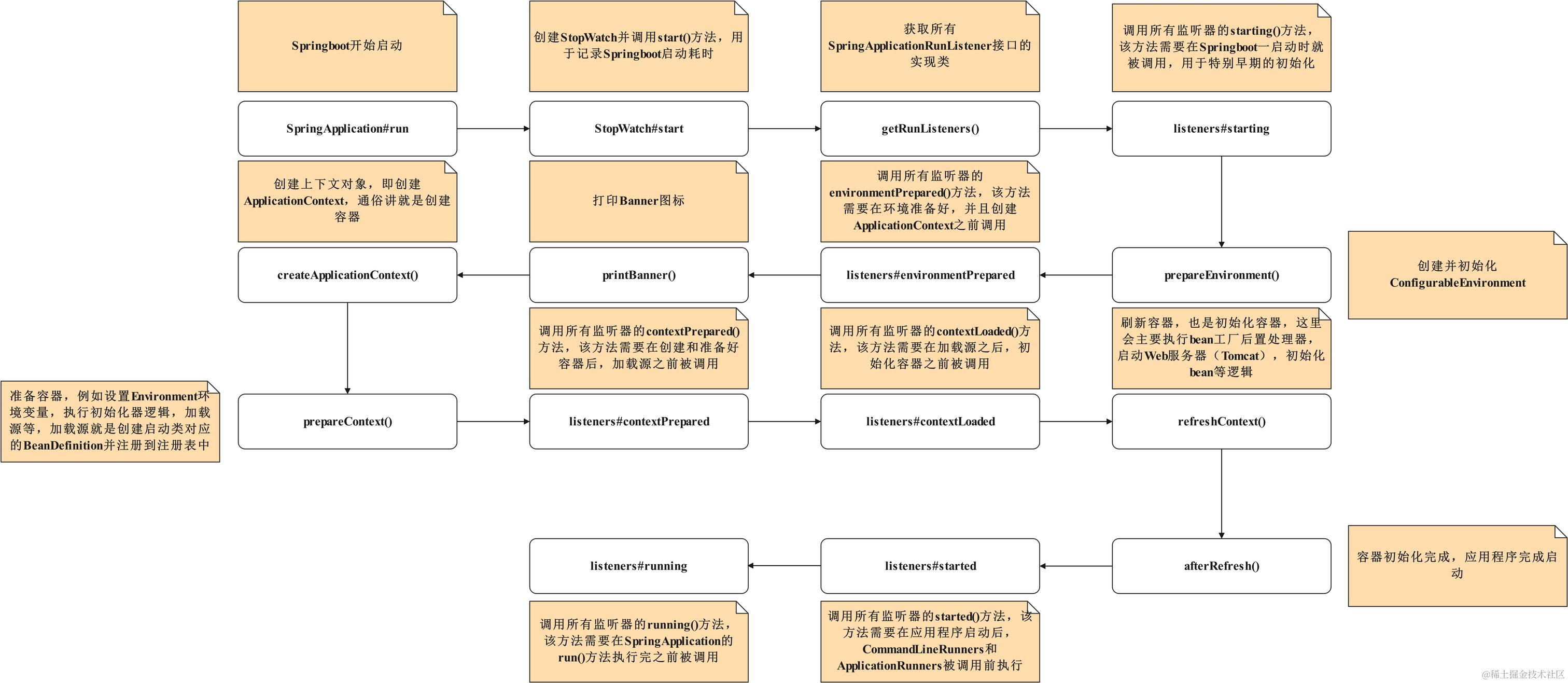
2.Spring Boot 启动流程
入口一般是:
1 |
|
- 作用:创建一个
SpringApplication实例,准备运行环境。 - 关键点:
- 判断当前应用类型(
NONE、SERVLET、REACTIVE),决定用什么样的ApplicationContext。 - 加载并设置
ApplicationContextInitializer和ApplicationListener。
- 判断当前应用类型(
- 事件:
ApplicationStartingEvent。 - 触发时机:Spring 环境还未初始化前。
- 用途:做一些极早期的日志初始化、Banner 输出等。
- 工作内容:
- 创建
ConfigurableEnvironment(不同应用类型对应不同环境类)。 - 加载配置源:系统属性、环境变量、命令行参数、
application.properties/application.yml、@PropertySource。 - 执行
ConfigFileApplicationListener,解析并注入配置文件属性。
- 创建
- 扩展点:可通过
EnvironmentPostProcessor在环境准备阶段修改/添加配置。
- 默认情况:
- 普通应用 →
AnnotationConfigApplicationContext - Web Servlet 应用 →
AnnotationConfigServletWebServerApplicationContext - Web Reactive 应用 →
AnnotationConfigReactiveWebServerApplicationContext
- 普通应用 →
- 扩展点:可通过
SpringApplication.setApplicationContextClass()自定义上下文类型。
- 作用:在
ApplicationContext刷新之前,可以对其进行个性化处理。 - 加载方式:
spring.factories中的ApplicationContextInitializer。SpringApplication.addInitializers(...)手动添加。
- 应用场景:在容器 refresh 前注册属性源、配置 BeanDefinition 等。
- 关键机制:
@EnableAutoConfiguration触发AutoConfigurationImportSelector。- 从
META-INF/spring.factories或META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports加载所有候选配置类。 - 通过
@ConditionalOnClass、@ConditionalOnBean、@ConditionalOnMissingBean等条件注解筛选。
- 结果:按需装配 starter 中的 Bean(如
DataSourceAutoConfiguration、WebMvcAutoConfiguration等)。
- 代表类:
ConfigurationClassPostProcessor:解析@Configuration类、@ComponentScan、@Import、@Bean等注解。- 其他定制的
BeanFactoryPostProcessor。
- 扩展点:可以在 BeanDefinition 阶段修改 bean 的元数据。
过程:
- 实例化(调用构造器)。
- 依赖注入(populate 属性)。
- 回调 Aware 接口(如
BeanNameAware、ApplicationContextAware)。 - BeanPostProcessor#postProcessBeforeInitialization。
- 初始化方法(
@PostConstruct、InitializingBean.afterPropertiesSet()、自定义 init-method)。 - BeanPostProcessor#postProcessAfterInitialization`。
- 最终放入一级缓存(
singletonObjects)。
- 标志事件:
ApplicationStartedEvent:容器启动完成。ApplicationReadyEvent:应用准备好接收请求。
- 其他事件:
ContextRefreshedEvent(上下文刷新完成)。WebServerInitializedEvent(WebServer 启动完成)。
- 成功:Web 应用启动,内嵌 Tomcat/Jetty/Undertow 已经监听端口。
- 失败:触发
ApplicationFailedEvent,进入FailureAnalyzers分析错误并输出人性化提示。
🔑 重要扩展点总结
ApplicationListeners:贯穿整个生命周期,可监听各种事件。
ApplicationContextInitializer:在容器刷新前定制化上下文。
BeanFactoryPostProcessor:修改 BeanDefinition。
BeanPostProcessor:定制 Bean 实例化前后行为。
@ConditionalOn…:自动配置的核心。
3. 对 IoC(Inversion of Control / 依赖注入)的理解
- 本质:把对象的创建和依赖的组装(控制权)从类内部移到容器(Spring)来管理——“控制反转”。实际表现为依赖注入(Dependency Injection)。
- 优点:解耦(组件只声明依赖,不负责创建)、易测试(可以注入 mock)、统一管理生命周期、便于 AOP 切面化。
- 注入方式:构造器注入(推荐,强制依赖、利于测试)、setter 注入、字段注入(简便但不推荐)。
- 容器职责:管理 bean 的实例化、装配、生命周期、作用域(singleton/prototype/request/session)等。
4. 对 AOP(面向切面编程)的理解
- 目的:把横切关注点(日志/事务/安全/缓存等)从业务代码分离出来。
- 术语:切面(Aspect)、通知(Advice:before/after/around/afterReturning/afterThrowing)、连接点(Join point)、切入点(Pointcut)、目标对象(Target)、代理(Proxy)。
- 实现方式:Spring 默认基于代理(JDK 动态代理:接口;CGLIB:类代理);也可用 AspectJ(编译/类加载期织入)实现更强的能力。
- 常见限制:代理是对象外部的包装 → 自身(同类)方法调用不会触发代理(self-invocation 问题);可用
AopContext.currentProxy()或 AspectJ 解决,或将需要切面的调用拆到另一个 bean。 - 使用示例(注解式):
1 |
|
5. Bean 的生命周期(主要步骤与钩子)
- 实例化(instantiate bean)
- 依赖注入(populate properties)
- Aware 接口回调:
BeanNameAware.setBeanName()、BeanFactoryAware.setBeanFactory()、ApplicationContextAware.setApplicationContext()等 BeanPostProcessor.postProcessBeforeInitialization(...)- 初始化回调:
@PostConstruct、afterPropertiesSet()(InitializingBean)、自定义init-method BeanPostProcessor.postProcessAfterInitialization(...)→ Bean 就绪可用(在容器中)- 销毁(单例在容器关闭时):
@PreDestroy、DisposableBean.destroy()、自定义destroy-method。
- 另外:
SmartLifecycle、InitializingBean、DisposableBean、BeanFactoryPostProcessor、BeanPostProcessor等都参与生命周期扩展。
6. @Autowired 和 @Resource 的区别
- 来源:
@Autowired是 Spring 注解;@Resource是 JSR-250(Java 标准)。 - 注入方式:
@Autowired:按 类型(byType) 注入;若有多个候选可结合@Qualifier或@Primary。支持required(默认true,可设false)或Optional<T>/@Nullable。支持构造器/字段/setter。@Resource:默认按 名称(byName) 注入(会先按 name 属性或字段名匹配 bean 名称),若找不到则回退按类型注入。没有required属性。
- 使用习惯:
@Autowired更常见(Spring 风格);如果需要严格按 bean 名称注入可用@Resource(name="...")。 - 另外:
@Inject(JSR-330)类似@Autowired(按类型)。
7. Spring 事务管理
- 两种方式:声明式(
@Transactional最常见)和编程式(PlatformTransactionManager+TransactionTemplate)。 - 事务管理器(常见):
DataSourceTransactionManager(JDBC)、JpaTransactionManager(JPA/Hibernate)、JtaTransactionManager(分布式/XA)。 @Transactional常用属性:propagation、isolation、readOnly、timeout、rollbackFor/noRollbackFor。- 传播行为(常用几种):
REQUIRED(默认):如果有事务就加入,否则新建。REQUIRES_NEW:挂起当前事务,另启新事务(独立提交/回滚)。NESTED:在同一物理连接上通过 savepoint 实现“子事务”(回滚到 savepoint),只有支持 JDBC 的事务管理器才有效。SUPPORTS、NOT_SUPPORTED、MANDATORY、NEVER等。
- 回滚规则:默认对 unchecked(
RuntimeException、Error)回滚;若要对 checked exception 回滚需指定rollbackFor。 - 注意点:
@Transactional通过 AOP 代理实现(代理对象拦截方法并管理事务),因此同类内部方法调用不会走代理,事务注解不会生效(self-invocation)。解决办法:把方法放到另一个 bean、使用AspectJ或手动通过TransactionTemplate。 - 事务与连接:Spring 管理 JDBC 连接绑定到线程(事务同步),propagation 影响是否复用或者新开连接。
8. Spring MVC 的执行流程(请求到响应的完整链路)
简化流程(按实际处理顺序):
- 客户端请求 → 到
DispatcherServlet(前端控制器,Front Controller)。 HandlerMapping根据 URL 找到对应的 Handler(Controller 方法,内部为HandlerMethod)。- 执行
HandlerInterceptor.preHandle()(可拦截、返回 false 终止)。 HandlerAdapter调用 Controller 方法:内部会执行HandlerMethodArgumentResolver(解析方法参数)和HandlerMethodReturnValueHandler(处理返回值)。对于@ResponseBody/ 返回对象,会交给HttpMessageConverter序列化(JSON/XML)。- Controller 返回
ModelAndView或视图名或响应体。 HandlerInterceptor.postHandle()(可修改 ModelAndView)。ViewResolver解析视图,View渲染最终响应;若@ResponseBody,则直接写出。HandlerInterceptor.afterCompletion()(清理工作),以及ExceptionResolver处理异常路径。
关键扩展点:拦截器、过滤器、异常处理器(@ControllerAdvice / HandlerExceptionResolver)、参数解析(@RequestParam、@PathVariable、@RequestBody)等。
9. @Component 和 @Bean 的区别
@Component:类级注解,交给组件扫描自动发现并注册为 bean。适合你自己写的类。@Bean:方法级注解,放在@Configuration类中,由方法的返回值注册为 bean。适合第三方类或需要程序化创建的 bean。- 细节区别:
@Configuration类会被 CGLIB 代理以保证@Bean方法的单例语义(同一配置类内调用@Bean方法会返回容器中的单例,而不是新实例)。@Component比较“自动”,@Bean更显式、可编程(可以在方法中做复杂逻辑)。- 注入优先级/覆盖规则:
@Bean定义的 bean 名称可和扫描到的组件冲突,容器按注册顺序/配置决定覆盖或报错(可用@Primary、@Order或显式排除)。
10. Spring 中用到的设计模式
- 单例模式(Singleton):Spring 的单例 scope(容器保证)。
- 工厂模式(Factory) / 抽象工厂:
BeanFactory/ApplicationContext提供getBean。 - 代理模式(Proxy):AOP 使用(JDK 动态代理 / CGLIB)。
- 模板方法模式(Template Method):
JdbcTemplate,JmsTemplate等,封装固定流程,留钩子给子类/回调。 - 策略模式(Strategy):可插拔的实现选择,如不同的序列化/编码/厂商策略、事务策略。
- 观察者模式(Observer):
ApplicationEvent/ApplicationListener。 - 前端控制器(Front Controller):
DispatcherServlet。 - 适配器模式(Adapter):
HandlerAdapter用于适配不同 handler。 - 责任链(Chain of Responsibility):Servlet Filter 链、Spring Security 的 filter chain、Interceptor 链。
- 门面模式(Facade):例如
JdbcTemplate对复杂 JDBC 操作的简化封装。
11. Spring 循环依赖是什么?介绍下三级缓存
- 循环依赖:A -> B -> A 的依赖关系。Spring 能自动解决部分场景(单例 bean 且为 setter/属性注入 的情况可以解决;构造器注入 则无法解决)。
- 三级缓存(三缓存)(Spring 单例循环依赖解决的核心):
- singletonObjects(一级缓存)——完全初始化好的单例 bean 实例(最终放这里)。
- earlySingletonObjects(二级缓存)——提前曝光的 bean 实例(未完成初始化但可以被其它 bean 引用,通常用于原始对象或早期代理)。
- singletonFactories(三级缓存)——保存一个
ObjectFactory,当需要早期引用时可以调用它得到(常用于创建代理对象,支持 AOP 情况)。
- 简要流程(创建 bean A):
- 实例化 A(还没注入属性)。把 A 的
ObjectFactory放入singletonFactories(使别人能拿到早期引用)。 - 当创建 B 时需要 A,会先从
singletonObjects看不到,再从earlySingletonObjects/singletonFactories找到早期引用并加入earlySingletonObjects。 - B 的注入完成后返回,A 完成属性注入、执行后置处理器,最后把 A 放入
singletonObjects,并从早期缓存移除。
- 实例化 A(还没注入属性)。把 A 的
- 限制 & 注意:
- 只能解决单例且非构造器注入的循环依赖;构造器注入需要构造函数就得到依赖,无法提前暴露,故会抛异常。
- AOP 代理会影响:默认如果需要代理,Spring 会在
singletonFactories存入创建代理的工厂,这样早期引用能得到代理,避免后续再创建新的代理导致不一致。 - Prototype scope(原型)不支持自动解决循环依赖。
12. Spring Security 是什么?
- Spring Security 是一个提供认证(Authentication)与授权/访问控制(Authorization)的企业级安全框架,功能包括:登录/登出、权限控制、方法级安全、会话管理、CSRF 防护、加密密码、集成 OAuth2 / OIDC / SSO 等。
- 主要组件:
SecurityFilterChain(一系列 Filter 拦截与安全处理)、AuthenticationManager、UserDetailsService(加载用户信息)、GrantedAuthority(权限)、密码编码器(如BCryptPasswordEncoder)、MethodSecurity(@Secured、@PreAuthorize)等。 - 集成点:与 Spring MVC / WebFlux 无缝集成,常用配置有基于 DSL 的 Java Config(Spring Security 5+ 风格)以及注解式方法安全。
13. Spring、Spring MVC、Spring Boot 三者之间的关系
- Spring Framework:底层核心框架,提供 IoC(依赖注入)、AOP、事务管理、数据访问支持等基础功能。
- Spring MVC:Spring 的一个模块(web 框架),实现 MVC 模式,基于 Spring 的 IoC/AOP 运行,负责处理 HTTP 请求、分发到 Controller、渲染视图等。
- Spring Boot:基于 Spring 的约定优于配置(opinionated)框架,简化 Spring 应用的配置与启动(starter 依赖、自动配置、嵌入式容器、Actuator 等)。它不是替代 Spring,而是简化使用 Spring(及 Spring MVC、Spring Data、Spring Security 等生态)的方式。
简单:Spring = 基础,Spring MVC = Web 模块,Spring Boot = 用来快速启动/配置 Spring 应用的工具集与约定。
14. Spring Boot 自动配置原理(原理概述)
- 核心:
@EnableAutoConfiguration(隐含在@SpringBootApplication)通过AutoConfigurationImportSelector导入大量候选自动配置类。 - 自动配置类通常放在
org.springframework.boot.autoconfigure.*,并带有条件注解(@ConditionalOnClass、@ConditionalOnMissingBean、@ConditionalOnProperty等)来决定是否生效。 - 自动配置候选的来源:传统上通过
META-INF/spring.factories列表来发现(Spring Boot 2.x 常用),较新的 Boot 版本引入了更现代的自动配置注册机制(也使用 metadata 文件来列出 auto-config 类)。无论机制如何,核心思想是:按需注册、并允许用户通过spring.autoconfigure.exclude或@SpringBootApplication(exclude=...)覆盖/排除。 - 覆盖顺序:用户显式定义的
@Bean通常优先于自动配置;自动配置通过条件注解判断是否装配。 - 常用条件注解举例:
@ConditionalOnClass(类在类路径中时生效)、@ConditionalOnMissingBean(当容器中没有某 bean 时生效)、@ConditionalOnProperty(基于配置属性启用/禁用)。
提示:自动配置是“约定优于配置”的实现:在默认配置无法满足时,用户可通过自定义配置/排除来自定义行为。
15. Spring Cloud 的组件有哪些?(常见模块与作用)
Spring Cloud 是一套构建分布式系统的工具集合,包含很多子项目。常见模块(并非全部):
- Spring Cloud Config:集中式配置管理(server + client)。
- Spring Cloud Netflix(整合 Netflix OSS):Eureka(服务发现)、Ribbon(客户端负载均衡,已在新版本逐步被
Spring Cloud LoadBalancer取代)、Hystrix(断路器,已进入维护/弃用,替代方案Resilience4j)。 - Spring Cloud Gateway:API 网关/路由。
- OpenFeign / Spring Cloud OpenFeign:声明式 HTTP 客户端。
- Spring Cloud LoadBalancer:客户端负载均衡(替代 Ribbon)。
- Spring Cloud CircuitBreaker:抽象断路器,支持 Resilience4j 等实现。
- Spring Cloud Stream:事件/消息驱动(Kafka/RabbitMQ 绑定)。
- Spring Cloud Bus:消息总线(广播配置刷新等)。
- Spring Cloud Sleuth / Zipkin / Micrometer:分布式追踪与监控。
- Spring Cloud Gateway / Zuul(老):API 路由/网关实现。
- Spring Cloud Contract:契约测试。
- Spring Cloud Kubernetes / Consul / Zookeeper:与 k8s、Consul、ZK 的整合。
注:Spring Cloud 生态很大,不同版本间有替代与弃用(例如 Ribbon -> LoadBalancer,Hystrix 逐步被 Resilience4j 取代),实际项目中按需要选用。
16. 在 REQUIRES_NEW 场景下,子事务同时操作同一数据会发生什么?
这是一个非常实战且需要深入理解数据库事务模型与 Spring 事务传播差异的问题。下面分几部分说明:实现细节、并发与隔离语义、可能的异常/问题、解决方案/最佳实践。
(A)REQUIRES_NEW 的行为(实现层面)
REQUIRES_NEW会 挂起 当前(外层)事务,然后在一个 独立的事务 中执行子事务。实现上(本地事务)通常意味着:挂起外层事务的连接/事务状态,取得新的数据库连接(或从连接池取出),在该连接上开启新的事务;子事务完成后提交/回滚并关闭该连接,然后恢复外层事务继续执行(用原来的连接与事务)。- 结果:子事务的提交或回滚 与外层事务相互独立(子事务已提交后,即使外层后续回滚,也无法回滚子事务)。
(B)若子事务和外层/另一个子事务“同时”操作同一数据,会发生什么?
行为由 数据库隔离级别、锁机制(悲观锁 / 行级锁)、以及操作顺序决定。常见情况:
- 子事务在另一个事务之后提交(顺序不同)
- 若两个事务更新同一行,数据库会对行加锁(具体行为依 DB 引擎)。例如 InnoDB(MySQL)执行
UPDATE会加行锁。第二个事务会在尝试修改时等待第一个事务释放锁(或触发死锁检测)。最终一个事务会被回滚(DB 检测到死锁)或等待成功后提交。Spring 会把底层 SQLException 转为DataAccessException抛出,事务会相应回滚或提交。
- 若两个事务更新同一行,数据库会对行加锁(具体行为依 DB 引擎)。例如 InnoDB(MySQL)执行
- 并发读写 + 隔离级别影响(READ_COMMITTED vs REPEATABLE_READ)
- READ_COMMITTED:每条语句看到的是已提交的数据;如果子事务提交后,外层事务在挂起后恢复并重新读取,会看到子事务的修改。
- REPEATABLE_READ(MySQL 默认):事务开始时建立读快照;在外层事务尚未提交且使用 REPEATABLE_READ 时,外层事务可能不会看到子事务提交的更改,直到外层事务结束并重新开始事务。
- 因此:数据可见性取决隔离级别与何时读取。
- 丢失更新(Lost Update)
- 场景:T1(外层)读到值
v→ 执行 REQUIRES_NEW 的子事务 T2 更新为v2并提交 → T1 继续基于旧v计算并写回 → 如果没有版本控制/锁机制,会覆盖 T2 的更新(丢失更新)。
- 场景:T1(外层)读到值
- 悲观锁 / 乐观锁的影响
- 悲观锁(SELECT … FOR UPDATE):可以避免并发写冲突(会阻塞直到锁释放)。
- 乐观锁(version 字段):写时检查版本号,不匹配则抛出
OptimisticLockingFailureException,开发者可捕获重试以解决冲突。
(C)与 NESTED 的对比(重要)
NESTED在多数实现下使用 同一物理连接 + savepoint 实现:子事务回滚只是回到 savepoint,不会独立提交。REQUIRES_NEW是独立事务并提交后不可撤销。- 因此:若想实现“子事务失败不影响外层”且不希望子事务独立提交,
NESTED比REQUIRES_NEW更合适(但需 DB & 事务管理器支持)。
(D)JPA/Hibernate 细节(ORM 层的问题)
- 使用 JPA/Hibernate 时,
REQUIRES_NEW会创建新的EntityManager/ persistence context。外层事务的持久化上下文(1st-level cache)在恢复后仍保留旧实体的状态(可能是陈旧的)。因此:外层事务需要entityManager.refresh(entity)或entityManager.clear()来看到子事务的修改,否则可能基于陈旧实体写回,导致覆盖或冲突。 - 注意:
REQUIRES_NEW额外创建连接/实体管理器,开销较大,且更容易产生并发冲突需要手工处理。
(E)示例场景(伪代码,说明丢失更新):
1 | // 外层事务 T1 |
结论:若不处理,可能出现覆盖/丢失更新或不可预期的数据一致性问题。
(F)数据库级别的异常(死锁、序列化失败等)
- 并发更新同一资源可引发死锁,DB 会回滚其中一个事务并抛出异常(例如 MySQL 的死锁错误)。Spring 捕获后会抛出 DataAccessException 或其子类,事务回滚。需要在调用方处理(重试或降级)。
- 在更严格隔离(
SERIALIZABLE)下可能出现序列化异常,也需要重试逻辑。
(G)最佳实践与建议
- 明确事务边界:不要随意大量使用
REQUIRES_NEW,它会增加连接数和复杂度。只在确实需要“子事务独立提交”的场景使用(如写审计日志、发送外部不可回滚的操作)。 - 避免丢失更新:对重要并发更新场景使用**乐观锁(version)**或**悲观锁(SELECT … FOR UPDATE)**。
- 在 JPA 场景谨慎处理 Persistence Context:
REQUIRES_NEW后如果外层要使用被子事务修改的实体,记得refresh()或clear(),以避免使用 stale entity。 - NESTED vs REQUIRES_NEW:如果想在同一物理事务里局部回滚用 NESTED(savepoint),想要真正独立提交用 REQUIRES_NEW。
- 处理异常与重试:对可能的死锁/序列化冲突做重试策略(指数退避等)。Spring 的
@Transactional不会自动重试,需自己实现。 - 监控与容量注意:
REQUIRES_NEW增加并发连接数,注意数据库连接池容量。
小结(关于第16题的实战提醒)
REQUIRES_NEW会产生独立事务并独立提交。若外层/其他事务同时对同一数据修改,最终行为取决于 DB 的锁与隔离级别:会有等待、死锁、丢失更新或序列化冲突等情况。- 解决思路:用乐观锁/悲观锁、合理选择传播行为(NESTED vs REQUIRES_NEW)、在 ORM 场景刷新/清理持久化上下文、并实现重试策略与良好的异常处理。
Java基础-牛客面经八股
1 Java 基本数据类型与引用类型
1. 基本类型(Primitive Types, 8 种)
- 类型:
byte(1B)、short(2B)、int(4B)、long(8B)、float(4B)、double(8B)、char(2B, UTF-16 code unit)、boolean(大小未在 JVM 规范中强制规定,通常用 1 bit/1 byte 存储)。 - 存放位置:
- 方法里的局部变量 → JVM 栈帧的局部变量表(直接存值)。
- 如果是对象的字段 → 存在 堆内存的对象布局中(对象头 + 实例字段 + 对齐填充)。
- 优点:
- 直接值语义,没有引用开销。
- 不参与 GC,性能高。
- 内存占用小。
- 缺点:
- 不能为
null。 - 不具备面向对象特性(没有方法)。
- 不能为
2. 引用类型(Reference Types)
- 类型:类、接口、数组、枚举、注解。
- 存放方式:
- 引用变量 存在栈或对象字段中,存储的是对象在堆上的地址(引用)。
- 对象本体 存在堆中(对象头 + 实例数据 + 对齐)。
- 特点:
- 可以为
null。 - 传递时是 值传递,但值是引用的拷贝(可能导致“看起来像引用传递”)。
- 需要 GC 管理生命周期。
- 可以为
3. 内存结构对比
- 基本类型字段:直接存值,结构紧凑。
- 包装类型(如
Integer):对象有对象头(MarkWord + Klass 指针)+ 实例数据(int 值)+ 对齐填充。内存占用比基本类型大得多(通常至少 16B+)。 - 布尔类型:虽然语义是 true/false,但在对象中至少占 1B(HotSpot 会优化压缩到 bitset,但不保证)。
Q1. 为什么 Java 有基本类型而不是全部用对象?
👉 回答要点:
- 性能考虑。
- 基本类型避免了对象包装的额外开销(对象头、GC、指针寻址)。
- 在高频计算(循环、数值运算)中,大量创建对象会显著拖慢性能。
Q2. 基本类型和包装类型的区别?
👉 回答要点:
- 基本类型直接存值,包装类型是对象(有引用开销)。
- 包装类型可以为
null,而基本类型不行。 - 包装类型支持方法(如
Integer.valueOf、compareTo)。 - 自动装箱/拆箱可能引发性能问题。
- 比较时:
- 基本类型用
==比较值。 - 包装类型
==比较引用(除非在 [-128,127] 缓存范围内的整型)。
- 基本类型用
Q3. 为什么 Integer i1 = 127; Integer i2 = 127; i1 == i2 返回 true,而换成 128 返回 false?
👉 回答要点:
- 因为 Java 对
Integer做了缓存(IntegerCache,默认缓存 -128 ~ 127)。 - 超出范围会创建新的对象。
Q4. 对象在堆中的内存布局是怎样的?
👉 回答要点:
- 对象头:
- Mark Word(哈希码、锁信息、GC 信息)。
- Klass Pointer(指向类元数据)。
- 实例数据:成员变量。
- 对齐填充:保证 8 字节对齐。
Q5. 为什么建议用不可变对象(String, Integer, Long 等)作为共享数据?
👉 回答要点:
- 不可变 → 线程安全,不需要额外同步。
- 可作为 Map 的 key(不会被修改导致 hashCode 变化)。
- 方便缓存(如 String Pool)。
Q6. 什么时候用基本类型,什么时候用包装类型?
👉 回答要点:
- 优先用基本类型 → 性能敏感场景(循环计数器、数值计算)。
- 必须用包装类型 →
- 需要使用泛型(
List<Integer>)。 - 需要为
null表示缺省值。 - 需要调用包装类的方法。
- 需要使用泛型(
Q7. 为什么 boolean 大小未定义?JVM 实际是怎么处理的?
👉 回答要点:
- JVM 规范只定义了 boolean 的语义,没有强制大小。
- 实际实现:
- 在数组中,boolean 常按 byte 存储。
- 在对象字段中,HotSpot 常把 boolean 当成 1B,但可能和其他字段合并压缩(bitfield)。
🔹 面试小结
- 基本类型 → 性能好,存值,不可为 null。
- 引用类型 → 面向对象特性,存引用,需 GC 管理。
- 面试重点:装箱拆箱、缓存机制、对象内存布局、堆 vs 栈、不可变对象的好处。
🔹 栈(Stack)
- 定义:线程私有,每个线程启动时会创建一个栈,生命周期和线程相同。
- 存放内容:
- 局部变量(基本类型的值 / 引用变量的引用值)。
- 方法调用信息(局部变量表、操作数栈、动态链接、返回地址)。
- 特点:
- 内存小但访问快(栈帧出栈后,内存直接复用)。
- 线程隔离,不需要同步 → 天然线程安全。
- 方法调用结束 → 栈帧自动销毁,无需 GC。
- 错误场景:
- 递归过深或方法调用层次过多,会导致 StackOverflowError。
🔹 堆(Heap)
- 定义:Java 内存最大的一块,所有线程共享。
- 存放内容:
- 对象实例(无论是成员变量还是数组)。
- 对象的实例数据(字段)。
- 特点:
- 所有线程共享,需要 GC 来管理生命周期。
- 内存分配比栈复杂(对象需要内存分配、布局、回收)。
- 大小可配置(
-Xmx/-Xms)。
- 错误场景:
- 堆不足时 → OutOfMemoryError: Java heap space。
🔹 对比总结
| 对比点 | 栈 | 堆 |
|---|---|---|
| 管理 | 方法调用自动分配/销毁 | JVM GC 管理 |
| 存储内容 | 基本类型的值、引用的地址 | 对象实例、成员变量 |
| 线程安全 | 线程私有,安全 | 线程共享,需同步 |
| 生命周期 | 方法结束自动销毁 | 对象被 GC 回收 |
| 错误 | StackOverflowError |
OutOfMemoryError |
🔹 常见面试追问
Q1. Java 中的变量存放在堆还是栈?
👉 回答要点:
- 基本类型的局部变量 → 存在栈里。
- 引用变量(如
Person p) → 引用存在栈里,实际对象在堆里。 - 对象字段(即使是基本类型) → 随着对象存放在堆里。
Q2. 为什么栈比堆快?
👉 回答要点:
- 栈是顺序内存结构,分配/释放只移动栈顶指针 → O(1)。
- 堆分配需要找合适的内存块,还要涉及 GC,成本高。
Q3. 栈里能存对象吗?
👉 回答要点:
- 严格来说,对象实例只能在堆中存。
- 栈里只能存对象引用(指向堆)。
- 但 JVM 的 JIT 优化可能会做逃逸分析,把未逃出方法的对象分配到栈上(Stack Allocation),甚至标量替换 → 提高性能。
Q4. 为什么要有堆和栈的区分?
👉 回答要点:
- 栈 → 方法调用和局部变量,高效且线程私有。
- 堆 → 对象共享,生命周期不固定,只能靠 GC。
- 各自职责清晰,才能兼顾性能和灵活性。
Q5. GC 只回收堆吗?
👉 回答要点:
- 对,GC 主要回收堆内存。
- 栈内存是随着方法出栈自动释放的,不需要 GC。
🔹 面试快速答题版
- 栈:线程私有,存局部变量和方法调用信息,生命周期随方法,速度快但空间小,异常
StackOverflowError。 - 堆:线程共享,存对象实例,由 GC 管理,灵活但慢,异常
OutOfMemoryError。
2 抽象类 vs 接口
- 抽象类(abstract class):
- 可以包含字段、构造器、具体方法和抽象方法。
- 适用于“is-a”关系且需要共享状态或实现细节的场景。
- 单继承:类只能继承一个抽象类。
- 接口(interface):
- Java 8+ 支持
default方法、static方法;Java 9+ 支持私有方法。接口不能有实例字段(只允许public static final常量)。 - 支持多重实现(类可以实现多个接口),适合行为声明。
- Java 8+ 支持
- 语义区别:抽象类关心“什么是”,接口关心“能做什么”。
- 版本注意:由于
default方法,接口现在可以携带实现,这使得“接口演进”更容易(兼容旧实现)。
面试要点:选择抽象类还是接口的理由;接口的多继承与菱形继承问题如何解决(Java 接口方法冲突规则)。
🔹 抽象类 vs 接口:如何选择?
1. 抽象类的特点
- 可以有 成员变量(实例变量、静态变量)、构造器(但不能直接实例化)。
- 可以有 方法实现(非抽象方法)。
- 可以提供 状态 + 行为 的部分实现。
- 类只能继承一个父类 → 抽象类适合类层次结构的扩展。
👉 适用场景:
- 表达 “is-a” 关系,且有 代码复用需求。
- 子类共享一些公共逻辑,但仍需要抽象定义。
- 比如
AbstractList、HttpServlet。
2. 接口的特点
- 从 Java 8 开始,可以有 default 方法 和 static 方法(Java 9 引入 private 方法)。
- 不能有实例变量(只能有常量
public static final)。 - 用于定义 规范 / 能力(行为约定),没有状态。
- 一个类可以实现多个接口 → 更灵活。
👉 适用场景:
- 表达 “can-do” 能力,不关心类的层次结构。
- 用于跨模块、跨层的解耦(如
Serializable、Comparable、Runnable)。 - 适合 API 设计,定义一组必须实现的功能。
3. 选择准则
- 优先接口:如果只需定义行为,且希望解耦。
- 抽象类:如果需要 共享状态 或 部分实现。
- 接口 + default 方法:适合工具性扩展,不破坏已有实现。
- 抽象类 + 模板方法模式:需要控制子类实现的调用顺序。
🔹 接口的多继承 & 菱形继承问题
1. 什么是菱形继承?
比如:
1 | interface A { |
这里 D 同时继承了 B 和 C,它们都从 A 继承了 hello,并且覆盖了。
问题:D 调用 hello() 时,调用哪个?
Java 编译规则:
- 类优先 → 这里
D自己没写,父类也没有,所以走不到。 - 子接口更具体 → 但
B和C是并列接口,没有继承关系,无法判断谁更具体。 - 必须显示覆盖 → 由于有二义性,编译器直接报错,强制
D必须自己实现hello()。
2. Java 的规则(接口方法冲突解决)
Java 避免了 C++ 的“菱形继承”困境,规则如下:
- 类优先原则:
- 如果类和接口中有同名方法,优先使用类中的方法。
- 即 类 > 接口 default 方法。
- 更具体接口优先原则:
- 如果多个接口中有冲突的 default 方法,选择继承路径更“具体”的接口。
- 例:如果
B extends A,C extends A,类实现B, C→ 优先B或C的覆盖方法。
- 必须显式覆盖(冲突无法自动解决时):
- 如果继承了多个接口,且 default 方法签名冲突,必须在实现类里 显式 override。
- 可以用
X.super.method()调用指定接口的默认实现。
3. 例子:解决冲突
1 | class D implements B, C { |
🔹 面试快速答题版
- 抽象类 vs 接口:
- 抽象类:有状态(字段)、有构造器、适合类层次结构,子类共享逻辑。
- 接口:定义行为规范,无状态,可多继承,解耦性更强。
- 一般 优先接口,当需要共享实现时用抽象类。
- 接口多继承的菱形问题:
- Java 通过 明确规则避免了 C++ 菱形继承的歧义:
- 类优先于接口。
- 更具体的接口优先。
- 冲突时必须在实现类显式覆盖,并可用
X.super.method()调用。
- Java 通过 明确规则避免了 C++ 菱形继承的歧义:
3 final 关键字
- final 类:不能被继承(确保行为不可扩展/被覆盖)。
- final 方法:不能被重写(用于安全或性能提示)。
- final 变量:
- 局部 final:必须在声明或构造器/初始化块中初始化一次;在 lambda/匿名内部类中要求变量为“effectively final”。
- 成员 final(字段):在构造器中赋值后不可修改;对引用类型,final 限制的是引用不可改变,但对象状态仍可变。
- JMM 中的 final 字段语义:final 字段有特殊的内存可见性保证:构造器中写入 final 字段并且对象正确发布后,其他线程能看到正确的 final 字段值(比普通字段更强)。但安全发布仍需注意(不要在构造器中把
this逸出)。
面试点:final 与线程安全、final 与常量折叠(compile-time constant)、final 与继承/多态影响。
很好 👌 你已经把 final 的核心点 梳理得很完整了,我帮你再补充一些 细节 + 面试可能的追问点,这样遇到深挖问题也能答得很漂亮。
final 关键字总结
1. final 类
- 含义:不能被继承(例如
String,Integer,Math)。 - 设计原因:
- 确保安全性(防止子类破坏不可变性,比如
String)。 - JVM 优化(JIT 能更大胆做内联/优化,因为知道不会被 override)。
- 确保安全性(防止子类破坏不可变性,比如
- 面试追问:
- Q: 为什么
String是final?- A: 保证不可变,避免哈希缓存、字符串池等被破坏,提升线程安全。
- Q: 为什么
2. final 方法
- 含义:不能被重写(但可以被重载)。
- 用途:
- 确保某些方法的逻辑不会被子类篡改(模板方法模式常用)。
- JVM 可做早期绑定(non-virtual call),提升性能。
- 面试追问:
- Q:
private方法能否是final?- A: 可以,但没有意义,因为
private方法本来就不能被重写。
- A: 可以,但没有意义,因为
- Q:
3. final 变量
3.1 局部变量
- 必须初始化一次,之后不能改。
- lambda & 匿名类:要求变量是 effectively final(未被重新赋值即可)。
- 目的是保证闭包捕获的变量一致性。
3.2 成员变量(字段)
final字段要么在声明时初始化,要么在构造函数/初始化块中赋值。对引用类型:引用本身不能修改,但对象内容可变(浅不可变)。
1
2
3final List<String> list = new ArrayList<>();
list.add("x"); // ✅ 可行
list = new ArrayList<>(); // ❌ 不行
3.3 常量折叠
final static基本类型 +String常量 → 编译期常量,会在编译时内联。1
2public static final int A = 42;
System.out.println(A); // 编译时就替换成 42面试追问:
- Q: 如果修改了常量定义,是否需要重新编译依赖的类?
- A: 需要,否则依赖类还用旧值(因为常量折叠到字节码里)。
- Q: 如果修改了常量定义,是否需要重新编译依赖的类?
4. JMM 中的 final 语义
- 特殊内存语义:
- 构造器中对
final字段的写入,对其他线程是安全可见的(只要对象正确发布)。 - 与普通字段不同,普通字段可能出现“半初始化可见”。
- 构造器中对
- 注意点:
- 不能在构造函数中把
this逃逸(比如把自己注册到全局 map),否则final语义失效。
- 不能在构造函数中把
- 面试追问:
- Q:
final字段能完全保证不可变对象的线程安全性吗?- A: 如果对象状态完全由
final字段决定,并且没有泄漏this,是安全的。
- A: 如果对象状态完全由
- Q:
✅ 面试常见追问 + 答法
final和finally、finalize的区别?final:修饰符finally:异常处理中的保证块finalize():对象回收前调用的方法(已过时,不建议用)
final与不可变类的关系?final字段是不可变类的基础;不可变类通常要求:类是final,字段是final,且没有setter。
- 为什么 Java 要有
final字段的内存模型特殊语义?- 确保不可变对象真正安全(如
String、Integer),避免指令重排导致读到未初始化值。
- 确保不可变对象真正安全(如
4 static 关键字
- static 变量(类变量):类加载时初始化,所有实例共享。
- static 方法:与实例无关,不能直接访问非静态成员(因为没有 this)。静态方法在子类中被“隐藏”,不是多态(不能被 override,只能被子类定义同名静态方法,调用根据编译时类型)。
- static 块:类加载时执行(用于初始化复杂静态资源)。
- 静态方法能否调用非静态成员? 不能直接调用。若需要,必须先获得某个实例并通过该实例访问非静态成员。
- static synchronized:锁的是 Class 对象(
MyClass.class),而非实例。
面试点:类加载时机(静态初始化顺序)、类初始化与双亲委派、静态成员与内存泄漏(大量静态缓存)、静态方法隐藏 vs 实例方法重写。
static 关键字详解
1. static 变量(类变量)
- 生命周期:类加载时分配,JVM 在方法区(JDK8 之后是 元空间 + 堆里的静态区)为类变量分配内存。
- 共享性:所有实例共享同一份内存。
- 初始化顺序:
- 静态变量 & 静态块 → 按源码顺序依次执行。
- 在类初始化阶段完成。
- 面试追问:
- Q: 静态变量存放在哪里?
- JDK7 之前:方法区(永久代)。
- JDK8 之后:方法区 → 元空间,引用存放在元空间,实际对象可能在堆上。
- Q: 静态变量存放在哪里?
2. static 方法
特性:
- 属于类本身(Class),不依赖对象。
- 不能访问实例成员(没有
this)。 - 静态方法在子类中不会覆盖父类的静态方法,而是隐藏(Static Hiding)。
多态性区别:
1
2
3
4
5class A { static void hi() { System.out.println("A"); } }
class B extends A { static void hi() { System.out.println("B"); } }
A a = new B();
a.hi(); // 输出 A(静态绑定,取决于引用类型)面试追问:
- Q: 静态方法能否被重写?
- A: 不能,静态方法是类级别的,不走虚方法表,不具备运行时多态。
- Q: 静态方法能否被重写?
3. static 代码块
- 执行时机:类初始化时(类加载 → 验证 → 准备 → 解析 → 初始化)。
- 顺序:
- 父类静态代码块 → 子类静态代码块 → 父类构造块/构造器 → 子类构造块/构造器。
- 用途:
- 初始化复杂静态变量(如
Map、Set)。 - 加载 native 库。
- 初始化复杂静态变量(如
4. static synchronized
- 含义:锁住
Class对象。 - 区别:
synchronized实例方法 → 锁住当前对象实例 (this)。static synchronized方法 → 锁住当前类的Class对象。
- 面试追问:
- Q: 两个线程调用同一对象的实例方法(synchronized)和类方法(static synchronized),会互斥吗?
- A: 不会。因为前者锁的是实例对象,后者锁的是
Class对象。
- A: 不会。因为前者锁的是实例对象,后者锁的是
- Q: 两个线程调用同一对象的实例方法(synchronized)和类方法(static synchronized),会互斥吗?
⚡ 常见面试陷阱
❌ 1. 静态成员与内存泄漏
- 若静态变量持有对象引用(尤其是集合、缓存),会导致对象无法被 GC 回收,造成 类加载器泄漏。
- 常见于 Web 容器(Tomcat)反复部署应用。
❌ 2. 静态方法调用实例方法
1 | class Test { |
👉 必须通过实例来调用:
1 | Test t = new Test(); |
❌ 3. 静态内部类与非静态内部类
- 静态内部类:不依赖外部类实例,可以直接创建
new Outer.Inner() - 非静态内部类:需要外部类实例
new Outer().new Inner()
✅ 高频面试追问
- static 方法能否访问 this?
- 不能,因为静态方法属于类,没有 this 指针。
- 类什么时候被加载和初始化?
- 使用到静态变量/静态方法时;
- new 对象时;
- 反射调用时;
- 主类(包含
main)被启动时。
- 静态方法能否被重写?为什么?
- 不能。静态方法编译期绑定,属于类,不属于对象。子类的同名静态方法只是隐藏父类方法。
- 静态变量是否线程安全?
- 取决于是否被并发修改。
static本身只保证共享,不保证安全,仍需同步控制。
- 取决于是否被并发修改。
5 String / StringBuffer / StringBuilder
- String:
- 不可变(immutable)。任何修改都会产生新对象。好处:线程安全、可作为 Map/Set 的 key、可安全缓存(字符串常量池 intern)。
- Java 9 后内部表征从
char[]变为byte[] + coder(节省内存)。 String.intern():将字符串放到常量池,可能影响 permgen/metaspace 使用。
- StringBuffer:
- 可变字符序列,线程安全(方法使用
synchronized)。适合多线程频繁修改单一实例的场景(但通常用得少)。
- 可变字符序列,线程安全(方法使用
- StringBuilder:
- 可变字符序列,非线程安全,性能优于
StringBuffer(适合大多数单线程场景,如拼接循环中的字符串构造)。
- 可变字符序列,非线程安全,性能优于
- 容量增长:
StringBuilder的扩容策略通常为newCapacity = (oldCapacity << 1) + 2(约 2x),不同 JDK 版本细节稍有差异。
- 性能建议:大量拼接用
StringBuilder;若作为 HashMap key,用不可变String。
面试点:为什么 String 可作为 Map key(不可变性保证 hashCode 不变)、String 常量池与内存、拼接在循环里使用 + 的问题(导致大量临时 String)。
1. 为什么 String 可以作为 Map 的 key?
HashMap的 key 依赖hashCode()和equals()。- 如果 key 可变,放入后修改会导致:
- hashCode 改变 → 无法找到原来的 bucket。
- equals 改变 → 逻辑错误。
👉 String 是 不可变对象:
hashCode在第一次计算后会缓存(lazy 计算,存在hash字段里)。- 因为内容不变,hashCode 永远一致,保证放入 Map 后可以稳定检索。
equals比较基于内容,逻辑也稳定。
💡 面试点延伸:
- 为什么
String、Integer、Long等不可变对象经常作为Mapkey?
👉 因为不可变性保证了哈希一致性。
2. String 常量池与内存
字符串常量池(String Pool):
- 存放编译期确定的字面量和运行时调用
intern()的字符串。 - 在 JDK 6 以前,常量池在 永久代 (PermGen);JDK 7+ 移到 堆;JDK 8+ 完全在堆中。
- 存放编译期确定的字面量和运行时调用
工作原理:
1
2
3String s1 = "abc"; // 放入常量池
String s2 = "abc"; // 直接引用池中的同一个对象
String s3 = new String("abc"); // 在堆中创建新对象,不会自动放入池intern() 方法:
1
2String s4 = new String("abc").intern();
System.out.println(s1 == s4); // true,引用池对象
👉 好处:
- 节省内存(相同字面量只存一份)。
- 提高比较性能(字符串常量池对象可以直接用
==判断)。
3. 循环中使用 + 拼接字符串的问题
String是不可变的,每次拼接都会生成 新的对象:1
2
3
4String s = "";
for (int i = 0; i < 1000; i++) {
s = s + i; // 每次拼接都 new 一个新的 String
}内部相当于:
1
s = new StringBuilder(s).append(i).toString();
导致创建 大量临时对象,性能极差(O(n²))。
正确写法:使用
StringBuilder或StringBuffer:1
2
3
4
5StringBuilder sb = new StringBuilder();
for (int i = 0; i < 1000; i++) {
sb.append(i);
}
String s = sb.toString();
💡 面试官可能会追问:
- 为什么
"a" + "b" + "c"没问题?
👉 编译器优化,常量折叠成"abc",不会产生额外对象。 - 为什么循环里不优化?
👉 循环次数不确定,编译器无法提前合并。
4. 面试高频追问
- 为什么
String设计成不可变?- 安全性(避免泄露,例如 JDBC URL、ClassLoader 字符串)。
- 线程安全(不可变对象天然线程安全)。
- 常量池优化(相同字面量可复用)。
- 作为 HashMap key 的稳定性。
- intern() 会造成内存泄漏吗?
- JDK 6:常量池在永久代,
intern()多了可能 OOM。 - JDK 7+:移到堆中,和 GC 一起回收,不会永久泄漏。
- JDK 6:常量池在永久代,
- StringBuilder vs StringBuffer?
StringBuilder:非线程安全,单线程高性能。StringBuffer:线程安全(方法有synchronized),适合多线程环境。
✅ 简答版(面试 1 分钟答法):
String作为 Map key:不可变性保证 hashCode 和 equals 一致性。- 常量池:字符串字面量和 intern() 存在池中,节省内存,提升性能。
- 循环拼接:
+会创建大量临时对象,应使用StringBuilder。
6 == 与 equals()
- ==:
- 基本类型:比较值。
- 引用类型:比较引用地址(是否同一对象)。
- equals():
Object.equals()默认是==(引用相等)。很多类(如String、集合类、包装类)重写了equals()比较语义上的“等价性”。
- 常见陷阱:
Integer a = 127; Integer b = 127; a == b // true(因为 JVM 缓存 -128~127 范围的 Integer.valueOf);Integer x = 128; Integer y = 128; x == y // false。new String("x") == "x"为false(不同对象),但new String("x").intern() == "x"为true。
面试点:何时用 equals(内容比较),何时用 ==(引用比较);实现 equals 时遵守对称性、传递性、反射性、稳定性。
1. ==:比较引用/基本类型值
1.1 基本类型
1 | int a = 5, b = 5; |
- 对于 基本类型,
==比较的是 实际存储的值。
1.2 引用类型
1 | String s1 = new String("abc"); |
- 对于 对象引用,
==比较的是 是否指向同一内存地址(即是否同一个对象)。 - 面试常考点:
- 常量池里的字面量
String s3 = "abc"; String s4 = "abc";→s3 == s4为true(引用相同)。 new String("abc")每次创建新对象 → 引用不同。
- 常量池里的字面量
2. equals():比较内容
- 定义在
Object中:
1 | public boolean equals(Object obj) { |
- 但大多数类(如
String,Integer,List)都会重写equals(),比较对象的逻辑内容而不是引用。
1 | String s1 = new String("abc"); |
3. 使用准则
| 场景 | 使用方式 | 原因 |
|---|---|---|
| 基本类型 | == |
比较值 |
| 对象引用是否同一对象 | == |
比较内存地址 |
| 对象内容是否相同 | equals() |
比较逻辑内容,需要类正确重写 equals() |
| 容器/Map key 比较 | equals() |
Map/Set 查找时根据 equals() 决定逻辑相等 |
4. 常见面试陷阱
- String 比较:
1 | String a = "abc"; |
- 包装类比较(Integer、Long):
1 | Integer i1 = 127, i2 = 127; |
- 自定义类未重写 equals():
1 | class Person { String name; } |
- 面试点:自定义类使用内容比较需要 重写 equals()(同时重写 hashCode())。
5. 面试快捷答法
==:- 基本类型 → 值比较
- 引用类型 → 地址比较(同一个对象吗)
equals():- 内容比较(逻辑相等),前提类重写了 equals()
- 容器/Map 使用
equals()判断元素或 key 是否相等
💡 延伸小技巧:
- 写
a.equals(b)前最好检查a != null,或者用Objects.equals(a, b)防止 NullPointerException。
7 hashCode() 与 equals()
合同:
- 如果两个对象
equals()返回true,那么它们的hashCode()必须相等。 - 如果
equals()返回false,hashCode()可以相等也可以不同(哈希冲突允许)。 hashCode()在一次应用运行中应该保持稳定(对象没有修改时)。
- 如果两个对象
为什么必须重写 hashCode?
- Hash 系数据结构(
HashMap/HashSet)使用hashCode()先定位桶,再用equals()检查具体相等性。若只重写equals()而不重写hashCode(),两个逻辑相等对象可能具有不同哈希,导致放入 HashSet 后无法找到或产生重复键。
- Hash 系数据结构(
实现建议:用不可变字段计算 hash,常用
Objects.hash(...)或 IDE 生成;避免使用容易改变的字段(会导致键失效)。示例坑:
1
2
3
4
5
6class Person {
String name;
int age;
public boolean equals(Object o) { ... } // 基于 name、age
// 忘了重写 hashCode -> 在 HashSet/HashMap 中会出现问题
}
面试点:Mutable key 的危害(例如使用可变字段做 HashMap key,然后修改字段),如何设计正确的 hashCode(均匀分布、避免碰撞)。
8 包装类的自动装箱/拆箱
- 装箱(boxing):基本类型 → 对应包装类(编译器插入
Integer.valueOf(int)等)。 - 拆箱(unboxing):包装类 → 基本类型(编译器插入
intValue()等)。 - 缓存:
Integer.valueOf缓存-128 ~ 127,Boolean.valueOf缓存true/false。Long也缓存某些小值;其他包装类行为取决实现。 - 风险:
NullPointerException:Integer a = null; int b = a; // NPE。- 性能损失:频繁装拆箱会产生对象分配和 GC 压力。
==在装箱时比较的是引用(可能受缓存影响)。
- 编译例子:
Integer a = 10; int b = a + 5;→ 编译器生成int b = a.intValue() + 5;。
面试点:注意 NPE、缓存范围、避免在性能敏感路径频繁装拆箱(比如大循环中),使用原始类型或专用库(Trove、fastutil)在高性能场景下替代。
9 重载(Overload) vs 重写(Override)
- 重载(同一类或子类中):
- 同名方法,参数列表不同(参数数/类型/顺序),返回类型可不同(但仅返回类型不同不能构成重载)。
- 解析在编译时(静态绑定),基于编译时类型与参数类型选择。
- 重写(子类对父类方法):
- 方法签名完全一致(Java 8 后允许不同返回类型的协变返回),访问权限不可更严格,异常声明不能扔出新的更受检的异常。
- 调用是运行时绑定(多态)。
- 面试点:不能重写 static 方法(静态方法隐藏);不能重写 final 方法;构造器不能重写只能重载;桥接方法(bridge methods)与泛型类型擦除下的兼容。
10 Java 泛型
目的:提供编译时类型检查和更安全的代码复用。
实现机制:类型擦除(type erasure)——在编译时移除泛型信息,插入必要的类型转换和桥接方法以兼容旧字节码。
限制:
- 不能在运行时做
instanceof某个具体泛型类型(只能instanceof List)。 - 不能创建泛型数组(
new T[10]不允许)。 - 不能有泛型的静态成员直接使用类型参数(静态上下文没有类型参数信息)。
- 泛型异常(cannot create generic array of T)和不能抛出带泛型参数的受检异常。
- 不能在运行时做
通配符:
<? extends T>(生产者,只能读,PECS:Producer Extends)<? super T>(消费者,只能写,PECS:Consumer Super)
泛型方法与类型参数:
1
public static <T> T pick(T a1, T a2) { ... }
原生类型和擦除向后兼容:旧代码兼容,新代码编译会插入 casts。
面试点:PECS、类型擦除造成的桥接方法、泛型与反射(通过
Type,ParameterizedType获取泛型信息在运行时只能从声明处读取)。
1️⃣ PECS 原则(Producer Extends, Consumer Super)
概念:
针对泛型的上限、下限使用场景,由 Effective Java 提出。
公式:
? extends T→ 生产者(读取),不能写
? super T→ 消费者(写入),可以写英文记忆:PECS = Producer Extends, Consumer Super
示例:
1 | List<? extends Number> nums = new ArrayList<Integer>(); |
面试追问:
- 为什么
? extends不允许写入?- 因为具体类型可能是
Integer、Double等,写入不安全。
- 因为具体类型可能是
- 为什么
? super可以写入?- 至少可以保证写入对象是其父类类型兼容。
2️⃣ 类型擦除与桥接方法(Bridge Method)
2.1 类型擦除
- Java 泛型在编译期会被 类型擦除 → 编译后字节码不保留泛型信息(JVM 层面不支持泛型)。
- 例子:
1 | class Box<T> { |
- 编译后:
1 | class Box { |
- 编译器保证类型安全 → 泛型约束只在编译期检查。
2.2 桥接方法(Bridge Method)
- 当子类继承泛型父类或实现泛型接口时,类型擦除可能导致 方法签名不同 → 编译器生成“桥接方法”保证多态。
- 例子:
1 | class Parent<T> { |
- 编译后,JVM 方法签名:
1 | class Child extends Parent { |
- 桥接方法保证调用
Parent的引用时多态正常。
面试追问:
- Q: 为什么要生成桥接方法?
- A: 类型擦除后子类方法签名与父类不同,桥接方法保持编译期类型安全 + 运行时多态。
3️⃣ 泛型与反射
3.1 普通反射获取泛型
- 泛型类型在运行时被擦除,只能获取 声明处信息。
1 | class Box<T> { |
- 只能看到
Object,实际T已被擦除。
3.2 ParameterizedType 获取泛型信息
- 对方法、字段或类声明的泛型可以通过
Type/ParameterizedType获取:
1 | class StringBox extends Box<String> {} |
- 注意:只能获取继承/声明处的泛型,运行时对象类型信息丢失:
1 | Box<String> box = new Box<>(); |
面试追问:
- Q: 为什么
List<String>和List<Integer>在 JVM 层面是一样的?- A: 泛型擦除,运行时都是
List,类型信息只在编译期存在。
- A: 泛型擦除,运行时都是
4️⃣ 面试答题模板
- PECS 原则:
? extends T→ 生产者,读取安全,写入不安全? super T→ 消费者,可写入,读取只能当 Object
- 类型擦除:
- 泛型信息在编译期检查,运行期擦除成原始类型。
- 编译器通过桥接方法保持多态和类型安全
- 反射获取泛型:
- 只能读取 声明处类型
Type/ParameterizedType→ 获取具体泛型类型- 运行期对象泛型类型丢失
💡 小技巧面试答法:
- 提到桥接方法和类型擦除时,可以画一条箭头:
Parent<T>→Child extends Parent<String>→ 编译器生成桥接方法 → JVM 方法签名多态保持一致
11 反射
作用:在运行时加载类、查看结构(字段/方法/构造器)、动态调用方法/访问字段、创建对象。
核心 API:
Class<?>、Field、Method、Constructor、Annotation。常见用法:框架(Spring/ORMs)、测试工具、序列化库、动态代理。
性能与安全:
- 反射调用速度比直接调用慢很多(因为涉及安全检查、解析),可以通过
setAccessible(true)跳过访问检查来提高性能(但 Java 9 的模块化和安全策略会限制)。 - 替代方案:
MethodHandle/invokeWithArguments(更快),或者生成字节码(ASM)/动态代理。
- 反射调用速度比直接调用慢很多(因为涉及安全检查、解析),可以通过
访问私有成员:
field.setAccessible(true)(受 Java 模块化与安全管理器影响)。面试点:反射的用途与成本、如何用反射实现依赖注入、
Class.forName()与类加载器、类加载器三层结构与资源隔离。
1️⃣ 反射的用途
反射是 Java 动态获取类/对象信息、动态调用方法的机制。常用用途:
- 动态创建对象
1 | Class<?> clazz = Class.forName("com.example.User"); |
- 动态获取/修改属性
1 | Field f = clazz.getDeclaredField("name"); |
- 动态调用方法
1 | Method m = clazz.getMethod("sayHello", String.class); |
- 实现依赖注入(DI)和 IoC
- 框架在运行时扫描类,自动实例化对象、注入依赖(Spring、Guice 原理)。
- 思路:
- 扫描类路径,找到带注解的类。
- 通过
Class.newInstance()或getDeclaredConstructor().newInstance()创建实例。 - 使用
Field.set()注入依赖对象。
1 | class UserService { |
- Spring 实现:
- 利用
ReflectionUtils设置私有字段可访问 - 注入 bean,实现松耦合
- 利用
2️⃣ 反射的成本
- 性能开销
- 方法调用绕过静态类型检查 → JVM 无法内联优化 → 相比普通方法慢 10~20 倍
- 访问私有成员需要
setAccessible(true)→ 打破 JIT 优化
- 安全问题
- 可访问私有字段和方法 → 可能破坏封装
- 需要
SecurityManager或模块系统权限限制
- 可维护性
- 编译期无法检查成员存在 → 容易出错
- 不利于重构
总结:反射强大但开销大、可读性差,一般用于框架层、工具类或动态代理,不适合业务频繁调用。
3️⃣ Class.forName() 与类加载器
Class.forName(String className)作用:加载指定类,执行静态初始化块(类初始化阶段)
常用在 JDBC:
1
Class.forName("com.mysql.jdbc.Driver");
对比:
1
2Class<MyClass> clazz = MyClass.class; // 不触发初始化
Class.forName("MyClass"); // 会初始化类
类加载器
- ClassLoader:负责加载
.class字节码 → JVM 在内存生成Class对象 - 核心方法:
loadClass()→ 只加载,不初始化defineClass()→ 将字节码转换成 Class 对象- 初始化阶段触发静态块
4️⃣ 类加载器三层结构与资源隔离
Java 类加载器采用 父委托模型(Parent Delegation Model),常见三层:
| 层级 | 典型实现 | 加载范围 | 面试要点 |
|---|---|---|---|
| Bootstrap(启动类加载器) | JVM 内置 | java.* |
加载核心类库,无法直接获取对象 |
| Extension(扩展类加载器 / Platform) | sun.misc.Launcher$ExtClassLoader |
jre/lib/ext |
加载扩展类库 |
| Application(系统类加载器 / AppClassLoader) | 默认 | classpath 下应用类 | 加载业务代码和第三方依赖 |
- 父委托原则:
- 子加载器先委托父加载器
- 避免类被重复加载,保证核心类安全性
- 资源隔离:
- 不同类加载器加载同名类是不同
Class对象(内存隔离) - 典型应用:Web 容器(Tomcat)每个 webapp 一个类加载器 → 防止类冲突和资源泄漏
- 不同类加载器加载同名类是不同
5️⃣ 面试追问
- 反射能调用 private 方法吗?
- ✅ 可以,使用
setAccessible(true),破坏封装,但有安全风险。
- ✅ 可以,使用
- 为什么 Class.forName() 要抛 ClassNotFoundException?
- 因为指定的类可能不存在,加载失败时必须捕获异常。
- 为什么不同类加载器加载同名类是不同类型?
- JVM 内存中
Class对象由 类加载器 + 类全限定名 唯一确定 → 同名不同加载器,视为不同类。
- JVM 内存中
- 反射创建对象和直接 new 的性能差异?
- 反射慢 10~20 倍,主要因为动态解析、绕过 JIT 优化。
✅ 快速答题模板(面试版):
- 反射用途:动态创建对象、获取/修改属性、调用方法 → 框架 DI/IoC 核心
- 反射成本:性能慢、破坏封装、安全风险、可维护性低
- 依赖注入:扫描类 + newInstance() + Field.set()
- Class.forName():加载类并初始化
- 类加载器三层:
- Bootstrap → 核心类
- Extension → 扩展类
- App → 应用类
- 父委托 + 资源隔离:
- 避免类重复加载,Web 容器隔离每个应用,防止冲突
1️⃣ 双亲委派(Parent Delegation Model)
核心思想:
- 类加载请求先交给父类加载器,父加载器无法加载时才由子加载器自己加载。
- 保证核心类由 Bootstrap ClassLoader 加载,避免重复加载或安全问题。
加载流程:
- 子加载器收到加载请求(比如 AppClassLoader)
- 委托给父加载器(ExtClassLoader)
- 父加载器继续委托给更上层(Bootstrap)
- Bootstrap 能加载 → 返回 Class 对象
- 父加载器无法加载 → 子加载器自己加载
特点:
- 防止核心类被篡改(例如
java.lang.String永远由 Bootstrap 加载) - 保证每个类在 JVM 中唯一(Class+ClassLoader 唯一标识)
12 线程安全的集合与使用
- 同步封装(JDK Collections 工厂):
Collections.synchronizedList/Map/Set(...):把单个操作同步化(方法级锁)。注意:复合操作(check-then-act)仍需外部同步。
- 并发集合(java.util.concurrent):
ConcurrentHashMap:高并发哈希表(JDK8 以 CAS + synchronized on bin 为主)。putIfAbsent,remove(key, val),replace等原子操作。迭代弱一致(weakly consistent),不会抛 ConcurrentModificationException。CopyOnWriteArrayList/CopyOnWriteArraySet:写时复制,读多写少场景优秀(读无需锁,写创建新数组)。BlockingQueue(见第 22 题)用于生产者-消费者。ConcurrentLinkedQueue(无界非阻塞队列),基于 CAS 的链表。
- 如何使用:
ConcurrentHashMap适合频繁并发读写:使用computeIfAbsent避免 check-then-put race。- 对于复杂事务性操作,使用外部锁或事务机制;不要依赖单个集合的同步保证跨多个集合的一致性。
面试点:为什么 Collections.synchronizedMap 不能完全替代 ConcurrentHashMap(并发粒度和性能差别);CopyOnWrite 的开销与适用场景。
13 HashMap 底层原理与扩容机制
- 主要数据结构:数组(
Node<K,V>[] table) + 单向链表(发生哈希冲突时) + 当单条链表长度超过阈值时转为红黑树(TreeNode)。 - 重要常量(JDK8):
DEFAULT_INITIAL_CAPACITY = 1 << 4(16)MAXIMUM_CAPACITY = 1 << 30TREEIFY_THRESHOLD = 8(链表长度超过 8 时考虑树化)UNTREEIFY_THRESHOLD = 6(树退回链表阈值)MIN_TREEIFY_CAPACITY = 64(只有当 table 长度 >= 64 时才树化,否则先扩容)DEFAULT_LOAD_FACTOR = 0.75f(负载因子)
- hash 计算:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }- 通过高位与低位混合(扰动)减小冲突(高位影响到低位)。
- 索引计算:
index = (n - 1) & hash(利用容量为2的幂使位运算快速定位)。 - put 操作流程:
- 若 table 为 null,先初始化(默认容量 16)。
- 计算 hash、定位 bucket。
- 若 bucket 为空,直接插入(用 CAS 在并发场景未锁定时也能操作)。
- 若不为空,遍历链表或树:若发现 key 相等,覆盖 value;否则追加到链表尾或在树中插入。
- 若链表长度超过 TREEIFY_THRESHOLD 并且 table 长度 >= MIN_TREEIFY_CAPACITY,则树化;否则触发 resize。
- 每次插入后检查
size > threshold(threshold = capacity * loadFactor),超出则触发扩容。
- 扩容(resize):
- 扩容为 2 倍(
newCap = oldCap << 1),计算新阈值newThr = oldThr << 1。 - JDK8 中 resize 会把旧链表拆分为两个链表(low 和 high),利用节点 hash 与 oldCap 的单个位判断新索引,避免完全重新计算哈希。
- 扩容成本高(rehash),会导致短暂性能抖动;并发扩容会带来线程安全问题(HashMap 在并发写时可能造成链表成环导致 CPU 100% 等问题,故 HashMap 不是线程安全 的)。
- 扩容为 2 倍(
- get 操作复杂度:平均 O(1),最坏在所有元素冲突为同一槽且未树化时 O(n),JDK8 树化后降为 O(log n)。
面试点/常考题:
HashMap 的扩容触发条件与默认容量;为什么使用负载因子;为什么选择 0.75(时间/空间折中)。
为何要树化,何时树化(避免 O(n) 退化)。
在并发写入下 HashMap 会出现什么问题(死循环/链表环),以及解决方式(使用 ConcurrentHashMap 或外部同步)。
HashMap key 应该不可变,否则查找会出问题(例如 key 的 hashCode 依赖可变字段被修改后找不到)。
1️⃣ HashMap 扩容与负载因子
1.1 扩容触发条件
默认初始容量:16(2 的幂)
默认负载因子:0.75
触发条件:
1
当 size > capacity * loadFactor 时,触发扩容
- size:当前元素个数
- capacity:当前 table 长度
扩容通常 容量翻倍(2 倍)
1.2 为什么使用负载因子?
- 控制 HashMap 空间利用率与查找性能的折中。
- 负载因子过小:
- table 空间浪费严重
- 扩容频繁 → 性能开销大
- 负载因子过大:
- 链表长度增加 → 查找效率降低
- 0.75 的理由:
- Java 官方选择 0.75 作为折中点
- 平均查找 O(1),空间利用率较高
2️⃣ 为什么要树化(红黑树)
2.1 问题背景
- JDK8 前 HashMap 使用链表存储哈希冲突
- 当哈希碰撞严重,链表长度达到 O(n),查找退化成 O(n)
2.2 树化规则
- 当链表长度 > TREEIFY_THRESHOLD = 8 且数组长度 >= MIN_TREEIFY_CAPACITY = 64
- 链表会转为 红黑树
- 查找、插入、删除 → O(log n)
2.3 面试追问
- 为什么加数组长度限制(MIN_TREEIFY_CAPACITY)?
- 小数组直接扩容比树化更划算
- 为什么红黑树而不是 AVL 树?
- 红黑树插入删除调整成本低,适合哈希表冲突场景
3️⃣ HashMap 并发写入问题
3.1 并发问题表现
- JDK8 前:
- 多线程 put 时链表可能形成环 →
get()死循环
- 多线程 put 时链表可能形成环 →
- JDK8+:
- 仍不保证线程安全 → 写入可能丢失或覆盖
3.2 解决方式
使用 ConcurrentHashMap → 分段锁(JDK7)或 CAS + synchronized(JDK8+),线程安全
外部同步:
1
Map<K,V> map = Collections.synchronizedMap(new HashMap<>());
禁止在多线程下直接操作 HashMap
4️⃣ HashMap key 应该不可变
4.1 原因
key 的 hashCode 和 equals 必须稳定
如果 key 可变:
1
2
3
4
5Map<Person, String> map = new HashMap<>();
Person p = new Person("Tom");
map.put(p, "data");
p.setName("Jerry"); // hashCode 改变
map.get(p); // 返回 null,找不到原 keyHashMap 查找依赖 hashCode → bucket → equals
4.2 面试追问
- 可变 key 可以做什么防护?
- 不允许修改关键字段
- 使用不可变类(String、Integer、UUID)
- 或重新 put/update map
5️⃣ 面试快速答题模板
- 扩容
- 默认容量 16,负载因子 0.75 → 触发扩容
- 0.75 是时间/空间折中
- 树化
- 链表长度 > 8 且容量 >= 64 → 红黑树
- 提高查找性能,避免 O(n)
- 并发写入
- 多线程 HashMap 可能死循环/数据丢失
- 解决:ConcurrentHashMap 或外部同步
- key 不可变
- hashCode/equals 稳定 → 确保 put/get 正确
💡 补充底层知识点
扩容时 rehash:每个元素都需要重新计算桶索引
hash 再扰动:
为了减少高位相同导致冲突,JDK8 对 hash 做扰动处理:
1
2
3
4static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
链表转树条件:
- 链表太长 → 树化
- 树节点太少 → 链表化(UNTREEIFY_THRESHOLD = 6)
14 ConcurrentHashMap 的线程安全实现(深入,JDK7 vs JDK8)
- JDK7(老的实现):
- 基于分段锁(
Segment[] segments),每个 Segment 维护一把锁,锁的粒度为 segment(可并行度 = segment 数);操作在单个 segment 内并发安全。
- 基于分段锁(
- JDK8(重构后的实现):
- 去掉 Segment,使用与 HashMap 类似的
Node<K,V>[] table。 - 无全表锁:采用多种优化——CAS 创建节点/置入、synchronized 仅在单个 bin 上(链表或 tree bin 上)用于插入/修改,读取操作不加锁(volatile 可见)。
- 关键概念:
table是 volatile,节点next、value等字段使用 volatile/CAS,以保证可见性和原子性。put:先 CAS 尝试把新 node 放到空桶;若失败或桶非空,采用 synchronized(binHead) 来完成插入(以避免竞争)。putIfAbsent、computeIfAbsent等使用 CAS + 锁配合来保证原子性。- 树化:当单个 bucket 链表长度过大时,会转为树(与 HashMap 类似)。
- 扩容:采用多线程协助搬迁(transfer),
sizeCtl字段控制迁移状态,多个线程可以参与一次扩容以提升效率。
- 读取:
get通常是无锁的,遍历链表或 tree bin,用 volatile 读取确保可见。
- 去掉 Segment,使用与 HashMap 类似的
- 弱一致性迭代:迭代器不会抛出
ConcurrentModificationException,返回的是“弱一致”视图(可能看不到一些并发修改,也可能看到)。 - 性能:JDK8 的实现综合使用 CAS 和局部锁,读性能非常好,写性能也较 JDK7 改进。
面试点:ConcurrentHashMap 为什么不需要全局锁,get 为什么不加锁安全,为什么 remove/size 等操作不是常 O(1) 精确(需要并发统计)。
1️⃣ 为什么 ConcurrentHashMap 不需要全局锁?
1.1 JDK 7 vs JDK 8
| 版本 | 锁机制 |
|---|---|
| JDK 7 | 分段锁(Segment + ReentrantLock) |
| JDK 8+ | Node + CAS + synchronized(链表/红黑树节点) |
1.2 核心思想
- 细粒度锁,只锁某个桶(bucket)或链表节点,而不是整个表
- CAS(Compare-And-Swap)+ synchronized:大部分操作通过 CAS 保证原子更新,链表/树节点操作用局部锁
- 结果:并发写入多个桶时不会互相阻塞 → 高吞吐量
2️⃣ 为什么 get 不加锁也安全?
2.1 原理
- volatile + final 保证可见性
- HashMap table、Node.value 都是 volatile 或 final → 线程读取总能看到最新对象
- 读取操作不修改结构
get()只是按 hash 找到 bucket,再遍历链表/红黑树读取 value → 不改变链表结构
- JMM 保证可见性
- 写入操作(put/resize)保证 happens-before → get 读取安全
2.2 面试要点
- get 不加锁 → 高性能,线程安全
- 注意:
- 遍历过程中,写入可能正在进行 → 可能 get 不到最新数据,但不会抛异常
3️⃣ remove/size 等操作为什么不是 O(1) 精确?
3.1 remove
- remove 需要找到对应桶,再修改链表/树节点
- 对每个桶局部加锁,不同线程可能同时删除 → 最终结果仍正确
- 不是全局锁 → 并发 remove 与 put/resize 会交错,复杂度取决于链表长度(O(n/k))
3.2 size()
- ConcurrentHashMap 不维护全局计数器
- 各个桶独立统计 size → 获取精确值需要遍历所有桶并累加
- 在高并发情况下,size() 可能 瞬间不精确
- 避免频繁全局锁 → 提升性能
- 如果需要精确 size,可以用
mappingCount()或外部同步
4️⃣ 面试答题模板
- 不需要全局锁
- JDK8 使用 CAS + synchronized(局部桶锁)
- 写操作只锁部分桶 → 高并发性能
- get 不加锁安全
- Node.value/next 是 volatile/final → 线程可见性
- 读取不修改结构 → 不会破坏链表/树
- remove/size 非 O(1)
- remove → 需要遍历桶 → 复杂度取决于链表长度
- size → 各桶统计,不加全局锁 → 可能瞬间不精确
- 总结
- 高性能 → get 无锁
- 写入局部锁 → 避免全局阻塞
- size/remove 不保证严格 O(1) → 设计折中性能和精确性
💡 补充知识点
- JDK8 table resize:使用
ForwardingNode+ CAS,保证扩容期间并发安全 - 红黑树/链表转换:在并发环境下用 synchronized 保证线程安全
- volatile 语义:
- 避免部分线程看到旧值
- 保证 Node 节点读写顺序
15 ArrayList vs LinkedList
- ArrayList:
- 内部是动态数组(
Object[] elementData)。 - 随机访问
get(i)为 O(1)。 - 插入/删除在尾部 amortized O(1);在中间位置插入/删除需要移动元素 O(n)。
- 扩容策略:默认初始为空数组(jdk8之后),第一次 add 会扩容到 10;后续扩容
newCapacity = old + (old >> 1)(约 1.5x)。 - 内存紧凑,良好缓存局部性(CPU cache 友好)。
- 内部是动态数组(
- LinkedList:
- 基于双向链表(
Node包含 prev/next/item)。 - 随机访问
get(i)为 O(n)(需要顺序遍历)。 - 在列表中间插入/删除为 O(1)(仅修改邻接节点指针),前提是已定位到节点(定位本身 O(n))。
- 内存占用高(每个节点多个指针对象),GC 压力更大。
- 基于双向链表(
- 选择准则:
- 频繁随机访问 →
ArrayList。 - 频繁在列表中间插入/删除且遍历更多 →
LinkedList(但在多数场景ArrayList仍优,因为插入删除远不如随机访问常见,而且复制成本在局部更低)。
- 频繁随机访问 →
面试点:扩容开销、ensureCapacity、trimToSize、迭代时的 fail-fast(modCount)机制。
1️⃣ 扩容开销
1.1 扩容触发条件
ArrayList 内部用
Object[] elementData存储元素触发条件:
1
size >= elementData.length
默认容量:
- 初始容量:10(无参构造)
- 构造器可指定初始容量
ArrayList(int initialCapacity)
1.2 扩容机制
- 扩容时通常 1.5 倍或 2 倍(JDK 8 ArrayList 为 1.5 倍)
- 扩容开销:
- 新数组分配 → O(n)
- 旧数组元素复制 → O(n)
- 面试追问:
- 批量插入大量元素时最好指定初始容量 → 避免多次扩容
2️⃣ ensureCapacity(int minCapacity)
2.1 作用
- 手动确保 ArrayList 至少有
minCapacity容量 - 提前分配数组 → 避免频繁扩容
2.2 使用示例
1 | ArrayList<Integer> list = new ArrayList<>(); |
2.3 面试点
- 用于性能优化
- 避免批量添加时不断触发扩容和数组复制
3️⃣ trimToSize()
3.1 作用
- 将
elementData数组容量缩减到 当前 size - 节约内存空间,特别是 ArrayList 元素较少且容量大时
3.2 使用示例
1 | ArrayList<Integer> list = new ArrayList<>(1000); |
3.3 面试点
- 用于 内存优化
- 注意:之后再次 add 元素可能触发扩容 → 有性能开销
4️⃣ 迭代时的 fail-fast(modCount)机制
4.1 原理
ArrayList 内部维护
modCount:- 每次 结构性修改(add/remove/clear) → modCount++
Iterator 获取 modCount 副本
expectedModCount遍历时检查:
1
2if (modCount != expectedModCount)
throw new ConcurrentModificationException();
4.2 触发场景
- 结构性修改 → 抛 ConcurrentModificationException
- 非结构性修改(如
set()替换元素)不会触发
4.3 面试点
- 目的:快速发现并发或不安全操作 → fail-fast
- 注意:
- 并发修改 ArrayList → Iterator 异常
- 并发安全 → 使用
CopyOnWriteArrayList或手动同步
5️⃣ 面试快速答题模板
- 扩容开销
- 扩容触发条件:
size >= capacity - 扩容过程:新数组 + 元素复制 → O(n)
- 优化:指定初始容量
- 扩容触发条件:
- ensureCapacity
- 提前分配容量,避免频繁扩容
- trimToSize
- 缩减数组长度到当前 size → 节约内存
- fail-fast
modCount记录结构性修改- Iterator 检查
expectedModCount - 结构修改 →
ConcurrentModificationException
💡 补充知识点
- ArrayList 扩容策略是 时间/空间折中
- 迭代器 fail-fast 并非严格同步机制 → 只是快速失败检测
- 批量插入 + ensureCapacity → 性能最佳实践
1️⃣ LinkedList 基本原理
底层结构:双向链表(Doubly Linked List)
1
Node<E> { E item; Node<E> next; Node<E> prev; }
存储特点:
- 每个节点包含元素值 + 前驱 + 后继指针
- 内存分配按节点动态分配(Heap)
- 不需要预分配容量 → 没有扩容概念
特点:
- 增删快:O(1)(已定位节点时)
- 查找慢:O(n)(按索引遍历节点)
- 支持双向遍历:prev/next
2️⃣ 插入与删除
- add / addFirst / addLast
- 创建新节点 → 更新前驱/后继 → size++
- 已知节点可在 O(1) 完成插入
- remove / removeFirst / removeLast
- 更新前驱/后继指针 → GC 回收节点 → size–
- 按索引插入/删除
- 需遍历节点 → O(n)
面试点
- 插入删除头尾快,随机访问慢
- 对比 ArrayList:随机访问慢,尾部插入快或慢取决于是否扩容
3️⃣ 迭代器与 fail-fast
modCount 机制与 ArrayList 类似
- LinkedList 每次结构修改(add/remove/clear) →
modCount++
- LinkedList 每次结构修改(add/remove/clear) →
迭代器
创建时记录
expectedModCount = modCountnext()/remove() 时检查:
1
if (modCount != expectedModCount) throw new ConcurrentModificationException();
特点
- 遍历链表时结构修改 → fail-fast
- 非结构性修改(修改元素值
set())不触发异常
4️⃣ LinkedList 特点总结
| 特性 | LinkedList | ArrayList |
|---|---|---|
| 底层结构 | 双向链表 | 动态数组 |
| 随机访问 | O(n) | O(1) |
| 插入/删除 | O(1) 已知节点 | O(n) 平均 |
| 内存分配 | 节点动态分配 | 整体数组扩容(复制元素) |
| 迭代器 | fail-fast | fail-fast |
| 扩容 | 不需要 | 需要复制数组(O(n)) |
| 内存开销 | 大,每个节点多 2 个指针 | 小,连续内存 |
5️⃣ 面试追问
- LinkedList 和 ArrayList 何时用哪个?
- ArrayList:随机访问多,插入删除少
- LinkedList:频繁插入/删除头尾,随机访问少
- 为什么 LinkedList 没有扩容?
- 每个节点单独分配,链表不需要连续内存 → 不存在数组复制开销
- fail-fast 能保证并发安全吗?
- ❌ 不能,只是快速失败检测
- 并发操作需外部同步或使用
CopyOnWriteArrayList/ConcurrentLinkedDeque
- 为什么 LinkedList 内存占用大?
- 每个节点额外保存两个引用(prev/next)
- 对象头 + 数据 + 两个引用 → 比 ArrayList 每元素占用多
6️⃣ 面试快速答题模板
- 底层:双向链表 → 每节点:item/prev/next
- 扩容:无,动态分配节点
- 增删:头尾 O(1),随机 O(n)
- 迭代器:fail-fast,通过 modCount 检测结构修改
- 适用场景:频繁插入/删除,顺序遍历;随机访问少
- 内存开销:比 ArrayList 高(节点指针多)
💡 补充知识点
- Java 8 LinkedList 内部节点还是
Node<E>+ 双向链表 - 支持 Deque 接口 → 可以用作栈/队列
- fail-fast 和多线程并发同样不安全 → 外部同步或使用
ConcurrentLinkedDeque
16 基本类型 vs 包装类型
- 基本类型:
- 存放值,效率高,不能为
null。 - 不能用于泛型(必须使用包装类),不能放入集合(需要装箱)。
- 存放值,效率高,不能为
- 包装类型(如 Integer):
- 对象,存放在堆,有对象头,有引用开销,支持
null。 - 提供方法(parse、valueOf 等)。
- 对象,存放在堆,有对象头,有引用开销,支持
- 性能差异:包装类型会产生额外对象分配与 GC,尽量在性能敏感场景使用基本类型数组(
int[])或原语流/第三方库。
17 Java 的 Object 类常用方法
equals(Object obj):比较逻辑相等。hashCode():哈希码。toString():字符串表示。getClass():返回运行时 Class 对象。clone():浅拷贝(需实现Cloneable才有效,通常不推荐使用 clone)。finalize():对象回收前调用(已弃用,不可靠,JDK9+ 标记为 deprecated)。wait()/notify()/notifyAll():对象监视器(必须在 synchronized 块中调用),用于线程间通信。registerNatives()等(本地方法)。
面试点:为什么不建议使用 finalize;如何正确使用 wait/notify(必须在同步块中,防止虚假唤醒用 while 循环判断 condition)。
好的,wait/notify 是 Java 多线程协作的核心面试点,常被问“为什么必须在同步块中”、“虚假唤醒如何处理”,我帮你系统整理,并给出例子。
1️⃣ wait/notify 基本原理
- wait()
- 让当前线程进入等待状态,释放持有的锁
- 等待其他线程调用
notify()或notifyAll()唤醒 - 必须在 同步块/方法中调用,否则抛
IllegalMonitorStateException
- notify() / notifyAll()
- 唤醒在当前对象 monitor 上等待的线程
- notify:随机唤醒一个
- notifyAll:唤醒所有线程
2️⃣ 必须在同步块中的原因
每个对象有 对象监视器(monitor)
wait/notify操作依赖持有 monitorJava 语言规定:
1
2
3
4monitor.enter(); // synchronized
wait() // 释放 monitor,进入等待队列
notify() // 唤醒等待队列线程
monitor.exit();
3️⃣ 防止虚假唤醒
虚假唤醒:线程可能被唤醒,但条件不满足
因此 wait 必须放在 while 循环中检查条件:
1
2
3
4
5
6synchronized(lock) {
while (!condition) {
lock.wait();
}
// 条件满足,执行任务
}不要用 if,因为虚假唤醒或多线程唤醒可能导致错误执行
4️⃣ wait/notify 使用模板
1 | class Resource { |
- 特点:
- 条件检查放在
while中 → 防虚假唤醒 wait/notifyAll都在 synchronized 方法或块 中notifyAll通常比notify更安全,避免某些线程永远等待
- 条件检查放在
5️⃣ 示例:生产者-消费者
1 | public class ProducerConsumerDemo { |
输出示意:
1 | Producing... |
- 生产者和消费者轮流执行
while循环保证虚假唤醒时线程不会错误执行- synchronized + wait/notifyAll 保证线程安全
✅ 面试要点总结
- 必须在同步块中 → 持有对象 monitor
- 防止虚假唤醒 →
while(condition) - notify vs notifyAll
- notify 唤醒一个线程,效率高,但可能导致线程饿死
- notifyAll 唤醒所有线程,更安全
- 线程安全协作
- wait 释放锁 → allow 其他线程执行
- 条件改变后 notifyAll 唤醒等待线程
18 深拷贝 / 浅拷贝 / 引用拷贝
- 引用拷贝:变量复制引用,两者指向同一对象(
a = b)。 - 浅拷贝:
- 对象本身复制一份(字段为基本类型复制值),引用类型字段复制引用(不复制引用对象)。
Object.clone()默认实现就是浅拷贝(只复制字段)。
- 深拷贝:
- 不仅复制对象本身,还递归复制所有引用对象(或复制所需的子对象),得到完全独立的对象树。
- 实现方式:手写递归复制、通过序列化(对象->字节->对象)或使用第三方库(如 Apache Commons Lang
SerializationUtils.clone())/手动 copy constructor。
- 面试点:浅拷贝带来的共享可变子对象问题;clone 的陷阱(浅拷贝导致共享、需要实现 Cloneable 并覆盖 clone、异常处理);如何实现可扩展的深拷贝(每个类提供 copy constructor 或工厂方法)。
19 JDK 动态代理 & CGLIB
JDK 动态代理(java.lang.reflect.Proxy):
基于接口:只能为实现了接口的类创建代理。
通过
InvocationHandler的invoke(Object proxy, Method method, Object[] args)拦截所有方法调用。代码示例:
1
2
3
4
5MyInterface proxy = (MyInterface) Proxy.newProxyInstance(
loader,
new Class<?>[]{MyInterface.class},
(p, m, a) -> { /* 横切逻辑 */ return m.invoke(target, a); }
);
CGLIB(字节码生成, org.springframework.cglib 或 net.sf.cglib):
- 基于生成目标类的子类(继承)并重写方法,适用于没有接口的类。
- 不能为
final类或final方法创建代理(因为继承时无法覆盖 final 方法)。
Spring AOP:默认使用 JDK 动态代理(若目标实现接口),否则回退到 CGLIB(或可强制使用 CGLIB)。
性能:JDK Proxy 在接口较多时开销较小,CGLIB 在没有接口的情况下是必须选项;现代实现都很快,但生成字节码开销存在(通常在代理创建时发生一次)。
面试点:自调用(同类方法内部调用)不会触发通过代理的拦截(因为代理是外部包装);如何绕开(用 AopContext.currentProxy() 或把逻辑放到另一个 bean)。
20 序列化 / 反序列化
序列化:将对象转成字节流(保存到文件/传输网络)。
反序列化:字节流还原为对象。
Java 原生序列化:
- 对象需实现
Serializable。可以定义private static final long serialVersionUID控制版本兼容。 - 可标
transient字段为不序列化。 - 缺点:体积大、性能差、安全风险(直接反序列化恶意数据存在 RCE 风险),版本兼容复杂。
- 对象需实现
替代协议:Protobuf、Avro、Thrift、Kryo、Hessian、JSON 等(更紧凑/跨语言/更安全)。
面试点:serialVersionUID 作用、如何实现自定义序列化(
writeObject/readObject)、安全问题与防御(不要直接反序列化不可信数据、使用白名单、安全库)。
1️⃣ serialVersionUID 作用
- 定义:
private static final long serialVersionUID - 用途:序列化时标识类版本
- 工作原理:
- 序列化对象 → 在字节流中写入
serialVersionUID - 反序列化 → JVM 检查流中
serialVersionUID与本地类是否匹配 - 不匹配 → 抛
InvalidClassException
- 序列化对象 → 在字节流中写入
- 默认行为:
- 如果没有显式声明,JVM 会根据类结构自动生成 UID
- 类结构变更 → UID 变更 → 反序列化失败
- 面试答题重点:
- 显式声明
serialVersionUID→ 保证类结构轻微变动后仍能兼容 - 推荐所有可序列化类都显式声明
- 显式声明
1 | private static final long serialVersionUID = 1L; |
2️⃣ 自定义序列化
- 默认实现:
ObjectOutputStream.writeObject()→ 按字段顺序写入ObjectInputStream.readObject()→ 按字段顺序读取
- 自定义:通过实现
writeObject/readObject方法
2.1 示例
1 | import java.io.*; |
- 特点:
defaultWriteObject()/defaultReadObject()→ 保留默认序列化- 可自定义处理 transient 或敏感字段
- 可以做数据加密、压缩或版本兼容处理
3️⃣ 安全问题
3.1 常见问题
- 反序列化不可信数据
- 攻击者可以构造恶意对象 → 触发任意代码执行
- 典型 CVE:
CommonsCollections反序列化链攻击
- 对象注入
- 构造特殊 payload → 修改程序行为、执行任意方法
3.2 防御措施
避免直接反序列化外部数据
1
2ObjectInputStream ois = new ObjectInputStream(socket.getInputStream());
Object obj = ois.readObject(); // 危险- 尽量使用 安全库 或 数据转换格式(JSON、Protobuf)
白名单机制
JDK 9+ 提供
ObjectInputFilter:1
2ObjectInputFilter filter = ObjectInputFilter.Config.createFilter("java.base/*;!*");
ois.setObjectInputFilter(filter);只允许特定类反序列化,拒绝未知类
自定义 readObject() 验证数据
- 检查字段合法性、防止恶意 payload
序列化替代方案
- JSON、Protobuf、Kryo(安全配置)
4️⃣ 面试答题模板
- serialVersionUID
- 标识类版本
- 显式声明避免类结构改动破坏兼容
- 自定义序列化
writeObject/readObject- 处理 transient / 加密 / 压缩 / 版本兼容
- 安全问题
- 不可信数据反序列化 → 可执行任意代码
- 防御:白名单、过滤器、自定义验证、使用安全库
- 最佳实践
- 所有 Serializable 类显式声明 UID
- 避免直接反序列化外部输入
- 对敏感数据用 transient + 自定义序列化处理
💡 补充知识点
readResolve()/writeReplace()→ 允许序列化替换对象- 反序列化安全是高频面试点 → 尤其是 Java 企业安全岗
21 常见序列化协议(优缺点)
- Java 原生:易用但臃肿、慢、安全问题。
- JSON(Jackson / Gson):可读、跨语言、慢于二进制、无模式(schema)。
- Protobuf(Google):二进制、高效、需要 schema、跨语言。
- Avro:支持 schema 演进,适合大数据。
- Thrift:类似 Protobuf,支持 RPC。
- Kryo:高性能 Java 专用序列化(用于低延迟场景)。
- Hessian:二进制 Web 服务序列化,跨语言。
面试点:如何基于场景(跨语言/性能/兼容性)选择序列化协议。
22 BlockingQueue
- 定义:
BlockingQueue支持在队列为空时阻塞消费者;在队列为满时阻塞生产者。常用于生产者-消费者模式,线程池的 work queue。 - 方法:
- 阻塞:
put(E)(满时阻塞)、take()(空时阻塞)。 - 非阻塞:
offer(E)、poll()(可返回 null 或布尔)。 - 带超时:
offer(E, timeout, unit)/poll(timeout, unit)。
- 阻塞:
- 常见实现:
ArrayBlockingQueue:基于数组、固定大小、可选择公平/非公平锁(ReentrantLock)实现。LinkedBlockingQueue:基于链表,可选边界(默认 Integer.MAX_VALUE),读写使用不同锁,吞吐量高。PriorityBlockingQueue:基于优先队列,不保证 FIFO,非公平(无阻塞 put,因为无界)。SynchronousQueue:不保存元素,每个 put 必须等待一个 take(直接交付)。适合线程间直连交互(常用在 ForkJoinPool,或 ThreadPoolExecutor 饱和策略)。DelayQueue:元素带延迟,只有到期后才能被 take(常用于定时任务)。
- 使用建议:根据吞吐与公平性选择实现;
LinkedBlockingQueue适合高吞吐,ArrayBlockingQueue提供固定容量和可控行为。
23 PriorityQueue
- 实现:基于二叉堆(通常是数组形式的最小堆),在 JDK 中
PriorityQueue是最小堆(最小元素优先)。 - 复杂度:
offer()/poll():O(log n)(上下调整堆)。peek():O(1)。remove(Object):O(n)(删除任意元素需要线性查找并重新堆化)。
- 元素要求:要么实现
Comparable,要么在构造时传入Comparator。不能保存null。 - 非线程安全:多线程需要外部同步或使用
PriorityBlockingQueue。 - 用途:任务调度、A* 算法的 open set、定时任务优先级管理(结合 DelayQueue/自定义时间比较器)。
- 实现细节:内部使用
siftUp/siftDown操作维持堆性质。
24 设计原则
面向对象的设计模式有七大基本原则:
- 开闭原则(Open Closed Principle,OCP)
- 单一职责原则(Single Responsibility Principle, SRP)
- 里氏代换原则(Liskov Substitution Principle,LSP)
- 依赖倒转原则(Dependency Inversion Principle,DIP)
- 接口隔离原则(Interface Segregation Principle,ISP)
- 合成/聚合复用原则(Composite/Aggregate Reuse Principle,CARP)
- 最少知识原则(Least Knowledge Principle,LKP)或者迪米特法则(Law of Demeter,LOD)
| 标记 | 设计模式原则名称 | 简单定义 |
|---|---|---|
| OCP | 开闭原则 | 对扩展开放,对修改关闭 |
| SRP | 单一职责原则 | 一个类只负责一个功能领域中的相应职责 |
| LSP | 里氏代换原则 | 所有引用基类的地方必须能透明地使用其子类的对象 |
| DIP | 依赖倒转原则 | 依赖于抽象,不能依赖于具体实现 |
| ISP | 接口隔离原则 | 类之间的依赖关系应该建立在最小的接口上 |
| CARP | 合成/聚合复用原则 | 尽量使用合成/聚合,而不是通过继承达到复用的目的 |
| LOD | 迪米特法则 | 一个软件实体应当尽可能少的与其他实体发生相互作用 |
其中,单一职责原则、开闭原则、迪米特法则、里氏代换原则和接口隔离原则就是我们平常熟知的SOLID。
小结 + 典型面试追问准备
- HashMap、ConcurrentHashMap、ArrayList/LinkedList、String 系列、equals/hashCode、volatile/final/static 是高频点;务必能画数据结构示意图与关键代码路径(比如 put/get 的流程图)。
- 练习写出
equals/hashCode的正确实现样例,能解释 HashMap 的扩容和树化阈值(16/0.75/8/64)。 - 熟悉
synchronizedvsLockvsvolatile的语义与性能差异;理解 JMM 基础(happens-before,final 字段语义)。 - 对并发集合,能解释为什么
ConcurrentHashMap.get()不加锁仍安全(volatile 可见与不变性保证)。
数据库基础-牛客面经八股
1. MySQL 的存储引擎有哪些?它们之间有什么区别?默认使用哪个?
常见引擎(并非全部):
- InnoDB:事务性引擎,支持 ACID、行级锁、MVCC、外键、崩溃恢复(redo/undo、doublewrite)、自带缓冲池(buffer pool)。适合 OLTP。默认引擎(MySQL 5.5+)。
- MyISAM:非事务、表级锁、较小 IO 延迟、全文索引(早期),恢复能力弱,不支持外键。适合只读或读多写少场景。
- MEMORY(HEAP):把数据放内存,访问极快,但断电丢失,适合临时表或高速缓存。
- CSV:把每行存为 CSV 文件,便于导/出,但功能非常有限。
- ARCHIVE:适合归档写入(高压缩、只追加、只支持 INSERT/SELECT),不能索引(或索引能力弱)。
- NDB(MySQL Cluster):分布式内存存储引擎,适用于高可用、分布式场景(复杂运维)。
- 其他第三方/变体:如 MyRocks(Facebook 的 RocksDB 后端,写放大与压缩优化)、TokuDB 等。
区别要点:
- 事务支持(InnoDB 支持,MyISAM 不支持)。
- 锁粒度(InnoDB 行级锁,MyISAM 表级锁)。
- 崩溃恢复(InnoDB 有 redo/undo/doublewrite),MyISAM 依赖修复工具。
- 存储与索引实现细节(索引类型、压缩、聚簇索引等)。
- 性能定位:InnoDB 通常更平衡适合并发写;MyISAM 在单纯读场景可能略快。
默认引擎:现代 MySQL(5.5 之后)默认是 InnoDB。
2. MyISAM 与 InnoDB 的区别?如何选择?
关键差别:
- 事务:InnoDB 支持事务(ACID),MyISAM 不支持。
- 锁:InnoDB 行级锁(更高并发性);MyISAM 表级锁(写操作会阻塞读写)。
- 崩溃恢复:InnoDB 支持 redo/undo + doublewrite(较安全);MyISAM 恢复能力差(需 myisamchk)。
- 外键:InnoDB 支持外键约束;MyISAM 不支持。
- 存储:InnoDB 有聚簇索引(主键与数据同 B+Tree),MyISAM 主数据与索引分离(非聚簇)。
- 全文搜索:历史上 MyISAM 支持全文索引;新 MySQL 版本 InnoDB 也支持全文索引。
- IO & 性能:MyISAM 在简单读场景可能低延迟;InnoDB 在高并发写/读混合时更好。
如何选择:
- 需要事务/并发写/外键/崩溃安全 → InnoDB。
- 只读或极少写、对数据一致性要求低、老系统或特殊查询(极短)→ MyISAM 可考虑,但现在建议首选 InnoDB。
- 如果是高速缓存性质短期数据可考虑 MEMORY。
- 总体建议:生产 OLTP 系统用 InnoDB。
3. InnoDB 是如何存储数据的?
核心概念(实现层):
- 表空间(tablespace):InnoDB 用 tablespace 存储数据页与索引页。可以是共享系统表空间 (
ibdata1) 或innodb_file_per_table=ON(每表单文件 .ibd)。 - 页(page):默认页大小 16KB(可配置)。页是读写的最小单位,页里包含多个记录(row)与链表/目录。
- B+ 树索引:
- 聚簇索引(clustered index):主键索引就是数据的物理组织(叶子节点存放完整行)。若无主键,InnoDB 会选择第一个非 NULL 唯一键或内部生成隐式列作为聚簇键。
- 二级索引(secondary index):非主键索引的叶子存放索引列 + 主键值(作为指向聚簇索引的“指针”);因此二级索引查到行后还需回聚簇索引读取完整行(称回表)。
- 事务日志:
- Redo log(重做日志):预写日志(WAL),用于崩溃恢复(ib_logfile*)。
- Undo log(回滚/MVCC):用于多版本并发控制(MVCC),支持一致性读(快照读),undo 存在系统表空间或独立 undo tablespace。
- Doublewrite buffer:写入磁盘前把页写入 doublewrite 区,防止半页写入导致损坏(提高崩溃安全)。
- Buffer Pool:InnoDB 的核心缓存区,缓存数据页和索引页,读写都尽量在 buffer pool 完成以减 IO。
- MVCC(多版本并发):
- 通过在行上或 undo-log 中保存旧版本来实现一致性读(Read View)。读写隔离依赖 undo 来提供快照。
- 默认隔离级别
REPEATABLE-READ(MySQL 特性:使用间隙锁 + next-key lock 以避免幻读)。
- 插入缓冲/变更缓冲(change buffer/insert buffer):延迟索引操作合并以提高插入吞吐(针对非聚簇索引)。
- 行格式:REDUNDANT/COMPACT/DYNAMIC/COMPRESSED;大字段(BLOB/TEXT 或超长 VARCHAR)可 off-page(只在行内留 20 字节指针),减少行膨胀。
4. MySQL 一行记录是怎么存储的?
以 InnoDB 为例(聚簇行存放在 B+ 树叶子页):
- 页头 + 页目录(slot) + 记录区 + 空闲区 + 页尾/校验。页头包含 LSN、Page number 等元信息;页尾可能有校验信息。
- 记录格式(简化):
- 记录头(记录类型、链表指针、事务信息、记录长度)。
- NULL 位图(标记哪些列为 NULL)。
- 记字段数据:固定长度列(定长)先写,变长列(VARCHAR、BLOB)写长度与内容;若内容很长,InnoDB 的 DYNAMIC/COMPRESSED 行格式会把大字段存放到外部 overflow 页,行内只保留指针(通常 20 字节)。
- 二级索引条目:只包含索引列 + 主键(作为定位聚簇行的“引用”)。因此二级索引不会重复存储全部行内容,节省空间但会导致回表。
MyISAM:每行存在数据文件(.MYD),索引在 .MYI;没有聚簇索引,索引里存偏移量指向数据文件中的行。
5. 详细描述一条 SQL 在 MySQL 中的执行过程
高层步骤(客户端到存储引擎):
- 客户端层:应用通过连接(Connector/J 等)发送 SQL 到 MySQL Server(线程池/one-thread-per-connection)。
- 连接与认证:MySQL 验证账号/权限(authentication plugin、grant tables)。
- 解析(Parser):SQL 被词法/语法解析器转换为解析树(parse tree),检查语法正确性。
- 预处理 / 语义分析:解析树变成 parse tree 的语义检查,解析表名、列名是否存在,权限检查。
- 重写/视图/子查询优化:展开视图、优化子查询(视具体版本,子查询可重写为 JOIN)、派生表(derived table)处理(有时会创建临时表)。
- 查询优化器(Optimizer):
- 根据表统计信息、索引、条件,生成若干候选执行计划(访问路径、连接顺序、连接算法)。
- 使用代价模型(cost estimates)选择最优计划。会决定是否使用索引、哪种索引、join 顺序等。
- 执行引擎(Execution Engine)/计划执行:
- 根据执行计划逐步执行:遍历表、应用 WHERE、做 JOIN、聚合 GROUP BY、排序 ORDER BY、生成结果行。
- 在执行过程中与**存储引擎(Handler API)**交互做实际 IO(InnoDB、MyISAM)。
- 存储引擎层(如 InnoDB):
- 执行页读取、索引查找、事务隔离控制(锁、MVCC)、读写缓冲、写日志(redo)等底层操作。
- 返回结果:执行引擎把结果发送回客户端;若是写操作,会提交事务(若是自动提交或显式提交),redo log 刷盘(强制或延迟由配置决定)。
- 统计/缓存更新:query cache(若启用且有效,但在新版本中已弃用/移除),慢查询记录等。
注意:实际过程包含很多优化(例如谓词下推、索引条件下推、block nested loop、batched key access、histograms 等),不同 MySQL 版本细节不同,但总体流程如上。
6. MySQL 的查询优化器如何选择执行计划?
核心机制:
- 基于成本的优化器(CBO):使用统计信息(表基数、索引基数、分布直方图等)估算每个访问路径(全表扫描、索引范围、索引唯一查找等)的代价(IO、CPU)。
- 统计信息来源:通过
ANALYZE TABLE更新,也会由执行过程中动态采样。MySQL 8 引入了更精细的直方图支持(更好估算非均匀分布列)。 - 选择因素:
- 索引可用性(是否存在合适索引、是否为覆盖索引)。
- 选择性(selectivity)——该索引能筛掉多少行。
- 表大小(行数)、列基数。
- 连接顺序、连接算法(Nested-Loop 为主;有时使用 Index Merge、Block Nested Loop、Hash Join 在某些版本/场景可用)。
- 是否可以进行
index-only(覆盖索引)避免回表。 - 物化临时表 vs on-the-fly 的成本(派生表策略)。
- 搜索策略:MySQL 会根据 join 数量与成本在一定规则下枚举 join 顺序(对较多表会采用启发式或限制性搜索以避免指数爆炸)。
- 优化器提示与开关:可以通过
USE INDEX/FORCE INDEX/STRAIGHT_JOIN/OPTIMIZER_SWITCH等影响计划选择。 - 上手实践:使用
EXPLAIN/EXPLAIN ANALYZE(MySQL 8)查看执行计划、识别 full table scan、filesort、temporary 的使用,并据此调整索引/SQL 重写/统计信息。
7. SQL 中 SELECT、FROM、JOIN、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT 的执行顺序?
逻辑/标准的处理顺序(简化):
- FROM(包含 JOIN,并先应用 ON 条件用于连接裁剪/过滤)
- WHERE(行级过滤)
- GROUP BY(分组)
- HAVING(对分组结果的过滤)
- SELECT(投影、表达式计算)
- DISTINCT(去重,如果有)
- ORDER BY(排序)
- LIMIT(限制返回行数)
注意:
- 子查询 / 派生表 在其内部先执行(或由优化器重写)。
- 优化器在物理执行上可能重排序或采用更有效算法(例如把谓词下推到存储引擎),但逻辑意义遵循以上顺序。
ON与WHERE的区别:ON常用于连接条件(可以影响是否为外连接保留行);WHERE在连接后对整行做最终过滤。
8. MySQL 中的数据排序(ORDER BY)是如何实现的?
两种主要方式:
- 走索引顺序(避免 filesort):
- 当
ORDER BY的列正好与一个可用索引的左前缀相匹配,并且排序方向与索引一致,且查询没有要求额外的排序列或必须在不同表之间合并排序,优化器可以直接按照索引读取数据,无需显式排序(称为 “Using index”)。 - 覆盖索引(索引包含所有 SELECT 列)还能避免回表。
- 当
- Filesort(外部排序):
- MySQL 会把需要排序的记录(或键)取出来,放到内存(sort_buffer)里排序;如果超出内存,会使用临时文件(磁盘)进行外部排序。EXPLAIN 会显示
Using filesort。 - 实现常见为 quicksort/mergesort 的变体:对于 large datasets,会分段排序并归并(外部排序)。
- 若查询还需要 group by + order by,会可能生成临时表(
Using temporary),再排序。
- MySQL 会把需要排序的记录(或键)取出来,放到内存(sort_buffer)里排序;如果超出内存,会使用临时文件(磁盘)进行外部排序。EXPLAIN 会显示
- 优化点:
- 为 ORDER BY 列建立合适的索引(左前缀),并尽量让查询使用覆盖索引,能显著避免 filesort。
- 减少 sort_buffer_size 不要盲目增大;更好的方法是优化索引与 SQL。
- EXPLAIN 线索:
Using filesort→ 排序发生(可能开销大)。Using index与Using where等组合能提示是否能走索引避免排序。
9. 为什么阿里巴巴 Java 手册不推荐使用存储过程?
基于工程实践的常见理由(多组织采用一致性观点):
- 可维护性差:业务逻辑分散在应用代码与数据库存储过程里,版本控制、代码 review、测试、CI/CD 管理不便。
- 可测试性差:存储过程难以做单元测试,缺少成熟的构建/测试生态。
- 可移植性差:不同数据库的存储过程语法差异大,锁定供应商(vendor lock-in)。
- 复杂逻辑不适合:复杂业务逻辑写在 DB 层会降低可读性、让 DB 成为业务瓶颈。
- 伸缩性限制:数据库的横向扩展(读写分离、分库分表)会使存储过程管理复杂;应用层更易于水平扩展。
- 运维与安全:频繁修改存储过程需要谨慎部署,不当操作可能影响全表数据。
但并不是绝对禁止:存储过程在某些场景仍有价值(复杂的数据库内聚合计算、减少网络往返、一些数据临近处理),关键是权衡与团队能否做好治理(版本管理、测试与文档)。
10. 如何实现数据库不停服迁移?
常见做法与工具(线上敏感操作的通用流程):
A. Schema 变更(DDL 无停机化策略):
- 使用在线 DDL 工具:gh-ost、pt-online-schema-change(pt-osc)(Percona),原理通常是:
- 创建目标结构的 shadow 表(新表)。
- 全量复制旧表数据到新表(分批、无锁读取)。
- 使用触发器或 binlog 双写在复制期间捕获并应用变更(保持同步)。
- 切换(RENAME TABLE 原子操作)完成替换(极短时间锁),或利用应用层路由切换表名。
- 清理旧表与中间对象。
- MySQL 新版本支持 instant / in-place DDL(对部分操作如某些 ADD COLUMN 可瞬时完成),要根据 MySQL 版本能力安排。
B. 数据迁移(不停服搬库):
- 使用逻辑复制/同步:
- 使用 replica(基于 binlog)把流量从老库写到新库,切换读写角色(master-master / master-slave 切换),或多写短期双写,最后切走流量。
- 使用工具:gh-ost, pt-osc, MaxScale, Canal, Debezium(CDC)等。
- 使用物理复制/备份恢复:
- 使用
Percona XtraBackup做热备恢复到新实例,再提升为主库(需注意 binlog 位点迁移与增量)。
- 使用
- 切换策略:
- 先做读切换:把只读流量切到新库进行验证。
- 再短暂降级写或使用双写/幂等写策略,最终切换写主。
- 最后回放或同步最后的 binlog。
实战注意:
- 自动化、灰度:分阶段灰度切换,避免一次性切换全量流量。
- 监控与回滚:详细监控(延迟、错误率),支持快速回滚方案。
- 数据一致性验证:使用 checksum(pt-table-checksum)等验证数据一致性。
- schema migration 工具链:Liquibase/Flyway 管理 schema 版本,配合在线 DDL。
- 压力与资源:复制过程中会对源库添加额外负载,提前评估资源与窗口。
11. UNSIGNED 属性有什么用?
- 只适用于整数类型(TINYINT/SMALLINT/MEDIUMINT/INT/BIGINT):
UNSIGNED表示无符号,范围从 0 到 2^N − 1(例如 INT UNSIGNED 范围 0 ~ 4294967295)。 - 作用:把同样字节数的上限往正数方向翻倍(允许更大正数),但不能存负数。
- 注意点:
- 查询/比较时注意有符号与无符号的比较规则(有时会隐式转换)。
- 与应用语言映射(Java 的 int 是有符号)要小心越界与类型不匹配。
- 存储大小(字节数)不变,只有数值范围变化。
12. MySQL 中 int(11) 的 11 表示什么?
(11)只是显示宽度(display width),仅在与ZEROFILL一起使用时生效(会用前导零补齐到显示宽度)。并不影响存储大小或范围。- 实际存储仍由 INT 类型决定(4 字节)。
- 从 MySQL 8.0.17 起,整数显示宽度已被弃用(除了 TINYINT(1) 的布尔习惯),因此不要依赖这个数字表示精度或范围。
13. CHAR 与 VARCHAR 有何区别?
- CHAR(n):
- 固定长度(n 个字符),存储时不足部分用空格填充(右填充)。读取时空格可能被忽略(在比较与一些行为中)。
- 适合长度固定的小字段(例如国家码、固定码)。
- 存取更简单、性能稳定(少指针/长度字节开销)。
- VARCHAR(n):
- 可变长度,用 1 或 2 字节保存长度前缀(长度 ≤ 255 用 1 字节,≥256 用 2 字节,取决于实际定义与字符集),存储仅占用实际字符 + 前缀字节。
- 适合变长字符串(名字、描述等)。
- 存储与索引注意:
- InnoDB 行最大长度限制(受整行 65KB 限制影响),长 VARCHAR 可能 off-page(BLOB/TEXT 处理类似)。
- CHAR 比 VARCHAR 更适合短且固定的值;VARCHAR 更节省空间但带有长度前缀。
14. VARCHAR(100) 与 VARCHAR(10) 的区别?
- 主要差别是允许的最大长度(100 vs 10 字符),以及索引前缀限制和潜在行大小影响。
- 实际影响:
- 若使用 UTF8/utf8mb4,100 字符可能最多占用 400 字节(4 bytes/char),会影响最大行大小与索引长度(索引长度以字节计算)。
- 索引时若
VARCHAR(100)太长,可能需要指定索引前缀(INDEX(col(50)))以不超过索引长度限制。 - 性能上,若字段大且频繁被读取,IO 与缓存压力更大。
- 建议:为字段设置合理上限(既能容纳业务数据又不过分浪费),并考虑字符集的字节长度。
15. DECIMAL 与 FLOAT/DOUBLE 的区别?
- DECIMAL:
- 定点(精确)数值,用于金融场景避免舍入误差(用人眼可理解的十进制精度)。在 MySQL 内部通常以压缩的二进制形式或 BCD packs 存储(每几个十进制位打包),不是 IEEE 浮点。
- 定义如
DECIMAL(M,D):总位数 M,小数位 D(注意 M 包括小数点两侧总位数)。 - 优点:精确、适合金钱。缺点:运算可能比浮点慢,存储更复杂。
- FLOAT / DOUBLE:
- 浮点数(近似),基于 IEEE 754,表示为二进制近似。
FLOAT单精度,DOUBLE双精度。 - 适合科学计算、需要范围大但对微小舍入误差可容忍的场景。
- 浮点数(近似),基于 IEEE 754,表示为二进制近似。
- 结论:存金额用 DECIMAL(或整数 cents),浮点用于近似计算。
16. DATETIME 与 TIMESTAMP 的区别?
- 存储范围与字节:
DATETIME:可表示'1000-01-01 00:00:00'到'9999-12-31 23:59:59'(8 字节传统实现;自 5.6 支持微秒扩展)。TIMESTAMP:通常以 UTC 的 Unix 时间戳为基础(较早实现 4 字节,范围受限制大约 1970-2038 在某些实现),MySQL 新版本扩展也有改进。
- 时区处理:
TIMESTAMP会根据连接/服务器时区进行存储时转换(存储为 UTC,显示时转换为当前会话时区),因此适合表示“瞬间(时点)”。DATETIME不会随时区自动转换,存储的是“本地时间点”。适合表示固定本地时间,如日程表(不希望时区转换)。
- 默认值 / CURRENT_TIMESTAMP:
TIMESTAMP更早支持CURRENT_TIMESTAMP作为默认值/自动更新;现代 MySQL 已允许DATETIME使用CURRENT_TIMESTAMP(从 5.6.5 起)。 - 建议:
- 表示事件时间点(跨时区)使用
TIMESTAMP或统一存 UTC(并在应用层转换)。 - 表示本地日历时间或无时区语义用
DATETIME。
- 表示事件时间点(跨时区)使用
17. NULL 与 '' 有什么区别?
NULL:未知/缺失值;不是值,表示“没有值”。- 与任何比较(
=,<>)的结果为NULL(即未知);必须使用IS NULL/IS NOT NULL判断。 - 聚合函数(如
SUM,AVG)通常忽略 NULL 值;COUNT(col)不计 NULL,COUNT(*)计行数包括 NULL 列。
- 与任何比较(
'':空字符串,是一种确定的值(长度 0 的字符串),不等于 NULL。- 索引与存储:NULL 在索引中有特殊表示;空字符串按照字符存储。
- 实践:语义不同 — 把“未填写”与“填写为空字符串”区分开来通常更有意义。尽量选择一种约定并统一(例如允许 NULL 表示未填写)。
18. Boolean 类型在 MySQL 中如何表示?
- MySQL 中没有独立的原生
BOOLEAN存储类型;BOOLEAN是TINYINT(1)的别名(0 假/false,非 0 为 true 通常视为 true)。 - 也可以用
BIT(1)来代表布尔(但读写和表达上需要注意转换)。 - 实践:习惯用
TINYINT(1)或在应用层把 0/1 映射为 false/true。
19. 为什么不推荐使用 TEXT 和 BLOB?
原因与权衡:
- 索引限制:不能对整列做索引(需要前缀索引),并且索引长度受限(与字符集、InnoDB 页布局相关);全文检索需专门的全文索引或 ElasticSearch。
- 性能与 IO:大对象(LOB)多数情况下会被存放到页外(off-page),增加额外 IO 与指针回访成本;排序/分组涉及临时表时可能导致大量磁盘 I/O(临时表落盘)。
- 内存/缓存问题:查询含大字段会拉大内存使用(临时表、buffers、网络传输),影响并发能力。
- 可维护性:大对象在备份/恢复/复制时显著增加备份大小与时间。
- 替代方案:若文件较大(图片、音频、视频),通常推荐把文件放在对象存储(S3/OSS)或文件系统,并在 DB 中保存引用 URL/元数据;若确实需要 DB 存储(事务性要求),可以用 BLOB,但需注意分块/流式处理。
实践建议:短文本用 VARCHAR;长文本搜索用专门搜索引擎(Elasticsearch)或 InnoDB 的全文索引;大二进制数据建议外部存储。
20. 在 MySQL 中存储金额应使用什么数据类型?
- 推荐:
DECIMAL(precision, scale)(例如DECIMAL(13,2)或DECIMAL(10,2)视业务而定),因为 DECIMAL 提供精确的十进制表示,避免浮点舍入误差。 - 备选:整型存“最小单位”(例如 cents),用
INT或BIGINT存储(性能好,简单准确),显示时按 100/1000 转换。 - 建议:选定单位与精度并在全系统一致使用(数据库、API、前端)。
21. MySQL 如何存储 IP 地址?
IPv4:
存为整数:
INT UNSIGNED+INET_ATON()/INET_NTOA()函数转换。优点:占用 4 字节、索引速度快。1
2INSERT INTO t (ip) VALUES (INET_ATON('192.168.0.1'));
SELECT INET_NTOA(ip) FROM t;
IPv6:
- 使用
VARBINARY(16)(或BINARY(16)),使用INET6_ATON()/INET6_NTOA()进行转换(兼容 IPv4/IPv6)。也可用CHAR(39)存文本表现,但二进制更紧凑且便于索引。
- 使用
注意:比较与排序最好保持二进制/整数形式,减少字符串处理开销;存储时要考虑字节序(INET_ATON/NTOA 处理好)。
22. 什么是数据库视图?
- 视图(VIEW):基于 SQL 查询的虚拟表,定义后可以像表一样查询。视图并不总是存储数据(除非是物化视图,MySQL 本身不原生支持物化视图)。
- 用途:
- 抽象复杂查询、封装业务逻辑、权限控制(给用户只读视图)、简化客户端查询。
- 类型:
- 可更新视图:在满足一定条件时(单表、无聚合、无 DISTINCT、无 GROUP BY、无 LIMIT 等)可以通过视图执行 INSERT/UPDATE/DELETE。
- 不可更新视图:含聚合、分组、连接等,不能直接更新。
- 性能:视图是查询的“别名”,执行时会把视图展开为真实查询,复杂视图会带来性能影响;对于频繁计算的大查询,可以考虑物化策略(手工维护的物化表)。
23. 什么是数据库游标?
- 游标(Cursor):在存储过程/函数或数据库会话中用于逐行处理结果集的机制。游标允许你在 PL/SQL/存储过程里按顺序取出行并逐行处理。
- MySQL 游标特点:
- 在存储过程中
DECLARE cursor_name CURSOR FOR select_statement; OPEN cursor_name; FETCH cursor_name INTO ...; CLOSE cursor_name; - MySQL 的游标通常是只进/只读(forward-only, read-only),不像高级 DB(Oracle)支持可滚动游标。
- 在存储过程中
- 使用场景:需要逐行处理复杂逻辑、触发器或批量逐行迁移(但通常行处理效率差,优先考虑集合式 SQL 方案)。
- 性能提示:尽量避免在大数据量上使用游标逐行处理,改为批量 SQL 或应用层并行处理更高效。
24. 为什么不建议直接存储大对象(图片 / 音频 / 视频)?
主要问题:
- 备份/恢复压力:数据库备份会包含这些大文件,导致备份体积和恢复时间急剧上升。
- 性能与 IO:读写 BLOB 需大量 IO,影响数据库的整体响应性能;大对象导致内存/网络传输压力。
- 可扩展性:数据库扩容成本高;通常对象存储(S3/OSS)更易横向扩展、CDN 分发。
- 费用:托管 DB 存储成本高于对象存储系统。
- 替代方案:将大对象存对象存储或 CDN,数据库仅保存元数据(文件路径/URL、校验信息、版本)。
但有例外:若强事务一致性要求非常高或小文件数量有限,存 BLOB 有时更方便(例如需要事务回滚把文件也回滚),需评估权衡与方案。
25. 数据库的三大范式(1NF / 2NF / 3NF)是什么?
第一范式(1NF):
- 要求表中每个字段都是原子值(atomic),不能是集合或重复列。
- 例如,不应该有
phones字段保存多个电话号码(而应该拆成多行或独立表)。
第二范式(2NF):
- 在满足 1NF 的前提下,每个非主属性完全依赖于主键(解决部分依赖)。
- 针对复合主键:不能让非主属性只依赖于部分键。若有部分依赖,应拆表。
第三范式(3NF):
- 在 2NF 基础上,消除传递依赖(非主属性不能依赖于其他非主属性)。即每个非主属性直接依赖主键。
- 例如表
order(order_id, customer_id, customer_name),customer_name依赖于customer_id(非主属性→非主属性依赖),应拆成customer表。
补充:
- BCNF(Boyce–Codd NF) 更强,要求每个决定因素都是候选键。
- 范式优点:减少数据冗余,避免更新异常(插入/删除/更新异常),提高数据一致性。
- 范式代价 / 实战:
- 过度范式化会导致大量 join(性能开销),在 OLTP/OLAP/高性能场景常采用 适度反范式化(为查询性能牺牲部分冗余),并通过应用/触发器保证一致性或使用 ETL 保持数据同步。
- 实际设计通常是「第三范式为主,针对性能热点做有控制的反范式化或采用缓存/聚合表」。
最后:实战建议(综合)
- 生产数据库首选 InnoDB,设计表时优先考虑事务一致性与索引策略。
- 对 SQL 性能:学会用
EXPLAIN/EXPLAIN ANALYZE、慢查询日志、profiling 工具(pt-query-digest)定位问题;避免 SELECT *、滥用子查询;合理设计索引与覆盖索引。 - 对大数据/大对象:避免将大量二进制内容放 DB;使用对象存储 + DB 存元数据。
- Schema 变更:使用 gh-ost/pt-osc/ONLINE DDL 工具实现不停服。
- 金额用 DECIMAL 或 integer cents;IP 用整型或 VARBINARY(16);时间点用 TIMESTAMP(或统一存 UTC)。
JVM-牛客面经八股
JVM结构图
创建一个新对象 内存分配流程
1) JVM 内存模型(运行时数据区)——深入
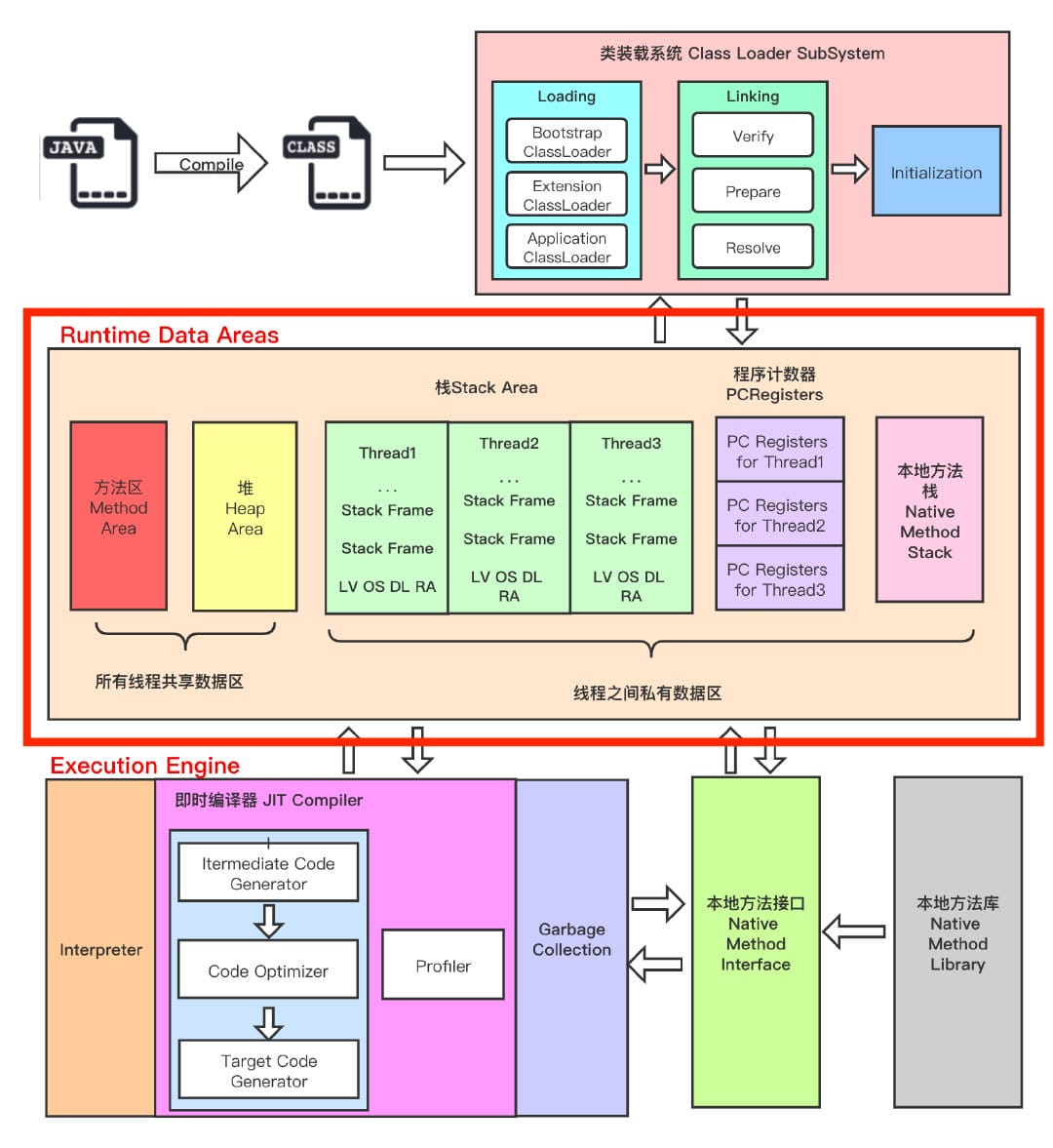
JVM 将运行时数据区分为线程私有和多线程共享两类。
线程私有区域
- 程序计数器(PC):每线程一份,记录下一条要执行的字节码指令地址(用于执行字节码的分支控制)。如果线程在执行本地方法,该寄存器值为 undefined。
- 虚拟机栈(JVM Stack):每个线程一个栈,栈帧包含局部变量表、操作数栈、动态连接和方法返回地址。局部变量表保存基本类型和对象引用。栈溢出会抛出
StackOverflowError。 - 本地方法栈(Native Stack):专门用于处理本地方法(C/C++实现)调用的栈(HotSpot 在实际实现上可与 JVM Stack 合并或分开实现)。
多线程共享区域
- 堆(Heap):存放对象实例与数组,是 GC 管理的主要区域。堆细分为**年轻代(Eden + Survivor0/1)*和*老年代(Tenured)。堆还可能包含永久代或元空间(见下)。
- 方法区(Method Area)/元空间(Metaspace):存放类的元数据(Class 对象、常量池、静态变量、方法字节码)。JDK 8 起把 PermGen 替换为 Metaspace(在本地内存),可以通过
-XX:MaxMetaspaceSize限制。 - 直接内存(Direct Memory):不在 JVM 堆中,由
ByteBuffer.allocateDirect()等分配。虽然不在堆中,但会被本地内存耗尽导致 OOME(需要监控 native memory)。
重要细节
- 对象头(Mark Word + Klass Pointer)包含 GC 元信息(锁标记、哈希码、分代年龄等)和类指针(或 compressed klass pointer)。
- 对齐与压缩:
-XX:+UseCompressedOops(默认常开)影响对象引用大小与堆布局。 - 类加载器与类元数据泄露:类无法卸载的常见原因是类加载器仍有引用(静态集合、线程池、ThreadLocal 导致的 classloader leak)。
2) JVM 的垃圾回收算法
JVM 中常用/经典的 GC 算法原则与实现:
基础算法
- 引用计数(Reference Counting):为每个对象维护引用计数,计数为 0 时回收。缺点:无法处理循环引用。HotSpot 不采用此算法。
- 可达性分析(Trace-based):从 GC Roots 开始通过引用图遍历,标记活对象,未标记即回收。HotSpot 采用此方法。
回收策略
- 标记-清除(Mark-Sweep):标记所有可达对象,然后清除未标记对象。优点:实现简单;缺点:产生内存碎片。
- 标记-整理(Mark-Compact):标记活对象,然后将活对象压缩到一端,更新引用,消除碎片。适合老年代。
- 复制(Copying):把活对象从一个空间复制到另一个空间(两块半区或多个区),空出整个区域,避免碎片。优点:简单高效。常用于年轻代(Eden/Survivor)。
- 分代收集(Generational):根据对象存活期长短分代(年轻代/老年代)。年轻代使用复制算法(低成本),老年代使用标记-清除或标记-整理。因为大多数对象寿命短(弱生成假设),分代策略能显著提高性能。
现代收集器(概述)
- Serial GC:单线程收集,STW(Stop The World),适用于单核或小内存场景。
- Parallel(Throughput)GC:多线程并行回收,追求吞吐量,适合 batch、后台服务。
- CMS(Concurrent Mark-Sweep):并发标记清理,低暂停,使用并发阶段来减少 STW。已在新版 JDK 中被标注为过时/删除。
- G1(Garbage-First):把堆划分为 region,进行 region 级别回收与并行压缩,设计目标是可预测的暂停与高吞吐,现代服务器应用默认或推荐使用。
- ZGC / Shenandoah:以并发压缩为目标,追求极低停顿(几毫秒级甚至微秒级),适合超大堆与低延迟需求。
3) GC 的可达性分析
根(GC Roots)来源
- Java 虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 方法区中的静态引用(静态变量)。
- 本地方法栈或 JNI 中的引用。
- 运行时常量池中直接引用(部分实现)。
- 其他 JVM 内部持有的引用(例如 ClassLoader 的引用)。
引用类型的语义
- 强引用(StrongReference):普通引用,GC 不会回收强引用对象。
- 软引用(SoftReference):在内存不足时回收,适用于缓存(
SoftReference)。 - 弱引用(WeakReference):在下一次 GC 时就可能回收,适用于 canonicalized mappings 等。
- 虚引用(PhantomReference):对象被回收后会把引用加入引用队列,可用于在对象被回收后做清理(配合 ReferenceQueue),并且
get()返回 null。
遍历算法
- 从 GC Roots 开始做图遍历(BFS/DFS)标记所有可达对象;未标记即为垃圾。
- 优点:能处理循环引用(与引用计数对比),是 HotSpot 的主流做法。
- 一些优化:
- 增量/并发标记:把标记工作分阶段与应用线程并发执行,以减少 STW。
- 卡表(Card Table)跟踪写入屏障:在分代收集中用于记录跨代引用(例如老->新),推动并行或并发回收优化。
4) CMS (Concurrent Mark Sweep) 垃圾回收器 —— 细节与调优
目标:尽量减少与应用线程的 STW 停顿(低延迟),主要用于老年代收集(年轻代通常用并行收集 ParNew)。
CMS 工作阶段(常见实现顺序)
- 初始标记(Initial Mark) — STW:标记直接可达的对象(通常从根开始快速标记与 GC Roots 直接关联的对象);时间较短。
- 并发标记(Concurrent Mark) — 与应用线程并发:遍历引用图标记可达对象。
- 并发预清理(Concurrent Preclean) —(可选)修正并发期间的部分浮动垃圾。
- 重新标记(Remark) — STW:修正并发标记期间因应用线程持有或释放引用导致的漏标(这一步相对短于传统全量标记,因为大部分工作已并发完成)。
- 并发清理(Concurrent Sweep) — 与应用线程并发:清理未标记对象并维护空闲链表。
- 并发重置/重组(Concurrent Reset):准备下一次 GC。
实现细节与问题
- 不做压缩(默认):CMS 清理不会压缩老年代,因此会留下内存碎片。碎片问题可能导致“内存足够但无法满足连续大对象分配”从而触发 Full GC。
- 并发模式失败(Concurrent Mode Failure):如果 CMS 无法在合理时间内完成并发回收(例如分配速率非常高或堆碎片太多),会触发 fallback:做一次 STW 的 Full GC(通常由 Serial GC 或 Parallel Old 执行),其停顿可能很长。
- 并发标记期间的“floating garbage”:由于并发执行,某些对象在标记时刚好变为不可达或变得可达,需要 re-mark 来修正。
- 配套 Young Collector:CMS 常与
ParNew(并行年轻代收集器)配合使用以减少年轻代停顿。
常见调优参数(典型)
-XX:+UseConcMarkSweepGC:开启 CMS(旧 JDK)。-XX:+UseParNewGC:并行年轻代与 CMS 协同。-XX:CMSInitiatingOccupancyFraction=XX:触发 CMS 的老年代占用率阈值(百分比)。默认例如 68 或 75,通常设置为 60~75,视应用而定。-XX:+UseCMSInitiatingOccupancyOnly:只使用指定阈值(避免 JVM 自适应更改)。-XX:+CMSParallelRemarkEnabled:并行 re-mark,减少 remark 停顿。-XX:+CMSClassUnloadingEnabled:允许 CMS 在并发过程中卸载类并回收元空间中无用的 class 元数据(防止 metaspace 泄漏)。
排查 CMS 问题
- 频繁 Full GC / Concurrent Mode Failure:查看 GC 日志(
-Xlog:gc*或-XX:+PrintGCDetails),识别是否为 CMS 失败导致的 Full GC;增大堆或调高CMSInitiatingOccupancyFraction,或减少老年代占用速率(减少晋升/减少内存占用)。 - 碎片问题:增加老年代大小,或在 Full GC 时触发压缩(Full GC 通常会做 compact);考虑切换到 G1(自带整理能力)。
- 已被弃用/移除:注意在新版本 JDK(例如 JDK 14+)CMS 已被移除或标记弃用,应优先考虑 G1、ZGC 或 Shenandoah。
5) G1 收集器(Garbage-First)
目标:在大堆场景下提供可预测的停顿目标(低延迟)与高吞吐,同时减少碎片。JDK9+ 的默认回收器通常为 G1(视 JVM 版本而定)。
核心思想
- Region(区域):G1 把堆划分为等大小的 region(通常 1MB~32MB,自动根据堆大小选择),每个 region 可以被逻辑地视为 Eden/Survivor/Old。
- 记忆集(Remembered Sets, RSet):为了记录跨 region 的引用(比如老区指向年轻区),G1 使用 RSet 来快速定位哪些 region 可能引用某 region 的对象,以便并发/并行回收时正确处理根集合。
- 并发标记阶段 + 混合回收:
- 初始标记(STW):短暂停顿做 root scanning(与 Eden GC 同步)。
- 并发标记(Concurrent Mark):并发地标记可达对象,构建 liveness 信息和 region 的垃圾率估算。
- 重新标记(Remark):STW,修正并发期间变更。
- 并发清理(Cleanup):确定哪些 region 应该被回收/合并(形成 Evacuation Set)。
- 混合回收(Mixed GC):在并发阶段之后执行若干次混合回收,回收年轻代 region 以及一些老年代 region,直到满足堆回收目标。
- Evacuation(搬迁):G1 回收采用“复制/搬迁”策略,把选中的 region 中的存活对象复制到其他空闲 region(可合并 region),以避免碎片并保持连续可用空间。
- Humongous objects:大对象(大于 region size/2)被视为 humongous,会占用连续多个 region,并直接交付给老年代(并采用专门策略回收)。
G1 的优点
- 区域化管理,支持并行、并发、压缩(搬迁)操作,降低碎片概率。
- 可以设置
-XX:MaxGCPauseMillis作为目标,G1 会尝试在此暂停目标下选择回收区域集合以满足目标(并不能保证严格实现)。 - 支持并发标记并回收老年代(mixed GC),提高可预测性。
重要参数与调优
-XX:+UseG1GC:启用 G1(现代 JDK 常为默认)。-XX:MaxGCPauseMillis=<N>:G1 尝试将停顿控制到 N ms(软目标)。-XX:InitiatingHeapOccupancyPercent=<pct>(默认 ~45):并发标记触发阈值(当堆占用达到此百分比时启动 concurrent marking)。-XX:G1HeapRegionSize=<size>:region 大小,自动调整但可显式设置(1MB~32MB),影响 humongous 阈值与 remembered set 管理开销。-XX:ConcGCThreads/-XX:ParallelGCThreads:并发/并行线程数目,通常与 CPU core 配置有关。-XX:MaxTenuringThreshold:对象晋升阈值控制(与 Survivor 区的年龄策略相关)。
诊断与问题
- Humongous 分配问题:大量 humongous 对象可能导致 region 被大量占用并影响 G1 的效率;可考虑调整 region size 或改用分块存储。
- Remembered Set 开销:对于很多跨 region 引用(即对象分布极为分散或写入热点多),RSet 更新开销高。
- GC 日志分析:使用
-Xlog:gc*:file=gc.log(JDK9+)或-XX:+PrintGCDetails(老方式),并用 GC 分析工具(GCEasy、GCViewer、JClarity)查看 pause、mixed GC 次数、humongous 比例等。
6) 类加载机制(加载、链接、初始化)
加载(Loading)
- ClassLoader 读取类的二进制字节流,将其转换为
Class对象(在方法区/MetaSpace 存储元数据),并在 JVM 的方法区中创建相应的数据结构(方法、常量池、字段布局等)。
链接(Linking)
- 验证(Verification):确保字节流符合 JVM 规范(格式正确、语义不违背安全约束)。
- 准备(Preparation):为类的静态变量分配内存并赋默认值(但不执行显式初始值)。
- 解析(Resolution):把符号引用解析成直接引用(如类的全限定名解析为直接内存地址或指针)。解析可以是懒解析(首次使用时解析)。
初始化(Initialization)
- 执行类的
<clinit>方法(由编译器合成,包含 static 初始化器和静态字段的赋值语句),这是执行静态初始化的阶段。初始化由 VM 控制(线程安全,按需触发)。 - 什么时候触发初始化(例子):
- 首次主动使用(new、调用静态方法、读取/写入静态字段、反射调用 Class.forName 等)。
Class.forName()会强制初始化(除非用Class.forName(name, false, loader))。
类加载器层次
- Bootstrap(启动)类加载器:加载核心类库(JRE/lib) — C/C++ 实现,不是 Java 对象。
- Platform / Extension 类加载器(JDK 9+ 为 Platform loader):负责加载平台类。
- Application / System 类加载器:加载应用类路径(-classpath 指定路径)。
- 自定义类加载器:通过继承
ClassLoader覆盖findClass或loadClass来实现自定义行为(隔离、热部署、沙箱等)。
类卸载
- 类及其 ClassLoader 可以被卸载,前提是:
- 所有该类由其 ClassLoader 加载的类实例、静态引用、线程上下文等均被回收(ClassLoader 没有活跃引用)。
- 在 HotSpot 中,类卸载由垃圾回收触发(常在 Full GC 或并发标记期间进行);一些 GC(如 CMS、G1)支持类卸载(需要相应参数,如
CMSClassUnloadingEnabled在 CMS 中)。
- 常见导致类无法卸载问题:线程池未停止的线程持有 ThreadLocal 的引用、静态单例、JDBC 驱动未注销等。
7) 双亲委派模型 & 如何打破
双亲委派(Parent Delegation)机制
- 加载类的请求先委托给父加载器,如果父加载器无法加载再由子加载器尝试加载。目的:
- 保证核心类优先由 Bootstrap Loader 加载(安全性,避免自定义类覆盖 java.lang.*)。
- 简化类的唯一性管理,避免重复加载核心类。
实现流程(High-level)
ClassLoader.loadClass(name):- 检查缓存是否已加载。
- 如果未加载,委托给 parent.loadClass(name)(若 parent 存在)。
- 如果 parent 无法找到,再调用本地
findClass(name)去加载(子加载器)。
打破双亲委派的理由与方法
- 为什么要打破:某些容器(如应用服务器、插件框架、OSGi、Tomcat 的 webapp classloader)需要实现“子优先(child-first)”加载策略以隔离应用或实现热部署。
- 如何打破:
- 覆盖
loadClass:自定义ClassLoader重写loadClass方法,先尝试findLoadedClass和findClass(子加载器),若找不到再委托 parent。注意处理java.*或核心类仍应委托父加载器以避免安全风险。 - 在容器实现中使用 child-first 策略(Tomcat 中有设置),以便在 webapp 中优先加载 WEB-INF/lib/ classes。
- 覆盖
- 风险 & 问题:
- 类卸载与类型不兼容:若相同的类由不同 ClassLoader 加载,类的“身份”不同,会出现
ClassCastException(即使类名相同)。 - 安全风险:子加载器加载 core 类可能覆盖 JDK 内部类,带来安全隐患。
- 复杂性:对依赖关系的管理更复杂,特别是 native library 绑定与单例行为。
- 类卸载与类型不兼容:若相同的类由不同 ClassLoader 加载,类的“身份”不同,会出现
8) 出现 Full GC 的场景
Full GC(通常指触发了老年代回收和可能会做类/元空间回收或堆压缩的 STW)可由多种原因触发,常见包含:
内存与分配相关
- 老年代空间不足(老年代无法容纳晋升对象):当晋升失败或老年代碎片严重导致无法找到连续空间分配大对象。
- 空间被大量持久对象占满(例如缓存过大、未释放的集合、内存泄漏)。
- Promotion Failure / Allocation Failure:年轻代 GC 后向老年代晋升对象失败,可能触发 Full GC。
- 太多 Humongous 对象(G1 / region-based):大对象占据大量 region,影响分配/回收,进而触发 Full GC。
元空间(Metaspace)或永久代(PermGen)
- Metaspace/PermGen 用尽:类/字节码元数据分配失败会触发 Full GC 来尝试回收类并卸载无用类(如果成功则释放空间),否则抛出
OutOfMemoryError: Metaspace。
显式或系统触发
- System.gc() / 显式垃圾回收请求:若未禁用显式 GC,会触发一次 Full GC(可通过
-XX:+DisableExplicitGC忽略)。 - 某些 VM 操作(如类卸载、某些 JNI 操作、资源限制检查)需要 Full GC。
GC 内部
- 并发回收器失败(Concurrent Mode Failure):例如 CMS 无法并发完成回收,会回退为 Full GC(STW)。
- 碎片化:尤其 CMS 未压缩导致碎片,分配大对象失败导致 Full GC。
- Native 内存压力或直接内存用尽:某些场景下 JVM 为回收资源触发 Full GC(例如清理 PhantomReference / finalizer 队列)。
其他
- Finalizer 队列阻塞:对象有
finalize()且 finalizer 执行滞后,可能导致大量对象等待 finalization,从而触发更多 GC。 - 虚拟机内建的阈值/策略:某些 GC 收集器根据内部策略在阈值到达时触发 Full 回收。
9) 常见的 JVM 参数
下面按功能分类给出常见参数、作用与典型取值建议:
堆内存与分代
-Xms<size>:初始堆大小(建议与 -Xmx 一致以避免扩容开销)。-Xmx<size>:最大堆大小。-Xmn<size>:年轻代大小(也可用-XX:NewSize/-XX:MaxNewSize)。-XX:NewRatio=n:老年代与年轻代比率(老:新 = n:1)。-XX:SurvivorRatio=n:Eden 与 Survivor 的比例。-XX:MaxTenuringThreshold=<n>:最大晋升年龄(决定对象在 Survivor 区停留的代数)。
GC 选择
-XX:+UseG1GC:使用 G1 收集器(现代推荐)。-XX:+UseParallelGC/-XX:+UseParallelOldGC:并行 GC,追求吞吐。-XX:+UseConcMarkSweepGC:CMS(旧)。-XX:+UseSerialGC:串行 GC(小堆、单线程场景)。-XX:+UseZGC/-XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC:新一代低停顿收集器(视 JDK 版本)。
GC 日志
- JDK8 及更早:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/path/gc.log
- JDK9+(统一日志):
-Xlog:gc*:file=/path/gc.log:time,uptime,level,tags
- 辅助:
-XX:+PrintTenuringDistribution、-XX:+PrintGCApplicationStoppedTime。
元空间 / 类加载
-XX:MetaspaceSize=<n>:触发第一次扩展的阈值(非上限)。-XX:MaxMetaspaceSize=<n>:最大元空间大小(否则可能导致 OOME)。-XX:+TraceClassLoading/-XX:+TraceClassUnloading:调试类加载/卸载。
诊断 & 堆转储
-XX:+HeapDumpOnOutOfMemoryError:OOM 时自动 dump heap。-XX:HeapDumpPath=/path/dump.hprof。-XX:+DisableExplicitGC:忽略System.gc()调用。-XX:+PrintFlagsFinal:打印最终生效的 JVM 参数。
JIT 与调优
-XX:+PrintCompilation、-XX:+LogCompilation、-XX:+PrintInlining、-XX:CompileThreshold(编译阈值)。-XX:+AggressiveOpts(试验性,不推荐在生产)。
线程与并行
-XX:ParallelGCThreads=<n>:GC 并行线程数(与 CPU 相关)。-XX:ConcGCThreads=<n>:并发 GC 的线程数(G1/ZGC 等适用)。-Xss<size>:每个线程栈大小(注意线程数多时总内存消耗)。
容器 / 限制相关
-XX:+UseContainerSupport/-XX:MaxRAMPercentage/-XX:InitialRAMPercentage:针对容器和 cgroup 的内存配额支持(现代 JDK)。
性能增强
-XX:+UseCompressedOops:压缩指针(默认通常启用),降低内存占用。-XX:+UseStringDeduplication(G1):启用字符串去重,降低堆中重复字符串内存占用(需要配合 G1)。
10) JDK 的监控工具 & 线上处理实战案例(诊断步骤与 runbook)
下面用常见问题场景(CPU、内存泄漏、频繁 Full GC、死锁)来给出可复用的线上诊断步骤、命令与处置策略。
常用工具(一句话)
jps:列出 Java 进程(PID)。jstack <pid>:线程栈(死锁/线程阻塞/CPU 占用)。jmap -histo[:live] <pid>:堆中对象统计(按类计数,live只列存活对象)。jmap -dump:format=b,file=heap.hprof <pid>或jcmd <pid> GC.heap_dump file:导出堆快照(用于 MAT 分析)。jcmd:功能强大,可触发 GC、打印系统属性、堆信息、执行诊断命令(jcmd <pid> GC.heap_info、VM.system_properties、Thread.print等)。jstat -gc <pid> <interval>:实时查看 GC 活动(年轻代、老年代使用情况)。jconsole/VisualVM:图形化监控(JMX)。jcmd GC.run:触发 GC。jcmd VM.native_memory summary:查看 native 内存使用(需要-XX:NativeMemoryTracking=detail启动)。- 第三方工具:Arthas(线上探查、方法级追踪、实时 heapdump)、async-profiler(采样 CPU / JIT 火焰图)、MAT(Heap分析)。
场景 1:CPU 突增
诊断步骤
top/ps确认 Java 进程 CPU 占用。jstack -l <pid> > threaddump.txt(收集多个间隔 5s 的线程快照更有价值)。- 分析线程 dump:找出 RUNNABLE 的热点方法(循环、I/O、锁竞争)。
- 若需要更精确调用占比,使用
async-profiler生成火焰图,或perf(Linux)做系统级采样。
快速处置
- 若是 GC 占用:查看 GC 日志(
jstat/ gc.log),若频繁 GC,考虑增加堆、调整 genç 大小或切换收集器。 - 若是代码热点:优化代码(减少同步、减少阻塞 I/O、提高并行度),使用缓存或限流策略。
场景 2:内存泄漏(持续内存增长 / OOM)
诊断步骤
- 查看内存使用趋势(
jstat -gc或监控系统)。 - 导出堆快照(
jcmd <pid> GC.heap_dump file或jmap -dump)。注意:堆 dump 操作可能会消耗大量 IO 和临时内存,生产上谨慎执行并提前协调维护窗口/流量降级。 - 用 MAT(Eclipse Memory Analyzer)分析 dominator tree,找出最大的保留者(retained size)并沿引用链定位泄漏源(常见是静态集合、ThreadLocal、缓存、未关闭的资源)。
- 查看类加载器统计(
jcmd <pid> VM.class_histo或jmap -clstats),判断是否类或 classloader 泄漏(热部署后的 webapp 卸载失败常见)。
处置
- 释放占用:清除缓存、关闭连接、停止线程,以便对象可被收集。
- 修复代码:使用弱引用或显式资源管理(try-with-resources)、确保在 webapp undeploy 时清理静态引用与线程。
- 监控回归,增加单元/集成测试覆盖内存留存场景。
场景 3:频繁 Full GC / GC 瘫痪(应用停顿)
诊断
- 检查 GC 日志:
-Xlog:gc*或-XX:+PrintGCDetails。识别是 Full GC、CMS ConcurrentModeFailure、还是晋升失败。 jstat -gc查看年轻代/老年代使用比例、晋升速率。jmap -histo看增长的对象类型(是否有大量短期大对象导致频繁晋升)。- 检查 Metaspace 是否耗尽(
jcmd <pid> VM.system_properties+-XX:MaxMetaspaceSize)。
处置
- 增加堆或调整分代大小(
-Xmx,-Xmn)、或切换 G1 并调InitiatingHeapOccupancyPercent。 - 若是碎片化(CMS 特有),考虑暂时触发 Full GC 以 compact,或迁移到 G1。
- 优化代码以减少大对象分配、减少晋升速率(晋升失败),或使用对象池。
- 禁用显式 GC(
-XX:+DisableExplicitGC)。
场景 4:死锁 / 线程阻塞
诊断
jstack -l <pid>:查看 BLOCKED/WAITING/ TIMED_WAITING 线程,寻找循环等待锁的线程堆栈。jstack输出中Found one Java-level deadlock会标明死锁详情。
处置
- 临时:重启受影响线程或整个服务(如果可承受)。
- 根治:查找锁顺序,改进锁策略(减少锁持有时间、使用更细粒度锁或无锁结构),增加超时与监控报警。
现场常用命令模板(示例)
1 | # 列出 Java 进程 |
生产注意事项
- 堆 dump、jmap 等可能引起停顿并占用额外磁盘/内存;在高可用场景下先流量降级或在副本上运行诊断。
- 建议在生产环境启用可控 GC 日志(并定期轮转)与 JMX 暴露指标,结合监控平台(Prometheus/Grafana)和 APM(比如 Pinpoint, SkyWalking)做长期趋势分析。
- 使用
jcmd的命令集优于老旧jmap/jstack功能更强,且适配新 JVM。
总结与推荐(面试与线上实战要点)
- 理解内存模型 是定位 OOM、内存泄漏与调优 GC 的基础(知道对象在哪、什么时候晋升、元空间的影响)。
- 分代策略 解释了为什么年轻代短 GC(复制)与老年代不同(标记/清理/整理)。
- CMS 与 G1 的差异:CMS 低停顿但易碎片;G1 更适合大堆与可控停顿,企业建议以 G1 为首选(或在更低停顿需求下考虑 ZGC/Shenandoah)。
- 线上诊断:熟练使用
jstack,jcmd,jmap,jstat,并结合 GC 日志与堆分析工具(MAT / async-profiler)是工程师必备能力。 - 工程实践:默认把
Xms=Xmx、启用 GC 日志(统一日志-Xlog),避免 System.gc,监控元空间与直接内存,做好容器/VM 限制适配(cgroup-aware flags)。
11)常见OOM(内存溢出)
1. Java 堆内存溢出(Java heap space)
- 原理:
Java 堆用来存放对象实例,当不断创建新对象且 GC 无法回收时,就会导致堆空间耗尽。 - 常见场景:
- 集合类(如
List/Map)中存放了大量对象但未释放(内存泄漏)。 - 无限循环创建新对象。
- 缓存设计不合理(未设置过期策略)。
- 集合类(如
- 排查方式:
jmap -heap <pid>查看堆内存使用情况。jmap -histo <pid>查看对象数量分布。MAT(Memory Analyzer Tool) 分析堆 dump。
- 解决方案:
- 优化代码,避免内存泄漏。
- 增加 JVM 堆内存:
-Xmx。 - 引入缓存淘汰策略(LRU、TTL)。
2. GC overhead limit exceeded
- 原理:
GC 占用过多时间但回收效果极差(例如 98% 的时间在 GC,回收的内存却小于 2%)。 - 常见场景:
- 内存几乎被占满,不断发生 Minor/Full GC。
- 内存泄漏导致垃圾对象无法被回收。
- 排查方式:
- 查看 GC 日志 (
-XX:+PrintGCDetails)。 - 检查是否有大对象频繁分配。
- 查看 GC 日志 (
- 解决方案:
- 优化代码,减少对象频繁创建。
- 调整堆大小。
- 排查内存泄漏。
3. Metaspace OOM(PermGen OOM,Java 8 之前叫 PermGen space)
- 原理:
Metaspace(元空间)用于存放类的元数据、方法区信息。若动态生成过多类,或者类加载器泄漏,元空间会被占满。 - 常见场景:
- 大量反射、动态代理。
- 应用频繁部署但类卸载失败(Tomcat 热部署)。
- 框架生成过多字节码(如 CGLIB、Javassist)。
- 排查方式:
jmap -clstats <pid>查看类加载信息。- Dump 分析哪些类加载器没有释放。
- 解决方案:
- 增加
-XX:MaxMetaspaceSize。 - 避免频繁动态生成类。
- 修复类加载器泄漏问题。
- 增加
4. Direct Buffer Memory OOM
- 原理:
NIO 的ByteBuffer.allocateDirect会申请堆外内存,若申请过多超过-XX:MaxDirectMemorySize限制,就会 OOM。 - 常见场景:
- Netty、大量使用 NIO。
- 文件/网络缓冲区分配不当。
- 排查方式:
- 观察是否有 DirectByteBuffer 未释放。
jconsole/Arthas监控。
- 解决方案:
- 显式调用
ByteBuffer.cleaner()释放堆外内存(JDK9+ 自动管理)。 - 合理配置
-XX:MaxDirectMemorySize。 - 避免频繁分配大块堆外内存。
- 显式调用
5. unable to create new native thread
原理:
JVM 进程申请新线程时,需要操作系统分配本地内存栈。如果线程数过多,系统资源耗尽,就会报错。
常见场景:
- 创建了大量线程(如线程池配置不合理)。
- 每个线程栈内存(
-Xss)过大。
排查方式:
top -H -p <pid>查看线程数。jstack打印线程堆栈。
解决方案:
- 使用线程池控制线程数量。
- 降低
-Xss设置,减少每个线程的栈空间。 - 使用异步或事件驱动模型代替大量线程。
6. StackOverflowError
- 原理:
方法调用层级过深,导致线程栈内存溢出。 - 常见场景:
- 无限递归调用。
- 方法嵌套过深。
- 排查方式:
- 查看异常堆栈。
- 检查递归出口条件。
- 解决方案:
- 修复递归逻辑。
- 调整栈大小:
-Xss。
7. OOM: Map Failed
- 原理:
堆外内存(mmap 文件映射)申请失败。 - 常见场景:
- 大文件映射(
MappedByteBuffer)。 - 系统虚拟内存不足。
- 大文件映射(
- 排查方式:
- 查看 OS 虚拟内存使用情况。
- 解决方案:
- 使用流式 IO 替代全量映射。
- 增加虚拟内存。
🔍 总结面试高频考点
- 堆内存溢出(最常考)
- GC overhead limit exceeded
- Metaspace OOM(类加载相关)
- Direct buffer memory OOM(堆外内存)
- unable to create new native thread(线程数过多)
- StackOverflowError(递归)
Redis-牛客面经八股
1. Redis 的数据类型
Redis 提供多种内建数据类型与高级数据结构(模块除外):
- String
- 二进制安全,最大可达 512MB。
- 用途:缓存、计数器、序列化对象、分布式限流/锁等。
- List
- 双端链表(old impl)→ 现在是 quicklist(ziplist/listpack + linked list 的混合实现)。
- 支持
LPUSH/RPUSH、LPOP/RPOP、LRANGE等,适合消息队列(阻塞BLPOP)。
- Set
- 无序集合,内部用哈希表实现。
- 支持集合运算
SINTER/SUNION/SDIFF。
- Sorted Set (ZSet)
- 有序集合:每个 member 有一个 score,支持按 score 排序。
- 内部实现:跳表 (skiplist) + 哈希表(dict)(hash: member→score;skiplist 用于按 score 快速范围查询)。
- Hash
- 字段集合(类似小型对象 / map)。
- 小 hash 使用紧凑编码(ziplist / listpack);大 hash 使用哈希表。
- Bitmap
- 用 String 的位操作实现(
SETBIT/GETBIT/BITCOUNT/BITOP)。常用于海量用户标记、UV/活跃用户统计(配合 bitset)。
- 用 String 的位操作实现(
- HyperLogLog
- 基数估算(基于概率,固定内存 ~ 12KB),用于 UV 去重估算(
PFADD,PFCOUNT)。
- 基数估算(基于概率,固定内存 ~ 12KB),用于 UV 去重估算(
- Stream
- Redis Streams(日志式数据结构)支持 append-only 记录、ID、Consumer Groups(可靠消费、ACK、pending)、适合消息队列/事件流。
- 内部:rax(radix tree) 映射 ID->listpack,entry 存于 listpack(紧凑结构)。
- Geo
- 基于 Sorted Set 的地理位置 API(
GEOADD/GEORADIUS),score 存编码后的经纬度。
- 基于 Sorted Set 的地理位置 API(
- Modules
- 可以通过模块增加类型(RedisJSON、RedisTimeSeries、RediSearch 等)。
工程要点
- 小集合尽量利用紧凑编码(减少内存),但超过阈值会切换成普通哈希/zip 切换(可通过配置调整阈值)。
- 用正确类型匹配场景:排行榜用 ZSet;计数器与短字符串用 String;High-cardinality 用 HyperLogLog。
2. Redis 单线程架构(详解 + 现代补充)
核心点
- Redis 在命令的解析与执行上是单线程的:所有命令的逻辑执行(读写内存、更新数据结构)都在主线程顺序执行,这带来两个重要效果:
- 简化并发控制:无需对象级锁,避免竞态与复杂锁逻辑。
- 单个请求执行不会被其它命令打断(除非调用阻塞或 fork 等)。
- I/O 多路复用:单线程用
epoll/kqueue/select等事件机制处理网络连接(read/write 的 readiness)。常见实现为ae事件库。 - 耗时/阻塞操作处理:
- 持久化操作(RDB save、AOF rewrite)通过 fork 子进程 在后台做,子进程写文件;父进程继续服务(写入过程会 copy-on-write 增加内存)。
- 从 Redis 6 开始,引入了I/O 线程(networking threads) 可选地并行处理 socket read/write(把网络 IO 的读写解包/组包放到 IO 线程),但命令执行仍在主线程;这可以提升高并发小命令场景下的吞吐。
- Redis 也可能使用后台线程做某些任务(例如 RDB/AOF rewrite、lazy free、lazy migration 等),但数据结构修改仍是单线程保证原子。
优缺点
- 优点:实现简单、命令原子性强、易预测。
- 缺点:单线程 CPU 瓶颈(但实际 Redis 单命令耗时很短、并可以用多实例/分片/Cluster 横向扩展)。
3. Redis 的持久化策略(RDB / AOF / 混合)
- RDB(快照)
SAVE/BGSAVE生成数据集快照(RDB 文件)。- 优点:文件紧凑、恢复速度快、对 Redis 运行影响小(BGSAVE 使用 fork,父进程继续服务)。
- 缺点:可能丢失自上次快照以来的写(数据不够实时);fork 时内存复制(写时复制)会消耗内存。
- AOF(Append Only File)
- 将写命令追加到文件(每条命令的 Redis 协议表示)。
- 持久化策略(fsync):
always(每次命令 fsync)——最安全但最慢;everysec(默认)——每秒 fsync,一致性稍弱,但性能好;no(操作系统决定)——最快但最不安全。
- AOF 支持重写(rewrite)来压缩历史命令(生成紧凑的 AOF),这个过程在后台
bgrewriteaof实现。 - 优点:更小的数据丢失窗口,恢复时以 AOF 重演命令(可设置
no-appendfsync-on-rewrite)。 - 缺点:文件大、重写会开销大,恢复速度比 RDB 慢(但可配置重写和重写压缩)。
- RDB + AOF
- 你可以同时开启 RDB 与 AOF;常见做法:以 RDB 为主备份、AOF 提升数据安全性。也可在 AOF 重写和 RDB 快照间做权衡。
- 持久化选型建议
- 对可接受少量数据丢失(例如缓存)可只用 RDB 或关闭持久化;
- 要求高可靠性和最小数据丢失 → AOF (
everysec)+定期 RDB 快照; - 生产上通常开 AOF everysec,并同时配置 RDB 作为备份点。
4. Redis 的缓存淘汰策略(maxmemory-policy)
当达到 maxmemory 限制时,根据 maxmemory-policy 采取淘汰:
noeviction:不淘汰,写操作返回错误(默认)。allkeys-lru:对所有 key 使用 LRU(近似实现)。volatile-lru:对设置了 TTL 的 key 使用 LRU。allkeys-lfu:LFU(频度)算法。volatile-lfu:对有 TTL 的 key 使用 LFU。allkeys-random/volatile-random:随机淘汰。volatile-ttl:优先淘汰 TTL 更短的 key。
实现细节
- Redis 的 LRU/LFU 都是近似实现,采用采样和时间戳/频率计数的方式(不是精确维护全局 LRU 双链表,以节省内存开销)。
- LFU 采用一个小计数器并周期性衰减(防止旧热点一直占用)。
工程建议
- 选择
allkeys-lfu可在热点稳定时取得较好效果,但注意对不同 workload 的适配。 - 对数据重要性不同的 key 可设置 TTL(结合
volatile-*策略)。 - 监控
maxmemory、evicted_keys、used_memory_policy 等指标。
5. Redis 高可用实现(主从 + Sentinel / Cluster / third-party)
- 主从复制 + Sentinel(自动故障转移)
- 复制:主(master)将写操作通过异步复制到从(replica)。从可以做读操作(读写分离)。
- Sentinel:监控 master 和 replicas,自动故障检测与选举(当 master 挂掉时,Sentinel 会选举新的 master 并通知客户端或客户端重试)。
- 优点:成熟、简单;缺点:异步复制可能丢失主未同步到 replica 的数据(数据丢失风险)。
- Redis Cluster
- 内置分片与高可用:将 key 空间划分成 16384 hash slots,多个 master 分布这些 slot,每个 master 可以有多个 replica。
- 客户端通过 MOVED/ASK 重定向与 cluster topology 通讯;自动故障转移由 cluster 协议处理(基于投票)。
- 优点:水平扩展(sharding) + 高可用;缺点:跨 slot 的 multi-key 操作有限制(需要放在同 slot,或者使用 hash tag)。
- 数据一致性 & 可用性权衡
- 默认复制是异步(主进写时不会阻塞等待 replica ack),可能数据丢失。可以用
WAIT命令等待 master 把写传播到 N 个 replicas。 - 对强一致性要求高的场景,建议使用外部一致性系统(ZooKeeper/etcd)或 Redis-on-Raft 实现(例如 RedisRaft、Dragonfly 堆栈等)。
- 默认复制是异步(主进写时不会阻塞等待 replica ack),可能数据丢失。可以用
- 工程实践
- 使用 Sentinel 时确保多个 Sentinel 分布在不同机器/可用区。
- 使用 Cluster 时确保键划分合理,避免跨 slot 多键事务。
- 备份策略 + 监控 + 自动报警必不可少。
6. 利用 Redis 实现分布式锁(正确方式与注意)
最常见的简单实现
- 取得锁:
SET lockKey token NX PX 30000- NX:仅当键不存在时设置(原子),PX:过期时间(毫秒)
token用唯一值(UUID),用于后续释放判断所有权。
- 释放锁(必须先校验 token,再 DEL)要原子执行,建议用 Lua:
1 | -- release.lua |
调用:EVALSHA sha1 1 lockKey token
Redlock(多实例分布式锁,Antirez 提出)
- 在多个独立 Redis 实例上分别尝试获取锁(SET NX PX),在大多数实例成功(例如 3/5)视为获得锁。加锁与释放需在最短时间内完成以避免时钟不同步、网络延迟问题。
- 争议:Redlock 在网络分区与异步复制场景下的安全性有争议;某些专家认为它不满足强一致性的分布式锁需求。使用前要评估需求。
工程建议
- 对强一致性要求较高的分布式锁场景(例如分布式协调/leader election),建议使用专门的一致性系统(ZooKeeper/etcd)或使用 Redis Raft。
- 使用 Redis 做锁时请保证:
- 设置合理的过期时间(避免死锁),
- 释放锁时校验 token(防止误删别人的锁),
- 对长时间执行的任务可用续租机制(延长过期),但续租也要很小心(线程崩溃导致续租失败)。
- 注意 Redis 单实例的复制延迟会带来风险;最好配合
WAIT或使用SETNX PX 在主节点直接获得。
7. Redis 怎么实现延时消息
常见实现 1 — Sorted Set(延时队列)
- 用
ZADD delayQueue score=timestamp member=payloadId(score 为可处理时间)。 - 消费者轮询:
ZRANGEBYSCORE delayQueue -inf now LIMIT 0 1得到到期条目 id。- 尝试用 Lua 原子地
ZREM并把 payload 推到处理队列(或直接处理)。
1 | -- pop_due.lua |
- 优点:实现简单,顺序可控。
- 缺点:轮询成本(可用
BRPOPLPUSH与 list 组合或在消费端做 sleep/backoff),并发时要用 Lua 保证原子移除。
常见实现 2 — 使用 Streams + consumer groups
- 将消息写入 streams,携带
deliver_at字段,消费者检查deliver_at并在到期时处理(或使用 XAUTOCLAIM / XCLAIM 来抢占未 ACK 的消息)。 - Streams 提供 ACK、PENDING、重试功能,比 ZSet 更适合可靠消费/重试场景。
工程建议
- 如果需要精确的延时(毫秒级)并发处理,使用专门消息队列(Kafka/ Pulsar / RabbitMQ + delayed plugin)可能更稳健。
- Redis 实现适合中等规模的延时任务和简单可靠性场景;要考虑并发锁与去重、一定的重复消费/幂等处理。
8. Redis 中的 String 是怎么实现的?
SDS(Simple Dynamic String)
- Redis
String的底层使用 SDS 而不是 C 的 NUL-terminatedchar*。SDS 提供:- 二进制安全(可以包含
\0); - 存储长度(O(1) 获取),避免每次
strlen; - 预留空间(free 字段),减少重复 realloc。
- 二进制安全(可以包含
- Object encoding:
- RAW:标准 SDS 存储。
- EMBSTR:当字符串短时,将 SDS 与 Redis 对象 header 一起分配在一个内存块(减少内存碎片、提升效率)。
- INT:对于纯数字字符串,Redis 可以把对象以 long long int 存储为整数编码以节约空间/加速。
- 指令语义:
SET/GET/INCR/APPEND等直接操作 SDS。
9. Redis 中 ZSet(有序集合)怎么实现的?
双结构实现
- 跳表(skiplist):按 score 排序,支持按 score 范围查询、分页、顺序遍历。skiplist 使得范围查询与插入复杂度 O(log N)。
- 哈希表(dict):
member -> score映射,用于 O(1) 校验 member 是否存在 & 直接更新 score。 - 操作流程:
ZADD:先在 dict 看是否存在 member:若存在则更新跳表(先删除旧 score 再插入新 score);否则新插入到 dict 且插入跳表。ZRANGE/ZRANGEBYSCORE:跳表定位起点,然后按链表遍历返回 M 个元素(复杂度 O(log N + M))。
- 优势:结合哈希表及跳表兼顾了 O(1) 查找与 O(log N) 排序操作。
10. 使用 Redis 实现排行榜(Leaderboard)
Simple(单实例)
- 使用 ZSet,member=用户ID,score=分值。
- 加分/设置分数:
ZINCRBY leaderboard delta userId或ZADD leaderboard score userId - 获取排名(倒序,分值高为第一):
ZREVRANK leaderboard userId(返回索引,从0开始) - 获取 top N:
ZREVRANGE leaderboard 0 N-1 WITHSCORES - 获取范围分页:
ZREVRANGE leaderboard start stop WITHSCORES
- 加分/设置分数:
- 注意分数精度:Redis score 是 double 浮点;若需要精确整数,直接存整数或把分数放大(乘 100)存为 double。
带用户信息
- 存分数在 ZSet,用户详情放 in Hash
user:userid。 - 在返回 top N 时
ZREVRANGE ... WITHSCORES得到 ids,再批量HMGET拉取信息(pipeline)。
并发/多实例/集群
- 在 Cluster 模式确保访问同一 key(slot)或者使用客户端支持跨 slot 聚合。
- 若写入非常频繁并导致单点瓶颈,可考虑分片或以时间段为单位分 ZSet 再合并(复杂)。
大规模与历史榜
- 使用 time-windowed sorted sets(例如按日/周/月 leaderboard)来实现历史和滚动排名。
11. 用 Redis 实现注册中心(Service Registry)
思路(轻量)
- 每个服务实例启动时
SET service:{name}:{instanceId} metadata NX PX heartbeatInterval*...或HSET service:{name} {instanceId} metadata并配合EXPIRE或定时续租心跳。 - 客户端注册:
SET或HSET+ TTL,每隔t秒心跳延长 TTL(或重新SET)。 - 服务发现:客户端查询
SCAN/KEYS service:{name}*或使用SMEMBERS services:{name}(如果用集合管理)。 - 监听变更:使用 Pub/Sub 或 Redis Stream 发布
service-up/service-down事件;或者消费者轮询 TTL 变化。
优点/缺点
- 优点:简单、延迟低。
- 缺点:
- Redis 仍是单点(需 Sentinel/Cluster 做 HA),
- 对于强一致性(leader 选举、分布式锁)不如 ZooKeeper/etcd 可靠(但可做)。
- 改进:使用 Redis + Sentinel/Cluster + 客户端缓存 + watch/notify 来降低读延时与感知延迟。
12. Redis 的线程模型
- 单主线程处理命令(event-loop),I/O 多路复用。
- 背景线程/进程:
- 子进程 fork:RDB 保存与 AOF rewrite 用 fork 的子进程做 IO 操作;
- 后台线程(某些版本)用于异步删除(lazyfree)、部分模块、RDB/AOF rewrite 辅助;
- I/O 线程(自 Redis 6 起)可并行化 socket read/write,但命令处理仍在主线程。
- 写时复制(COW)在 fork 时会复制页面,可能导致内存短期上涨。
- 因为命令执行单线程,所以任何阻塞式命令或慢命令(例如
KEYS、大SORT、遍历超大集合)会阻塞整个服务。要避免这些慢命令或使用SCAN/SSCAN/ZSCAN/HSCAN做渐进式遍历。
13. Redis 的事务(MULTI/EXEC/WATCH)
- MULTI / EXEC / DISCARD
MULTI开始事务(只是命令排队)。- 客户端在
EXEC时,队列中的命令会被一次性执行(单线程原子性:中间不会被其他命令插入),但 如果命令内部失败,事务不会回滚,失败的只是那条命令。
- WATCH(乐观锁)
WATCH key1 key2监视 key,如果在EXEC前这些 key 被其他客户端改动,则EXEC返回 null,事务失败(可重试)。UNWATCH取消监视。
- 局限
- Redis 事务不是关系型数据库意义上的事务(没有隔离级别、没有回滚机制);只是命令批量的“原子提交”。
- 在 Cluster 上,MULTI/EXEC 要求所有 key 属于同一 hash slot(否则会报错)。
- 替代:Lua 脚本(EVAL)在 Redis 中是原子执行、能做复杂原子操作、支持返回值;在多数场景下比 MULTI 更强大与安全。
14. Redis IO 多路复用模型(实现细节)
- 使用
ae事件库封装系统调用:select/poll/epoll/kqueue。在 Linux 下主要使用epoll。 - 事件循环做两件事:处理读/写/accept 等事件 & 执行命令。网络读到完整请求后放到客户端上下文,主线程解析命令并执行。
- Redis 采用非阻塞 IO与事件驱动来实现高并发连接处理。
15. Redis 的大 key(big key)以及原因
什么是大 key
- 指一个 key 本身内部的数据量很大(如一个包含数百万元素的 list/hash/zset 或非常大的 string),导致对该 key 的任何操作都很耗时且可能阻塞服务。
为什么产生
- 不合理的数据模型(把太多用户或日志塞入单个 list/hash)。
- 未分片或未分块地存储大量数据(例如把百万级别日志存在一个 list)。
- 忽用
KEYS/SMEMBERS等一次性返回全量接口。
问题
- 操作该 key(如
LRANGE、DEL、HGETALL)将占用大量 CPU / 内存并可能阻塞主线程,导致延迟飙升。 DEL可能会阻塞;现代 Redis 有UNLINK(异步删除后台释放内存)来缓解。
检测大 key
redis-cli --bigkeys(工具)会扫描样本并报告大 key。MEMORY USAGE key查看内存占用。DEBUG OBJECT key(谨慎)或OBJECT encoding key查看编码/结构。
对策
- 设计分片,比如把单个 list 分成为
list:YYYYMMDD:shardId。 - 使用流(Streams)或外部存储(对象存储)分离非常大的二进制数据。
- 使用
UNLINK替代DEL做异步删除。 - 避免一次性全量操作,使用
SCAN/SSCAN/ZSCAN/HSCAN进行增量遍历。
16. Redis 的集群模式(工作原理)
核心概念
- 将 key 空间分为 16384 slots,每个 master 负责若干 slot。
- 节点角色:master + optional replicas(replica 用于 failover)。
- 重定向:客户端访问非本节点的 slot 会收到
MOVED(静态重定位)或ASK(重分配临时重定向)。 - 数据迁移(resharding):通过
MIGRATE或CLUSTER命令把 slot 从一个节点迁到另一个节点(期间会产生ASK临时指令)。 - 故障转移:
- Cluster 各节点通过 gossip 协议互相通告状态,若 master 挂掉且多数 replicas 同意(based on configEpoch & votes),会选举一个 replica 为新的 master(自动 failover)。
- 事务与 multi-key 操作
- 多 key 命令要求所有 key 在同一 slot(或使用
{hash-tag}把相关 key 放入同 slot),否则报错。
- 多 key 命令要求所有 key 在同一 slot(或使用
- 客户端
- Cluster-aware 客户端会缓存 cluster slots 映射并自动跟随
MOVED重定向。
- Cluster-aware 客户端会缓存 cluster slots 映射并自动跟随
- 工程注意
- 设计时尽量把相关 key 放同 slot(hash tag)。
- 监控 cluster slots 分布、replication lag、failover 次数。
- 节点拓扑要冗余部署(不同机房/可用区)。
17.Redssion
1. Redisson 简介
- Redisson 是 Redis 官方推荐的 Java 客户端,比 Jedis、Lettuce 更高级。
- 除了基本 Redis 操作,它还提供了 分布式对象、分布式集合、分布式锁、限流器、信号量 等并发工具。
- 最常用的功能就是 分布式锁(ReentrantLock、FairLock、ReadWriteLock、Semaphore 等)。
2. Redisson 分布式锁的核心机制
Redisson 的分布式锁相比自己写的 SET NX EX 有三大改进:
2.1 自动续期(看门狗机制)
- 加锁时默认过期时间 = 30 秒。
- 如果业务逻辑未完成,Redisson 内部会有一个 watchdog 守护线程,每隔 10 秒自动续期,保证锁不会提前过期。
- 如果客户端宕机,守护线程也会停止,锁会在过期时间后自动释放 → 避免死锁。
2.2 可重入锁
- 和 Java 的
ReentrantLock一样,Redisson 的RLock支持可重入(同一线程多次加锁不会死锁)。 - 实现方式:用 Redis
Hash存储锁的持有者(线程 ID + 重入次数)。
2.3 多种锁类型
Redisson 提供了丰富的锁实现:
- RLock:普通可重入锁
- FairLock:公平锁(FIFO 排队)
- ReadWriteLock:读写锁(共享读 / 独占写)
- MultiLock:多个 Redis 节点上的联合锁(类似 Redlock)
- RedLock:实现 Redis 官方的 Redlock 算法
- Semaphore:分布式信号量
- CountDownLatch:分布式闭锁
3. 使用示例(Java)
3.1 引入依赖
Maven:
1 | <dependency> |
3.2 创建 Redisson 客户端
1 | import org.redisson.Redisson; |
3.3 获取分布式锁
1 | import org.redisson.api.RLock; |
4. 多种锁示例
4.1 公平锁(先来先得)
1 | RLock fairLock = redisson.getFairLock("fairLock"); |
4.2 读写锁
1 | RReadWriteLock rwLock = redisson.getReadWriteLock("rwLock"); |
4.3 信号量
1 | RSemaphore semaphore = redisson.getSemaphore("semaphore"); |
5. 常见问题与最佳实践
- 锁过期导致业务未完成
Redisson 自带看门狗续期机制(默认 30 秒 + 每 10 秒续期),一般不用担心。 - 死锁问题
- 如果用
SETNX自己实现,可能出现死锁。 - Redisson 通过过期 + 看门狗避免死锁。
- 如果用
- 性能问题
- 分布式锁毕竟是跨进程的,性能不如本地锁。
- 适合关键资源互斥,不要滥用。
- 高可用 Redis
- 推荐 Redis 哨兵模式 / 集群模式,避免单点问题。
- Redisson 原生支持这些模式,配置简单。
6. 总结
- 如果你只要一个分布式锁:Redisson 的
RLock+ 自动续期足够了。 - 如果要公平性/可重入/读写锁/信号量:Redisson 都提供现成实现。
- 如果是核心业务:用 Redisson + Redis 哨兵/集群模式,确保高可用。
Mybatis-牛客面经八股
1. $ 与 # 的区别
#{param}:使用 JDBC 的PreparedStatement占位符?绑定参数,会进行 类型转换 & 自动转义(防 SQL 注入),例如WHERE name = #{name}生成WHERE name = ?。${param}:直接字符串替换(文本替换),相当于把 param 拼进 SQL;用于列名 / 表名等动态 SQL 片段,但存在 SQL 注入风险。
建议:优先用#{},只有在必须动态拼字段/表名时且经过严格白名单校验时才用${}。
2. MyBatis 的缓存机制
- 一级缓存(Local Cache)
- 作用域:
SqlSession级别(会话级),默认开启。 - 行为:相同
SqlSession内重复执行同一查询会命中缓存,直到SqlSession关闭或执行更新操作(UPDATE/INSERT/DELETE)导致缓存失效。
- 作用域:
- 二级缓存(Global Cache)
- 作用域:namespace(mapper)级别,跨 SqlSession 共享。
- 需要在
mapper.xml中<cache/>显式开启(或配置实现),也可以自定义 Cache 实现。 - 缓存 key 由
CacheKey生成(含 mappedStatement id、SQL、param、分页、环境等)。 - 写操作会清空(flush)对应 namespace 的二级缓存(默认行为)。
- 实现细节
- 二级缓存会序列化/反序列化对象(默认 Java 序列化),可插入更高效的序列化(Kryo、FST)或用外部存储(Redis)实现二级缓存。
- 若对象含有可变字段,缓存可能产生 stale 数据;要慎重设计缓存失效策略。
- 常见优化
- 使用二级缓存时需确保对象可序列化并合理设置
flushInterval、size、readWrite(readWrite=true 表示序列化读写以保证线程安全)。 - 对于频繁变更的数据不适合二级缓存。
- 使用二级缓存时需确保对象可序列化并合理设置
3. MyBatis 实现一对多关联查询(两种主要方式)
一条 SQL 联表查询 + resultMap 映射
- 使用
JOIN,配置<resultMap>,其中<collection property="orders" ofType="Order">映射子集合,通过resultMap的column指定关联字段。 - 优点:只一次数据库往返;缺点:如果主表 N 行、子表 M 行,返回的行数为笛卡尔展开,可能造成重复主对象需要去重(MyBatis 自动处理但会消耗内存)。
- 使用
分两次查询(N+1 问题的改良)
先查询主表集合,得到 id 列表;再用
IN查询子表WHERE fk IN (...),然后在 Java 层组装。MyBatis 提供
<select>的resultMap嵌套<collection>的fetchType="lazy"或select属性(嵌套查询):1
<collection property="orders" ofType="Order" select="selectOrdersByUserId" column="id" />
优点:避免单次大联表重复数据,适合主从表一对多规模较大场景。
工程建议:对于小表/数据量少,用单表 JOIN;对于大数据量/分页场景,用两步查询(单次 IN 查询)并注意限制 IN 的长度或分批查询。
4. MyBatis 如何防止 SQL 注入
- 首要原则:使用
#{}参数绑定(PreparedStatement)代替字符串拼接。 - 对必须拼接的元数据(表名、列名)使用白名单校验(只允许已知的列名/表名),不要直接把来自用户的原始值放到
${}。 - 使用数据库权限最小化策略、审核 SQL 日志、在应用层做参数校验与类型检查。
- 对动态 SQL 执行做好限制(分页参数必须是整型、限制 pageSize 最大值等)。
5. MyBatis 和 MyBatis-Plus 的区别
- MyBatis
- 更轻量、原始、需要手写 SQL/映射。
- 灵活性高,适合复杂 SQL 与精确控制。
- MyBatis-Plus (MP)
- 在 MyBatis 基础上提供增强功能:通用 CRUD(无需写 SQL)、代码生成器、Wrapper 条件构造器、分页插件、逻辑删除、性能分析插件等。
- 优点:提高开发效率,减少重复 CRUD 代码。
- 缺点:抽象层更多,可能隐藏 SQL 细节(需要关注生成 SQL 性能);对复杂 SQL 还是需要自定义。
选择:如果项目是标准 CRUD 大量重复,使用 MP 可以大幅提升效率;对复杂查询/性能敏感的模块仍应手写 Mapper SQL。
6. MyBatis 如何实现分页查询
RowBounds(物理分页):MyBatis 提供
RowBounds类用于客户端分页。缺点:默认实现会在内存中做分页(取出全部结果再截取),不适合大量数据。数据库分页(推荐):使用
LIMIT/OFFSET(MySQL/Postgres),或相应 DB dialect 的分页语法。通常使用分页插件(例如 PageHelper)或 MyBatis-Plus 的IPage/Page对象自动注入分页 SQL。步骤示例(MySQL)
1
2
3
4SELECT * FROM users
WHERE ...
ORDER BY created_at DESC
LIMIT #{offset}, #{pageSize}高级:对于大偏移(offset 大),建议使用基于索引的分页(记录上次最后 id)避免 OFFSET 扫描开销。
7. MyBatis 中动态 SQL 的作用
使用 XML 标签(
<if>,<where>,<trim>,<foreach>,<choose>等)根据传入参数动态拼装 SQL。作用:
- 避免手写大量 SQL 变体。
- 提高复用性:同一 mapper 方法根据条件生成不同 where 子句。
示例:
1
2
3
4
5
6
7<select id="findUsers" parameterType="map" resultType="User">
SELECT * FROM user
<where>
<if test="name != null">AND name = #{name}</if>
<if test="age != null">AND age = #{age}</if>
</where>
</select>
8. MyBatis 的插件原理(Interceptor)
- MyBatis 提供插件接口
org.apache.ibatis.plugin.Interceptor,可以拦截:Executor(执行器)、StatementHandler(SQL 执行)、ParameterHandler(参数处理)、ResultSetHandler(结果处理)。
- 插件通过
Plugin.wrap(target, this)返回代理对象(JDK 动态代理)。拦截器的intercept(Invocation invocation)可以在调用前/后做增强,或替换执行逻辑。 - 插件在配置文件中注册并按顺序生效。典型应用:分页插件、性能监控、动态数据源切换等。
PageHelper 插件原理分析
PageHelper 是一个 MyBatis 插件(Interceptor),它的核心思想是:
通过 拦截 SQL 执行过程,在执行真正的 SQL 前后,动态修改 SQL 语句,在 SQL 中追加 LIMIT(MySQL)/ ROWNUM(Oracle) 等分页语法,从而实现物理分页。
1. PageHelper 的使用方式
1 | PageHelper.startPage(1, 10); // 开始分页(第 1 页,每页 10 条) |
PageHelper.startPage()并不是直接分页,而是 设置分页参数到 ThreadLocal。- 当 MyBatis 执行查询 SQL 时,PageHelper 插件会 检测到当前线程存在分页参数,拦截 SQL 并修改。
2. PageHelper 的拦截点
PageHelper 是基于 MyBatis 的插件机制实现的,主要拦截:
- Executor.query
MyBatis 执行 SQL 查询的入口点。 - 具体类:
PageInterceptor,实现了Interceptor接口。
1 |
|
@Intercepts注解表示拦截Executor.query()方法。- 当执行 Mapper 的
select方法时,会被拦截。
3. PageHelper 的核心流程
(1) PageHelper.startPage()
- 把分页参数(页码 pageNum,每页大小 pageSize,是否统计 count)放入
ThreadLocal。 - 这样就可以在后续 SQL 执行时,读取到这些分页参数。
(2) PageInterceptor 拦截 query()
拦截到 SQL 执行时,会做几件事:
获取分页参数(从
ThreadLocal)。解析原始 SQL,例如:
1
SELECT * FROM user
生成分页 SQL(根据不同数据库方言,比如 MySQL / Oracle):
MySQL:
1
SELECT * FROM user LIMIT 0, 10;
Oracle:
1
2
3SELECT * FROM (
SELECT rownum rn, t.* FROM (SELECT * FROM user) t WHERE rownum <= 10
) WHERE rn > 0PostgreSQL:
1
SELECT * FROM user LIMIT 10 OFFSET 0;
生成 count SQL(可选),如果需要分页总数:
1
SELECT COUNT(*) FROM user;
- PageHelper 会先执行 count SQL,得到总记录数。
- 然后再执行分页 SQL,得到当前页数据。
(3) 执行分页 SQL & 返回结果
- PageHelper 执行改写后的分页 SQL。
- 把结果封装成
Page或PageInfo对象,包含:pageNum(当前页)pageSize(每页大小)total(总记录数)pages(总页数)list(当前页数据)
4. PageHelper 的核心类
PageHelper:入口工具类,负责设置分页参数(存入 ThreadLocal)。Page:继承ArrayList,存放分页结果,同时保存分页信息(total, pageNum, pageSize)。PageInterceptor:MyBatis 插件拦截器,核心逻辑在这里。Dialect:方言类,不同数据库分页 SQL 的实现(MySQLDialect、OracleDialect 等)。
5. PageHelper 的优势
- 使用方便:只需
startPage()即可,不用手写分页 SQL。 - 支持多数据库:内部有方言适配器。
- 支持自动 count,总页数计算简单。
- 基于 MyBatis 插件机制,不需要改动 SQL。
6. PageHelper 的局限性
- 线程绑定问题
startPage()依赖ThreadLocal,必须在查询语句之前调用,否则无效。- 如果一个线程执行多个分页,可能会出现混乱,需要注意调用顺序。
- count 性能问题
- 大表
COUNT(*)代价很高,可能导致分页慢。 - 可通过优化 SQL 或冗余字段来避免。
- 大表
- 复杂 SQL 的 count 不准确
- 比如包含
GROUP BY/DISTINCT时,count 语句可能需要手动优化。
- 比如包含
7. 总结
👉 PageHelper 的核心原理:
- 基于 MyBatis 插件机制,拦截
Executor.query()。 - 利用
ThreadLocal传递分页参数。 - 动态改写 SQL,生成
count SQL + limit SQL。 - 执行后封装结果集为分页对象返回。
9. MyBatis 底层原理(请求执行全流程)
核心组件与调用链(简化)
- Configuration:解析 mapper XML / 注解,构建
MappedStatement、ResultMap、SqlSource等。 - SqlSessionFactory:负责创建
SqlSession。 - SqlSession:一切 DB 操作入口,提供
select/insert/update/delete等方法。 - Mapper Proxy:
Mapper接口通过 JDK Proxy(或 CGLIB)生成,调用 mapper 方法会转发到MapperProxy,最终调用SqlSession执行对应MappedStatement。 - Executor:执行器负责缓存策略、调用
StatementHandler执行 JDBC。- Executor ->
StatementHandler.prepare()->ParameterHandler.setParameters()->Statement.executeQuery()->ResultSetHandler.handleResultSets()。
- Executor ->
- StatementHandler / ParameterHandler / ResultSetHandler
StatementHandler负责创建 JDBC Statement(PreparedStatement)、设置分页 SQL(如果 RowBounds)或其他变换。ParameterHandler负责把参数绑定到 PreparedStatement 的?上(依赖 TypeHandler)。ResultSetHandler把 JDBCResultSet映射成 Java 对象(使用ResultMap的映射规则)。
- TypeHandler
- 用于 Java 类型与 JDBC 类型映射(可以自定义,例如 JSON 序列化)。
- 动态 SQL 处理
- Mapper XML 中的
<if>/<foreach>在构建SqlSource时会被解析为DynamicSqlSource,执行时生成BoundSql(最终 SQL + 参数映射)。
- Mapper XML 中的
- 缓存
- Executor 在执行前会根据
CacheKey进行一级/二级缓存查询。
- Executor 在执行前会根据
- 事务
SqlSession管理事务(底层使用 JDBC 事务或 Spring 的 DataSource 事务管理)。
关键点
- MyBatis 把 SQL 与 Java 映射隔离,运行时通过配置构建执行计划。
- 动态 SQL 在解析时产生一颗语法树,在执行时按参数生成真实 SQL。
- MyBatis 允许自定义拦截器、TypeHandler、插件扩展点。
SQL-牛客面经八股
好 —— 我把你 1–31 每一条都逐项放大解读,把原理、实现细节、面试要点、常见例子、实践建议和可复制的解决办法都写清楚。篇幅较长,但这是一次把知识“掰开揉碎”到能直接答面试与做线上定位的版本。每一节都尽量包含:原理 → 行为/例子 → 故障/失效场景 → 优化/修复办法。
1. 什么是索引?索引有哪些分类?
概念(本质)
索引是为表中一列或多列建立的 辅助数据结构,用于快速定位满足某些条件的记录,减少磁盘 I/O 和全表扫描。数据库把索引看成“查表的导航”。
按维度分类(并扩展解释)
- 按数据结构
- B+Tree(B+ 树):最常见。支持范围查询、排序、分页;磁盘/页友好(一次读回多个 key)。
- Hash:O(1) 等值查询,不能做范围/排序。MySQL InnoDB 没有用户可见 Hash index,但 MEMORY 存储引擎提供 hash 索引。InnoDB 有 Adaptive Hash Index(自适应哈希索引) 作为优化。
- Fulltext:倒排索引,用于全文检索(MATCH…AGAINST)。
- R-Tree / GiST / SPATIAL:用于空间数据(GIS)。
- 按逻辑用途
- 主键索引(PRIMARY KEY):唯一,不能为 NULL,InnoDB 中是聚簇索引。
- 唯一索引(UNIQUE):保证列唯一性。
- 普通索引(INDEX)
- 按物理存放与访问
- 聚簇索引(Clustered):叶子存整行(InnoDB 主键)。
- 非聚簇索引(Secondary):叶子存主键值(回表)。
- 按列数
- 单列索引、联合(复合)索引。
面试/实践要点:
索引不是越多越好。索引是读优化并以写代价换取的:每次写/更新都要维护索引(开销 + 额外 IO + 可能的锁)。
2. Hash 索引 与 BTree 索引 的详细区别(含 InnoDB 特例)
Hash 索引
- 查找:哈希表根据 key 直接定位桶 → 平均 O(1)。
- 适用:等值查找(
=、IN)。 - 不适用:范围查询(
BETWEEN、>、LIKE 'a%'也不能排序/范围)。 - MySQL 场景:MEMORY 引擎的 hash index。InnoDB 本身没有对用户表提供持久 Hash index,但内部会根据热数据构建自适应哈希索引(AHI)提升热点范围访问速度(AHI 是运行时构建的)。
B+Tree(B+ 树)
- 查找:O(logN),每层读一个节点(磁盘页),节点 fanout 高,层数小。
- 优点:支持前缀匹配、范围查询、顺序扫描、order by 利用索引避免 filesort。
- 叶子节点链表使顺序遍历非常快(适合范围、分页)。
举例
WHERE username = 'alice':Hash 和 B+ 树都可以很快。WHERE age BETWEEN 20 AND 30:Hash 无解,B+ 树优选。ORDER BY created_at DESC LIMIT 10:若有 B+ 树按 created_at 排序,能直接用索引返回;Hash 无法帮助排序。
实战提示:当查询只做大量简单等值并且无需排序/范围时 MEMORY+Hash 或缓存(Redis)是合适的,但对于持久化大表与混合查询,B+Tree 是通用选择。
3. 为什么 MySQL 采用 B+ 树?
关键原因
- 磁盘/页导向:B+ 树节点能容纳多个 key,单次磁盘读取可获得更多 key(高 fanout,低高度),极大减少磁盘 IO。
- 范围/排序原生支持:叶子节点链表可 O(1) 地从一个叶子顺序遍历到下一个叶子,范围查询/排序/分页高效。
- 稳定的页型组织:内、外节点分工明确(内节点索引,叶节点记录或指针),便于磁盘/缓存优化。
- 顺序插入/删除代价较低:相比红黑树的每一次调整(指针微调),B+ 树整体在磁盘环境下的重排更可控。
对比红黑树(或 AVL)
- 红黑树每个节点只含几个 key,深度更高,磁盘访问更多,IO 不友好。
- B+ 树将所有 key 放在叶子并形成链表,范围扫描复杂度低且局部性好。
4. B+ 树查询数据的全过程
以 InnoDB 的二级索引查询为例 SELECT col1,col2 FROM t WHERE idx_col = ?:
步骤
- 从根节点读取内存页:读取节点内的索引范围信息,根据 key 找到对应 child 指针(页 id)。
- 递归下钻:在内节点根据 key 比较决定下一跳,直到叶子节点。
- 叶子节点定位:
- 二级索引(非聚簇):叶子 node 存储
(indexed_key, PRIMARY_KEY)。 - 找到匹配叶子项后获得主键值,回表(再走聚簇索引)以读取完整记录。
- 聚簇索引(主键):叶子直接存储完整行(或指向行在页中的偏移),无需回表。
- 二级索引(非聚簇):叶子 node 存储
- 返回结果:把结果发送给上层 SQL 引擎。
注意:
- 回表成本是二级索引的一项主要开销(每命中二级索引都可能触发一或多次聚簇索引访问)。
- 覆盖索引(索引包含查询所需列)可以避免回表,大幅提升效率。
5. 三层 B+ 树能存多少数据?
公式法
- 假设 page(页)大小 P(常见 16KB),每个索引条目占用 S 字节(S = key_length + pointer_length + overhead)。
- fanout ≈ floor(P / S)(每个节点可指向 fanout 个子节点)。
- 如果高度为 h(根为第 1 层、叶为第 h 层),能表达的叶子条目数 ≈ fanout^(h-1) * entries_per_leaf(approx)。
举例(简化前面例子)
- P = 16KB = 16384 bytes
- S ≈ 16 bytes (8B key + 8B pointer)
- fanout ≈ 1024
- 三层(root + level2 + leaf level)大致能表达 1024^2 ≈ 1,048,576 leaf pages,每页可包含多条记录(或 1 条 row pointer),合并到记录数上可达到亿级甚至十亿级,取决于 leaf 的条目数。
现实中
- InnoDB 的 leaf 存储的是索引条目(可能多个列、变长),因此每页条目数受字符集和列长度影响。
- 实际层高通常较低(3–4),能支撑数 10^8 到 10^10 级别的记录。
6. 聚簇索引(Clustered) vs 非聚簇索引(Secondary)
聚簇索引(InnoDB 主键)
- 叶子节点存整行数据(实际数据页即为 B+ 树叶子)。
- 表的物理顺序以主键顺序组织(插入大量随机主键会导致随机写/页面分裂)。
- 好处:
- 主键范围查询、ORDER BY/绿色扫描很快。
- 访问主键直接命中无需回表。
- 坏处:
- 每个表只能有一个聚簇索引(即只有一个物理排序方式)。
- 主键变更代价高,因为行必须移动。
非聚簇索引(Secondary)
- 叶子节点存索引列 + 主键(作为 row identifier)。
- 访问二级索引后需回表(通过主键再走聚簇索引获取整行)。
- 好处:
- 可建立多种不同访问路径(多个二级索引)。
- 坏处:
- 回表开销,尤其是命中很多条且非覆盖时。
实践建议
- 设计主键尽量使用 自增或有序主键(减少页分裂),或使用
UUID的有序变体(ULID)。 - 对于频繁的聚合/查询字段,考虑建立覆盖索引(把能覆盖查询的列都加入索引)。
7. 联合索引的存储结构与“最左前缀”原则
结构
索引 (a,b,c) 在 B+ 树中是按 (a,b,c) 的字典序排列。索引条目的 key 为复合值。
最左前缀原则
索引可用于以下查询:
WHERE a = ?WHERE a = ? AND b = ?WHERE a = ? AND b BETWEEN ? AND ?(b 的范围仍能使用)WHERE a LIKE 'prefix%'(前缀匹配)ORDER BY a, b(与索引顺序匹配的排序可避免 filesort)
被阻断的情形(典型例子)
WHERE b = ?(没有 a 的条件)不能直接利用(a,b,c)索引寻找单个 b。WHERE a > ? AND b = ? AND c = ?:当对 a 使用范围(>、BETWEEN),索引只能使用到 a 的范围定位,b/c的等值后续列不能用于索引访问(但仍可用于过滤或排序优化取决于引擎)。
补救办法
- 如果业务常按 b 查询,应加单列索引
b或把联合索引换为(b,a,c)之类,按访问频率与选择性设计。 - 使用 索引覆盖 并合理排序联合索引字段以匹配常见 WHERE/ORDER BY。
8. SELECT IN / 模糊查询 中如何使用索引
IN
col IN (v1, v2, v3)等价于多个等值条件的 OR,MySQL 可以利用索引做多个快速定位(多次索引查找或范围查找),性能通常好于多个 OR,但是具体行为可在执行计划中查看。
LIKE 模糊查询
LIKE 'abc%':前缀匹配,能走索引(B+ 树从 ‘abc’ 起定位并顺序扫描)。LIKE '%abc':前导通配符导致索引失效(无法从索引开始定位,因为任意前缀)。LIKE '%abc%':同上,不能利用 B+ 树索引;解决方式:全文索引(FULLTEXT)或外部搜索(Elasticsearch);或倒排索引/三gram。
优化思路
- 将模糊搜索重构为前缀匹配或使用全文索引。
- 对 IN 的大集合要小心,如果 IN 列表非常长,优先把常用值放入临时表并
IN (SELECT)或使用 join。
9. 建索引注意事项
何时建
- 经常出现在 WHERE / JOIN / ORDER BY / GROUP BY 中的列。
- 作为外键引用的列(保证 join 性能)。
字段选择与顺序(联合索引)
- 把选择性高(distinct 值多)的列放在前面。
- 把经常用于 range 的字段放在后面(因为范围会停止利用后续列)。
索引类型 / 编码注意
- 字符串字符集影响索引长度(utf8mb4 每字符最多 4 字节),索引前缀长度受限(历史上 InnoDB 有 767/3072 字节限制);使用
VARCHAR(255)在 utf8mb4 下可能需要更短的前缀或压缩。 - 对大文本列使用前缀索引:
INDEX(name(50))(节省空间,但会降低准确性)。
尽量避免
- 在低选择性的列(如性别、布尔标志)上建立单列索引(索引命中率低)。
- 在频繁写入、更新的列上建立过多索引(维护成本高)。
- 盲目建立冗余索引(比如已有
(a,b)就无需再建(a)一般情形可省,除非单列查询高频)。
覆盖索引
- 将查询所需字段都放在索引中(select 列为索引列)能避免回表,显著提速。
面试追问要点
- 讨论索引的空间/写入开销、选择性和基数(cardinality),以及如何用
SHOW INDEX/ANALYZE TABLE来获取统计信息。
10. 如何评估 / 判断索引是否生效?常见索引失效场景详尽列举
判断索引是否生效(步骤)
- 使用
EXPLAIN <SQL>(或EXPLAIN FORMAT=JSON)查看:key(使用的索引)、type(访问类型)、rows(估算扫描行数)、Extra(filesort/Using temporary/Using index)。 - 查看实际执行时间与
EXPLAIN ANALYZE(MySQL 8+)的真实耗时、IO。 SHOW INDEX FROM table_name查看索引定义及 cardinality。ANALYZE TABLE table_name更新统计信息后再用 EXPLAIN 检查(有时统计失真会让优化器选择差计划)。
常见索引失效场景(详述)
对索引列做函数/表达式:
1
WHERE DATE(created_at) = '2025-10-01' -- 索引失效
修复:写作
WHERE created_at >= '2025-10-01' AND created_at < '2025-10-02'。隐式类型转换:
1
WHERE id = '123' -- 如果 id 是 INT,隐式转换可能导致索引不使用
修复:确保参数类型匹配或强制类型转换在常量上。
Leading wildcard(前导通配符):
1
WHERE name LIKE '%abc' -- 无法用索引
修复:避免前导
%,或使用 FULLTEXT/倒排索引。OR 條件中没有共同索引:
1
WHERE a = 1 OR b = 2 -- 若 a,b 都有索引,查询可能会采用 index_merge,但复杂情况仍可能全表扫描
修复:用 UNION 优化(
SELECT ... WHERE a=1 UNION SELECT ... WHERE b=2),或添加合适联合索引。范围搜索切断联合索引后续列:
1
WHERE a > 1 AND b = 2 AND c = 3 -- 如果 a 是范围条件,后续 b,c 通常不能利用索引进行定位(但可以作为过滤)
使用
NOT、<>、IS NULL(依赖场景):NOT和<>通常导致全表扫描。IS NULL可用索引但要看实现与数据分布。隐含返回过多列导致不能使用覆盖索引:
SELECT *会导致回表。统计信息过期或不准确:优化器基于统计,如果统计不准会选错索引,使用
ANALYZE TABLE更新。
演练:如何修复某常见失效
场景:WHERE DATE(ts) = '2025-10-01'。
解决:
1 | -- 改写为范围 |
好处:能利用 ts 上的索引,避免函数计算。
11. 索引失效后怎么办?
- 第一步:EXPLAIN 看当前计划与
key列。 - 第二步:确认 WHERE / ORDER BY / JOIN 中列的表达式是否会破坏索引(函数、类型转换、范围切断)。
- 第三步:重写 SQL:
- 把函数移动到常量端或使用等价的区间(日期函数改为区间)。
- 避免 SELECT *,改为需要列(利于覆盖索引)。
- 对 OR 用 UNION 或添加合适索引。
- 第四步:增加或调整索引:
- 做覆盖索引或按查询列顺序建立复合索引。
- 对 TEXT/VARCHAR 做前缀索引(必要时)。
- 第五步:统计/版本:
ANALYZE TABLE后再次 EXPLAIN。- 了解 MySQL 版本的优化器行为(例如 5.7 vs 8.0 在 subquery rewrite 上有差别)。
- 第六步:测试与回滚:
- 在预发布/测试环境验证索引是否改善查询计划和实际耗时。
- 使用慢查询日志对比。
12. 数据库索引重构过程(线上零停机实践)
目标:修改索引(添加/删除/重建)而不影响线上业务。
常用工具与策略
ALTER TABLE … ADD INDEX:在较新 MySQL 支持
ALGORITHM=INPLACE, LOCK=NONE可在线加索引(不阻塞读写)。但并非所有场景都支持(依赖表引擎、列类型、已有 DDL 状态)。1
ALTER TABLE t ADD INDEX idx_col(col) ALGORITHM=INPLACE, LOCK=NONE;
pt-online-schema-change(Percona Toolkit):原理:创建一个新表(目标结构),用触发器/复制把变更期间的数据同步到新表,最后原子 RENAME 表交换。优点成熟,适用范围广,但在高写场景触发器开销大。
gh-ost(GitHub):基于 binlog 的在线 schema change,低风险、对主库影响小;更适合高并发写表。原理类似:复制数据到 ghost table 并实时追赶 binlog,然后切换。
手工方案(可用于大批量重建索引):
- 在 off-peak 期间创建新索引副本表(若可行)。
- 使用分批迁移或分区交换(PARTITION EXCHANGE)来减少停机。
- 使用
ALTER TABLE ... DISABLE KEYS(MyISAM)或pt-online-schema-change。
注意事项
- 在线建索引会额外占用 IO / CPU / binlog,有流量控制(Throttle)。
- 在多主/主从拓扑中,要考虑 Replica 上的 DDL 是否也会执行、binlog_format(ROW/STATEMENT)影响。
- 切换前务必备份与验证。
13. 为什么数据库用 B+ 树不使用红黑树
- 磁盘页角度:B+ 树内节点可包含许多 key→降低树高度→减少磁盘页读写次数(关键点:磁盘 IO 是瓶颈)。
- 顺序遍历:B+ 树叶子链表提供顺序遍历,非常适合范围扫描和排序操作;红黑树的中序遍历需更多随机 IO。
- 空间局部性:B+ 树把叶子节点放在连续页中(或缓存友好),提高 cache 命中率。
- 写放与页分裂:B+ 树专门为页管理设计,插入造成页分裂的代价在磁盘系统中更可控。
14. 数据库分页的实现方式
方法 A:LIMIT OFFSET(通用)
1 | SELECT * FROM t ORDER BY id LIMIT 1000000, 10; |
- 问题:数据库需要扫描并跳过前 1,000,000 行(或者移动游标),成本与 offset 线性增长(O(offset))。
方法 B:基于索引的 Keyset / Seek Pagination(推荐)
1 | -- 前端保存上页最后 id = last_id |
- 优点:避免 large offset,随机访问对索引友好,稳定性好。
- 限制:不能随意跳到任意页(只支持“下一页/上一页”或基于 cursor 的跳转),不适合“跳到第 N 页”的场景。
方法 C:预先计算/物化分页结果
- 对于复杂查询或热点分页,预计算并把排名/页结果写到缓存(Redis、materialized view)。
方法 D:使用索引覆盖 + 子查询
1 | SELECT * FROM t WHERE id IN ( |
这在某些场景下,子查询只返回 id(索引列)能稍微减轻代价,但仍要注意 offset 开销。
方法 E:使用窗口函数(MySQL 8)
- 可用
ROW_NUMBER()辅助复杂场景,但底层仍需要扫描/排序。
15. LIMIT 100000000,10 与 LIMIT 10 性能差异
原因
- MySQL 的 OFFSET 会找到行数然后弃掉前面 N 行(游标移动、IO 扫描),实质上做了大量无用工作。
LIMIT 10可在索引上迅速返回起始几行。
解决办法
- 用 keyset 分页(上一节)。
- 如果必须跳转到大 offset,考虑预计算(cache)或分区查询、倒排索引、物化。
16. 如何使用 EXPLAIN 分析查询?关注哪些列与含义
执行:
1 | EXPLAIN SELECT ...; |
关键列解释
id:查询序号,越大越早执行(子查询/union 时重要)。select_type:SIMPLE/PRIMARY/DERIVED/SUBQUERY/UNION 等。table:当前访问的表 (NULL/const/table name)。type(最重要的性能指标之一):system、const、eq_ref、ref、range、index、ALL(由好到差)。ALL= 全表扫描,range= 范围扫描(走索引),ref/eq_ref= 精确匹配索引。
possible_keys:优化器认为可能使用的索引。key:实际使用的索引(NULL 表示没有使用)。key_len:使用的索引长度(字节),表明索引使用了多少前缀。ref:索引列与哪些值比较(常数或其他列)。rows:优化器估算需要扫描的行数(越小越好)。Extra:其他信息(Using where、Using index、Using temporary、Using filesort、Using join buffer)。Using index= 覆盖索引(好);Using filesort或Using temporary说明排序/分组需要额外资源(可能慢)。
实践步骤
EXPLAIN看type/key/rows。若type=ALL或rows很大 → 优先优化。- 若
Using filesort或Using temporary→ 检查 ORDER BY/GROUP BY 是否能用索引或是否导致临时表(改索引/改SQL)。 - 用
EXPLAIN ANALYZE获取真实执行耗时和行数(有时估算与真实差异大)。
17. COUNT(*)、COUNT(1)、COUNT(列) 的区别
- COUNT(*):计数 行数(计数所有行,包括 NULL 列),对于 MyISAM 引擎是 O(1)(有表元数据),InnoDB 则通常需要扫描或走索引统计(没有存储全表行计数)。
- COUNT(1):语义与
COUNT(*)相同,MySQL 优化器会把它处理为计数行。 - COUNT(col):只计数该列非 NULL 的行数(忽略 NULL)。
优化点
- 若需要对全表计数并且不带 WHERE,使用 MyISAM(历史)会更快,但现代 InnoDB 下
COUNT(*)需要扫描索引或全表(可用一列非 NULL 索引优化)。 - 若要快速统计大表某条件的行数,考虑维护计数缓存或实时物化表。
18. SQL 聚合函数
- 聚合函数:
COUNT()、SUM()、AVG()、MAX()、MIN()、GROUP_CONCAT()。 - 实现细节:
- GROUP BY 会触发临时表和排序(若没有索引辅助),大数据量上会产生
Using temporary; Using filesort。 - 对于
SUM/AVG等,利用合适索引或预聚合表(materialized view)能显著提速。
- GROUP BY 会触发临时表和排序(若没有索引辅助),大数据量上会产生
- 优化:
- 对 group by 列建立联合索引可避免 filesort。
- 对频繁统计的维度表考虑预计算或 OLAP 引擎(ClickHouse、Druid、Presto)。
19. WHERE 与 HAVING 的区别)
- WHERE:在分组前对行做过滤(作用于源数据)。性能高,尽量把能在 WHERE 过滤的条件写在 WHERE。
- HAVING:在
GROUP BY后对分组后的聚合结果过滤(可以使用聚合函数,如HAVING SUM(x) > 100)。HAVING 需要先产生分组结果,成本较高。
示例
1 | SELECT user_id, SUM(amount) total |
20. EXISTS 与 IN 的区别(含 NULL/语义差异)
语义
IN(子查询)通常会先执行子查询(或优化成半连接)并在结果集上做匹配。EXISTS是相关子查询逐行判断,只要子查询对外层行存在匹配就返回 true(内层子查询常以 correlated subquery 形式出现)。
执行差异
- 对于非相关子查询,优化器可能将
IN重写成 semi-join(性能接近)。 - 对于相关子查询,
EXISTS通常更高效(提前短路),尤其当内层表有合适索引能快速定位时。
NULL 语义
IN的子查询结果中若存在NULL,在某些情况下会改变逻辑(导致不直观的行为),需谨慎。- 示例差异:
1 | -- 假设 subquery 返回 (1, NULL) |
实践建议
- 对于子查询较大或有相关情况,偏好
EXISTS或改写为 JOIN/SEMI-JOIN。 - 对于小静态列表(常量 list),
IN (v1,v2,...)非常合适。
21. SQL 注入 及 防范
原理
- 直接拼接字符串会把用户输入当成 SQL 代码执行,例如
"... WHERE id = " + userInput,若用户输入1 OR 1=1,将变为总是为真的条件。
防护措施
参数化查询 / PreparedStatement(最重要):使用占位符
?,数据库驱动负责转义与类型校验。1
2PreparedStatement ps = conn.prepareStatement("SELECT * FROM users WHERE login = ?");
ps.setString(1, userInput);白名单校验:对于列名、表名、排序字段等必须是字符串拼接处,先用白名单校验(只允许预定义值)。
最小权限原则:数据库账号只授予必要权限(应用不能用 root)。
防火墙/代理:使用 SQL 防火墙、WAF、审计机制。
ORM/框架功能:使用框架的查询构建器减少手写 SQL。
日志与检测:监控异常模式、慢查询、尝试注入字符串。
面试点:能举出具体注入示例、解释 PreparedStatement 原理(预编译、参数绑定)并能说明白名单的作用。
SQL 注入 — 原理与典型示例
原理(本质):当把不可信输入直接拼接到 SQL 文本里时,攻击者可以构造输入,使其成为 SQL 语句的一部分(即“把数据当成代码”),从而改变语句逻辑或执行额外命令。
常见注入类型与示例:
基于布尔/联合(Union / OR)
1
2
3// Vulnerable
String sql = "SELECT * FROM users WHERE id = " + userInput;
// userInput = "1 OR 1=1" -> SELECT * FROM users WHERE id = 1 OR 1=1结果:泄露全表数据或绕过认证。
基于错误(Error-based)
构造使 DB 抛错误,从错误信息中泄露数据/结构。联合查询(UNION)注入
在查询后追加UNION SELECT ...来读取其它表数据。时间盲注 / 布尔盲注
无直接输出时通过IF(condition, SLEEP(5), 0)等观察响应延迟或真假分支来抽取数据。存储/二次注入
恶意 payload 存入 DB,后续在另一处被拼接执行造成注入。
防护措施(核心与实践)
1. 参数化查询 / PreparedStatement(最重要)
示例(Java):
1 | String sql = "SELECT * FROM users WHERE login = ?"; |
为什么能防注入:
- 分离代码与数据:占位符
?在 SQL 语法中固定,参数作为数据绑定,不会被解析为 SQL 关键字或语句片段。 - 类型和转义由驱动/数据库负责:参数在发送到 DB 前/或由 DB 端绑定为常量值。
- 预编译(可缓存执行计划):数据库通常把 SQL 模板编译成执行计划,再把参数绑定执行(这也是性能加成)。注意:某些 JDBC 驱动对 PreparedStatement 可能做客户端仿真,但即便仿真也会做正确的转义/绑定,仍比拼接安全得多。
面试加分点:
- 说明预编译的细节:服务器端预编译 + 参数绑定,可防止注入并提升性能(减少解析开销)。
- 补充:某些驱动/DB 在网络层实现参数化或驱动端模拟,仍能防止注入,但最好确认驱动实现。
2. 白名单校验(用于标识符、排序字段等不能用占位符的场景)
占位符不能替换 SQL 标识符(如列名、表名、ORDER BY 字段)——这些必须在 SQL 文本中写出或拼接。此时必须用白名单:
1
2
3Set<String> allowedSort = Set.of("name","age","created_at");
if (!allowedSort.contains(userSort)) throw new IllegalArgumentException();
String sql = "SELECT * FROM users ORDER BY " + userSort;白名单保证只允许预期的、安全的标识符,拒绝任意输入。
3. 最小权限原则
- 应用使用的 DB 账户应只授予必要权限(SELECT/INSERT/UPDATE/DELETE 的子集),不要用
root或高权限账号执行应用 SQL,限制损害面。
4. 输入验证与输出转义(辅助)
- 对长度、格式、字符集做验证(但不要把它当作唯一防线)。
- 对动态生成给 UI 的内容做适当转义(防 XSS),与注入防护属于不同层。
5. 使用 ORM / 查询构建器(并正确使用参数化 API)
- 现代 ORM(Hibernate、MyBatis)提供参数化接口和占位符,正确使用能避免绝大多数注入问题。
- 但注意:不要把用户输入直接拼接成 HQL/SQL/OrderBy 字符串。
6. 防火墙 / 监控 / 审计
- 使用 WAF/数据库防火墙检测异常 SQL 模式(如
UNION SELECT、注入特征)并阻断。 - 日志与告警:监控异常查询、慢查询、重复错误模式。
7. 不要直接反序列化不可信数据 / 避免 eval
- 不要 eval 字符串形成 SQL 或通过反序列化直接执行任意语句。
示例对比(易读)
易被注入
1 | String sql = "SELECT * FROM users WHERE name = '" + userInput + "'"; |
若 userInput = "a' OR '1'='1" -> 成为 SQL
安全写法
1 | PreparedStatement ps = conn.prepareStatement("SELECT * FROM users WHERE name = ?"); |
其他面试可能追问与简洁回答要点
- Stored procedures 能否防注入?
- 如果所有输入都作为参数传入存储过程,并在 DB 端使用参数化执行,能降低风险;但存储过程内部若动态拼接 SQL 仍存在注入风险。不是万灵药。
- 为何不能对所有输入只做简单转义?
- 转义容易出错、依赖数据库方言、容易遗漏边界条件;参数化更稳健。
- 如何防盲注(time-based)?
- 参数化 + 严格 SQL 构造;WAF 可检测可疑延时查询;限制返回信息和错误信息。
- PreparedStatement 性能问题?
- 预编译使数据库可以缓存执行计划(提升性能)。在高并发 / 批量场景下,PreparedStatement 通常更快。
- 如何处理动态列/表名?
- 只能用白名单或映射表(不要直接用用户输入)。
面试一分种快速答法(可背)
- 原理:注入是把用户数据当作 SQL 代码执行。
- 首要防护:使用参数化查询 / PreparedStatement(分离代码与数据)。
- 补充策略:白名单(用于列名/排序等标识符)、最小权限、ORM + 参数化 API、WAF/监控、不要反序列化/执行不可信输入。
- 示例:展示一个拼接示例导致
OR 1=1,再给出 PreparedStatement 安全写法。
22. 将一张表部分数据更新到另一张表(多种方式)
场景:用 tableA 的某列更新 tableB。
写法 A:JOIN 更新(常见且高效)
1 | UPDATE tableB b |
写法 B:子查询方式
1 | UPDATE tableB b |
写法 C:INSERT … ON DUPLICATE KEY UPDATE(当要插入或更新)
1 | INSERT INTO tableB (id, col) |
实践说明
- JOIN 方式通常速度更快(单次扫描,优化器能做更好 join order)。
- 注意事务与锁(大批量更新建议分批处理)。
23. 如何将行转成列(行列转换 / Pivot)——常见 SQL 模式
方式 A:聚合 + CASE(最通用)
1 | SELECT id, |
方式 B:使用 GROUP_CONCAT(拼接)(当列类型多样且不定时)
方式 C:动态列 Pivot(需要动态 SQL)
- 若列类型不可预知,生成动态 SQL(查询 distinct 值并拼接 CASE 子句)。
性能考虑
- Pivot 多数需要扫描并分组,依赖 group by 索引/分区来加速;对大表要慎用或基于物化视图/ETL 做离线计算。
24. 表之间如何关联(关联方式详解)
常用方式
- JOIN(内联/外联):按条件联表(最常见)。
- 外键(FK)约束:数据库层面保障参照完整性(但大量外键在高并发写场景会影响性能)。
- 应用层关联:在代码层把多个小查询组装(用于跨库或性能考量)。
- 基于索引的查找(子查询/EXISTS):有时
EXISTS更高效。
实践选择
- 小表 join 大表用 hash join / nested loop 视执行计划;对分库分表场景,避免跨库 join(改在应用层做聚合或使用分布式查询引擎)。
25. INNER / LEFT / RIGHT JOIN 的区别(带例子)
- INNER JOIN:返回两表交集(满足 join 条件的行)。
- LEFT JOIN:返回左表所有行 + 匹配右表的行(右表无匹配则为 NULL)。
- RIGHT JOIN:返回右表所有行 + 匹配左表的行(左表无匹配则为 NULL)。
示例
1 | -- inner |
提示:LEFT JOIN 很多时候在逻辑上需要做 WHERE B.id IS NULL 来实现“左表存在右表不存在”的 anti-join(查找孤立记录),性能会受影响,建议用 NOT EXISTS 或 NOT IN(注意 NULL 行)做替代。
26. 为什么不推荐多表 JOIN?
问题多出自以下几点
- 成本指数增长:多表 join(尤其大表)会产生巨大的中间集(笛卡尔扩展风险),优化器不得当时性能爆炸。
- 跨库无法 JOIN:分库分表后跨库 JOIN 太昂贵或不支持。
- 可维护性差:SQL 复杂、难读、难改,调试困难。
- 优化器依赖统计:索引/统计不准时,join 顺序选择差导致大代价执行计划。
替代方案
- 应用层聚合:逐表查询并在应用层合并(适合分布式场景)。
- 预计算/物化:把复杂 join 结果写入聚合表(定期 ETL)。
- 使用 OLAP 引擎 / 搜索引擎:对于分析场景,使用专门的数据仓库(ClickHouse/Presto)或搜索(Elasticsearch)。
27. SQL 调优常见方法
- 索引策略
- 建覆盖索引、联合索引(按查询顺序)、避免冗余。
- 重写 SQL
- 避免函数作用于索引列,避免
SELECT *,拆分复杂查询。
- 避免函数作用于索引列,避免
- 分区/分库分表
- 水平分表(sharding)、分区表(MySQL partition)减少扫描边界。
- 缓存
- 热点数据用缓存(Redis);页面/查询使用缓存策略。
- 物化/预聚合
- 预计算汇总表/物化视图。
- 避免大事务
- 小批量提交,避免锁膨胀与 undo/redo 压力。
- 使用批量操作
- 批量 insert/replace/insert…on duplicate,使用 LOAD DATA INFILE。
- 避免无索引排序/分组
- 为 ORDER BY/GROUP BY 列建立索引,使之成为 index-only 操作。
- 分析执行计划
- EXPLAIN/EXPLAIN ANALYZE、慢查询日志、pt-query-digest 来定位瓶颈。
- 硬件与配置
- 调整 Buffer Pool(InnoDB)、innodb_flush_log_at_trx_commit、innodb_buffer_pool_instances、tmp_table_size、max_heap_table_size 等。
28. 如何监控并优化慢 SQL)
监控
- 打开
slow_query_log并设置合适阈值与日志轮转。 - 使用
pt-query-digest或线上 APM(Pinpoint、SkyWalking、Datadog)做聚合分析。
分析流程
- 收集慢 SQL(按耗时/锁/scan 行数排序)。
- 对单条慢 SQL 执行
EXPLAIN分析,关注type与rows。 - 检查索引覆盖性、是否 filesort 或 temporary。
- 若是锁等待导致慢,查看
SHOW ENGINE INNODB STATUS或INNODB_TRX、PROCESSLIST诊断锁冲突。 - 重写 SQL 或加索引并用
EXPLAIN验证。
线上处置
- 在高峰直接用
pt-kill/慢查询阻断/限流短时缓解(谨慎)。 - 对于极耗时的聚合,建议用异步/批处理/预计算。
29. 如何高效批量插入数据
多值 INSERT(比逐条插入快很多):
1
INSERT INTO t (a,b) VALUES (1,2),(3,4),(5,6);
LOAD DATA INFILE(最快,适合导入 CSV):
1
LOAD DATA INFILE '/tmp/data.csv' INTO TABLE t FIELDS TERMINATED BY ',' (a,b,c);
禁用索引/约束后导入(谨慎):
- 对 MyISAM 可
ALTER TABLE t DISABLE KEYS导入后ENABLE KEYS,对 InnoDB 不适用同样方式,建议分批或临时删除二级索引后导入再重建。
- 对 MyISAM 可
控制事务大小:大批量分成多个事务(如每 5k 行一提交)以避免过大 undo/redo。
关闭二进制日志(临时):在可接受风险下短时关闭 binlog 可提速,但会丢失复制/恢复能力(通常不建议在生产主库上做)。
使用并发导入:分表并发导入,每个线程导入不同数据段(受 IO/CPU 限制)。
30. 大表(千万级)查询 / 维护
设计阶段
- 逻辑分库分表:按业务或哈希分片分布数据,减少单表压力。
- 分区表(range/list/hash)用于热冷分离与分区裁剪(partition pruning)。
索引与查询
- 给热点查询建覆盖索引,避免回表。
- 使用分区键/分片键作为查询条件以利用分区 / 分片定向扫描。
维护
- 分批删除(不要一次性 delete 大量行):
- 分段删除
DELETE FROM t WHERE id BETWEEN x AND y每次限制 batch size。 - 或使用
ALTER TABLE ... DROP PARTITION(若按时间分区)来快速删除历史数据。
- 分段删除
- 重建索引:在线工具(gh-ost / pt-online-schema-change)做 index rebuild。
- 归档:将历史冷数据移出到分析库或对象存储。
- 监控:慢查询、表扫描、锁等待、IO 使用情况。
备份
- 使用物理备份(XtraBackup)做热备份,避免在线 mysqldump 导致性能问题。
31. DELETE、TRUNCATE、DROP 区别
DELETE
- DML 操作,逐行删除(执行 DELETE 语句会为每行生成 undo/redo),触发器触发,事务可回滚。
- 对大表慢且会产生大量 undo/log。
TRUNCATE
- DDL 操作(在 MySQL 中通常为 drop + create 或快速清空表),效果等同于删除所有数据并重置 AUTO_INCREMENT(实现依引擎不同)。
- 通常不可回滚(会隐式提交当前事务)。
- 快速、不会逐行触发 DELETE 触发器(因为不是逐行删除)。
DROP
- 删除整个表结构与数据,删除后元数据也不存在。
- 同样通常是 DDL、会释放表空间(取决于引擎/配置)。
实践建议
- 需要可回滚删除历史数据:做分批 DELETE 并通过事务或备份策略应对回滚需求。
- 需要快速清空表(并接受隐式提交):用 TRUNCATE。
- 需要删除表与结构:DROP。
Java多线程-牛客面经八股
1. 线程的创建方式(Java 中常见 4 种、及实际工程常用模式)
方式 A — 继承 Thread
1 | class MyThread extends Thread { |
- 优点:直观。
- 缺点:无法共享 Runnable,再继承受限。
方式 B — 实现 Runnable(最常用)
1 | class MyTask implements Runnable { public void run(){ /* ... */ } } |
- 优点:任务与线程分离,能被线程池复用。
方式 C — 实现 Callable<V> + FutureTask(可返回值、可抛异常)
1 | Callable<Integer> c = () -> 42; |
- 常与
ExecutorService.submit(callable)配合使用。
方式 D — 通过 ExecutorService / 线程池(推荐)
1 | ExecutorService pool = Executors.newFixedThreadPool(4); |
- 生产环境首选;管理线程生命周期、复用、任务队列、异常处理。
补充:Fork/Join 与虚拟线程
ForkJoinPool/RecursiveTask:用于分治并行计算。- JDK 19+ Project Loom:虚拟线程(轻量级,数十万并发)——尚在演进,注意与同步/阻塞交互。
2. 线程的生命周期和状态(Java Thread.State)
六种状态(Java 枚举 Thread.State):
NEW:刚创建,未调用start()。RUNNABLE:可运行或正在运行(在 JVM/OS 中可能是 runnable 或 running)。BLOCKED:阻塞在 monitor(即等待进入synchronized的监视器)。WAITING:等待另一个线程显式唤醒(Object.wait()/Thread.join()/LockSupport.park())——无限期等待。TIMED_WAITING:带超时的等待(sleep(ms)、带 timeout 的wait/join/parkNanos)。TERMINATED:已执行完毕或发生未捕获异常导致终止。
典型状态转移
NEW->start()->RUNNABLERUNNABLE->sleep()->TIMED_WAITING-> 超时 ->RUNNABLERUNNABLE->synchronized被其他线程持有 ->BLOCKED-> 获得锁 ->RUNNABLERUNNABLE->wait()->WAITING->notify()->RUNNABLERUNNABLE-> 结束执行 ->TERMINATED
面试点:RUNNABLE 在 JVM 层既包含“可运行队列”也包含“正在运行(OS thread)”两种含义;BLOCKED 专指等待 monitor。
3. wait() 与 sleep() 的区别(关键点)
| 特性 | wait()(Object) |
sleep()(Thread) |
|---|---|---|
| 是否释放锁 | 释放当前对象监视器锁(必须在同步块/方法内调用) | 不释放锁(不需要在同步块) |
| 所在类 | Object(每个对象有 wait set) |
Thread |
| 被唤醒方式 | notify() / notifyAll() 或 InterruptedException |
超时或被中断(interrupt()) |
| 适用场景 | 线程间协调(生产/消费),需要条件等待 | 线程暂停,不用于线程间协作(定时) |
示例
1 | synchronized(lock) { |
4. 线程同步方式
- 内置锁(synchronized):基于对象监视器(monitor),支持重入、wait/notify、JVM 优化(偏向、轻量级、重量级)。
- 显式锁(
java.util.concurrent.locks.Lock):ReentrantLock、ReadWriteLock,支持可中断锁获取、tryLock、Condition。 - AQS(AbstractQueuedSynchronizer)+ 基于队列的同步器:ReentrantLock、Semaphore、CountDownLatch、FutureTask 等底层支持类。
- 原子变量(
java.util.concurrent.atomic):CAS(AtomicInteger、AtomicReference)、乐观并发,不阻塞。 - 并发集合:
ConcurrentHashMap、CopyOnWriteArrayList、BlockingQueue等内部有并发控制。 - 并发工具类:
Semaphore、CountDownLatch、CyclicBarrier、Phaser(协调线程)等。 - 线程间通信:
wait/notify、Lock+Condition、BlockingQueue(生产-消费模式里推荐BlockingQueue)。
建议:尽可能使用 java.util.concurrent 提供的高层抽象(线程池 + 阻塞队列 + 原子类)而不用自己低级实现。
5. synchronized 与 Lock 的区别
共同点:都能保证互斥与可见性(互斥与内存可见性由 JMM 和实现共同保证)。
synchronized(内置监视器)
- 优点:用法简单、异常安全(自动释放锁)、JVM 优化强(偏向锁、轻量级锁、锁消除/合并)。
- 缺点:功能有限(不支持
tryLock、超时、可中断),不支持多个条件队列。
Lock(显式锁)
- 优点:支持
tryLock、lockInterruptibly、可中断、支持超时、多个Condition(类似多个 wait-set),更灵活。 - 缺点:编程复杂,必须在 finally 中
unlock(),否则易死锁;性能在低争用时可能和synchronized相近或稍慢,但高争用时ReentrantLock可优于synchronized(尤其是公平/非公平策略控制)。
举例
1 | Lock lock = new ReentrantLock(); |
6. synchronized 的用法及原理
用法
- 修饰实例方法:
synchronized void m()→ 锁住this - 修饰静态方法:
synchronized static void m()→ 锁住 Class 对象 (Class<?>) - 同步代码块:
synchronized(lockObj) { ... }→ 锁住lockObj
实现原理(HotSpot)
- JVM 层面:对象头(Mark Word)中存有锁标记,JVM 通过 CAS 操作对象头来尝试获取锁。
- 锁优化流程(热点优化):
- 偏向锁(偏向单线程场景,避免 CAS)
- 轻量级锁(使用 CAS 在栈上记录锁记录)
- 重量级锁(monitor)(线程竞争时进入操作系统互斥锁,使用 OS mutex/park/unpark)
monitorenter/monitorexit字节码对应 JVM 的锁进入/释放操作。wait():会把线程放入对象的 wait-set,释放 monitor 并进入 WAITING;notify()会把某线程从 wait-set 移入到 entry-list(竞争 monitor)。
重入性:同一线程重复获得同一 monitor,JVM 内部会记录递归计数,释放时减少计数。
JVM 优化:JIT 可做锁消除(如逃逸分析)或锁粗化(合并多次临近锁)以减少开销。
7. 对 AQS(AbstractQueuedSynchronizer)的理解(关键概念、内部结构与工作流程)
用途:AQS 是 JDK 提供的用于构建锁和同步器的基础框架(基于 FIFO 队列),ReentrantLock、Semaphore、CountDownLatch、FutureTask 等都基于 AQS。
核心字段
volatile int state:表示同步状态(不同同步器含义不同,例如ReentrantLock用低位计重入,Semaphore用作许可计数)。volatile Node head, tail:双向队列头尾,队列实现 CLH 风格(FIFO),节点代表线程等待队列。Node的waitStatus(CANCELLED,SIGNAL,CONDITION,PROPAGATE等)。
两种模式
- 独占模式(Exclusive):只有一个线程能占有(例如
ReentrantLock的 writeLock)。- API hook:
tryAcquire(int)、tryRelease(int)、isHeldExclusively()。
- API hook:
- 共享模式(Shared):多个线程可同时占有(例如
Semaphore,ReadLock的一些实现)。- API hook:
tryAcquireShared(int)、tryReleaseShared(int)。
- API hook:
获取锁的高层流程(独占)
- 调用
acquire(arg)。首先尝试tryAcquire(arg)(子类实现)——若成功,直接返回。 - 若失败,线程封装为 Node 并入队(CAS 设置 tail)。
- 线程在队列中循序等待,前驱释放时唤醒后继线程(
unpark),然后重试tryAcquire,直到成功或超时/中断。 - 释放时
tryRelease被调用,成功后会unpark下一个等待线程。
Condition(条件队列)
AQS 提供 ConditionObject,将等待线程放到 Condition 队列(与 AQS 队列分开),await() 会把当前线程迁移到 Condition 队列并释放同步状态,signal() 会把线程移回同步队列,等待获取锁。
实现细节亮点
- 使用
Unsafe.compareAndSwapInt做 state、head、tail 的原子更新(CAS)。 LockSupport.park/unpark用于线程挂起/唤醒(比wait/notify更灵活,不要求持有 monitor)。- AQS 还处理中断、超时、取消节点、队列清理等复杂逻辑。
8. 如何创建线程池?线程池常见参数有哪些?(ThreadPoolExecutor 深入)
推荐方式:直接使用 ThreadPoolExecutor 构造(不要盲用 Executors 的工厂方法在生产环境,因其某些返回队列为无界会隐藏风险)。
常用构造器参数
1 | ThreadPoolExecutor( |
corePoolSize:核心线程数(默认维护即使空闲也不回收,除非allowCoreThreadTimeOut(true))。maximumPoolSize:最大线程数。keepAliveTime:非核心线程空闲存活时间。workQueue:任务队列(ArrayBlockingQueue/LinkedBlockingQueue/SynchronousQueue/PriorityBlockingQueue等)。threadFactory:创建线程(可定制名字、daemon、优先级、异常处理)。handler:拒绝策略(AbortPolicy、CallerRunsPolicy、DiscardPolicy、DiscardOldestPolicy或自定义)。
执行策略(重要)
- 如果运行中的线程数 <
corePoolSize,立即启动新线程处理任务; - else 如果工作队列未满,任务入队;
- else 如果线程数 <
maximumPoolSize,启动新线程处理任务; - else 拒绝任务(触发
RejectedExecutionHandler)。
线程池与队列配合示例
LinkedBlockingQueue(默认无界)+maximumPoolSize无效(因为队列不满就入队)SynchronousQueue(零容量)强制快速扩展线程数,常与maximumPoolSize配合(适合短任务高并发)
线程池参数调优建议
- CPU 密集型:
poolSize ≈ Ncpu或Ncpu+1。 - IO 密集型:
poolSize ≈ Ncpu * (1 + wait/io ratio)。 - 使用 bounded queue + proper rejection handling + metrics(队列长度、活跃线程数、任务提交速率)才安全。
示例
1 | ThreadPoolExecutor pool = new ThreadPoolExecutor( |
9. volatile 的用法及原理(Java 内存语义)
语义
volatile变量具有 可见性:写入一个 volatile 变量后,对该变量的写入对随后读取该变量的所有线程可见(建立happens-before)。- 禁止指令重排序(部分):volatile 写有 释放(release)语义,volatile 读有 获取(acquire)语义。写
volatile之前的操作不会被搬到写之后;读volatile之后的操作不会被搬到读之前(强制内存屏障)。 - 不保证原子性(复合操作如
i++不是原子)。
实现原理(HotSpot)
- Java 编译器/CPU 内存屏障(fence)+ JVM intrinsics:volatile 写会产生 StoreStore + StoreLoad 屏障(或更严格),volatile 读会产生 LoadLoad + LoadStore 屏障,保证内存可见性和一定顺序。
典型使用场景
- 状态标志(
volatile boolean running),用于停止线程。 - 双重检查锁(DCL)中
volatile修饰单例(防止构造对象引用外逃)。 - 轻量级的可见性需求,不需完整锁开销的场景。
示例(停止线程)
1 | volatile boolean running = true; |
10. ThreadLocal 的用法和实现原理(ThreadLocalMap)
用途
- 为每个线程维护独立的变量副本(例如:用户上下文、SimpleDateFormat、DB session 等),避免锁竞争。
使用
1 | private static final ThreadLocal<SimpleDateFormat> TL = |
实现原理
- 每个
Thread对象内部维护一个ThreadLocalMap(不是全局 map),键是ThreadLocal<?>的弱引用(WeakReference<ThreadLocal<?>>),值是强引用到实际对象。 ThreadLocalMap是数组 + open addressing(线性探测)实现,ThreadLocal有自己的 hash(threadLocalHashCode)。
内存泄露风险(关键点)
ThreadLocal的 key 是弱引用,若你把ThreadLocal变量设为局部变量或在某个类中只保存弱引用并丢弃强引用,key 可能被 GC,但ThreadLocalMap中的该 entry 的 value 是强引用,不会自动被清理(直到下一次ThreadLocal操作或某次ThreadLocalMap执行 expungeStaleEntries)。- 在使用线程池时线程不会死亡,ThreadLocal 的 value 若不显式
remove()会一直占用内存 → 导致内存泄漏。
防范:在finally中调用remove(),避免把ThreadLocal设为静态且不清理。
11. Java 里的 CAS(Compare-And-Swap)(概念 + 使用)
概念
- CAS 是无锁编程的原子操作:比较内存中的某个位置的当前值
V与期望值A,若相等则将其更新为B;否则不更新。返回是否成功。 - Java 通过
Unsafe.compareAndSwapInt/Long/Object或VarHandle提供 CAS。
常见用法
AtomicInteger、AtomicReference的compareAndSet()。- 在自旋循环中:
1 | int expect, update; |
优点:避免阻塞、低延迟(无上下文切换)
缺点:高并发下自旋会浪费 CPU、需要重试(活跃性 vs 饥饿可能),存在 ABA 问题。
12. CAS 会出现什么问题?ABA 问题如何解决?
问题
- ABA 问题:线程 T1 读取值 A;T2 把 A -> B -> A(短时间内);T1 执行 CAS 发现仍为 A,误以为未被修改过。
- 自旋开销:长时间重试浪费 CPU。
- 只解决单变量原子性:复杂更新需要分步或额外同步。
解决 ABA 的常见方法
- 版本号(带标记):把值与版本(stamp)一起 CAS(
AtomicStampedReference),每次修改版本号+1。CAS 检查不仅值还检查版本。 AtomicMarkableReference/AtomicStampedReference:JDK 提供两种封装用于区分状态。- 垃圾回收/内存管理策略:在某些场景中使用 GC 或引用计数减少 ABA 可能性(语言/平台相关)。
13. Java 线程与操作系统线程区别(概念与 HotSpot 实现)
Java 线程(java.lang.Thread)
- Java 层的抽象,描述执行单元。
- HotSpot 自 JDK1.3 之后使用 1:1 映射 到 OS 原生线程(native threads)。早期某些 JVM 可能使用 green threads(用户级线程),但现在主流 JVM 都用 native threads。
区别/联系
- 调度:实际由操作系统调度(time slice, priority);JVM 可以调用
park/unpark/suspend(deprecated) 来配合。 - 资源:OS 线程有系统栈、线程控制块等,开销大;虚拟线程(Loom)是 JVM 层的轻量线程,调度由 JVM 管理、挂起成本低。
- 中断与同步语义:Java 定义了一套线程中断、锁语义、内存模型(JMM)抽象,这些由 JVM 映射成 OS 调用与内存屏障实现。
14. Java 中如何检测死锁?如何预防和避免线程死锁?
检测死锁方法
- ThreadMXBean(JMX):
1 | ThreadMXBean tm = ManagementFactory.getThreadMXBean(); |
- jstack:在生产上拿多份线程 dump(间隔几秒)观察是否多线程相互持有对方锁并等待
Found one Java-level deadlock。
死锁产生条件(四必要条件)
- 互斥(至少一个资源被独占)
- 占有且等待(线程持有资源且等待其他资源)
- 不可抢占(资源不能被强行从线程拿走)
- 环路等待(A 等待 B,B 等待 C,…,Z 等待 A)
预防与避免策略
- 统一加锁顺序:保证多个线程按固定顺序获取锁(最简单有效)。
- 使用
tryLock(timeout):若没有获得锁,回退并重试或按其它逻辑处理,防止永远等待。 - 减少锁粒度/持有时间:尽量把临界区缩小。
- 资源分配策略:一次性申请全部需要的锁或使用锁分层。
- 避免嵌套锁:尽量减少持有锁时去请求别的锁。
- 使用无锁/乐观算法:如 CAS、Concurrent Collections 等。
15. 写一个 Java 死锁的例子(示例代码)
1 | public class DeadlockDemo { |
- 结果:可能出现 t1 持有 A 等待 B,t2 持有 B 等待 A → 永久阻塞(死锁)。
16. volatile 可以保证原子性么?
结论:不能保证复合操作的原子性(例如 i++ 不是原子)。
- 单次读/写
volatile对象或基本类型(除 long/double 在早期 JVM)是原子性的(JMM 保证对volatile long/double的写也是原子的)。 - 若需要原子复合操作,使用
synchronized或AtomicInteger/AtomicLong。
17. 公平锁与非公平锁有什么区别?
公平锁:线程获取锁的顺序按照请求顺序(FIFO)。能防止饥饿,但吞吐量较低(因为每次释放后必须唤醒队列头部线程,且上下文切换频率更高)。new ReentrantLock(true) 表示公平锁。
非公平锁(默认):释放锁后线程可以“插队”再次获取(即有竞争时当前线程更可能再次拿到锁),可提高吞吐量但可能导致某些线程饥饿。
synchronized 在 HotSpot 实现中是非公平的(存在偏向锁、轻量级锁优化)。
18. 乐观锁与悲观锁(思想 + 典型实现)
悲观锁
- 假设并发会导致冲突,进入临界区前先加锁(阻塞其他线程)。
- 典型实现:
synchronized、ReentrantLock(独占锁)。
乐观锁
- 假设并发冲突少,用无锁方式尝试更新,冲突发生时回退重试。
- 典型实现:CAS(
Atomic*类)、数据库中的version字段 +WHERE version = ?(乐观更新) - 优点:在读多写少时能极大提高并发;缺点:高冲突时会频繁重试,性能下降。
实际选择:大并发读、少量写可选乐观锁;高冲突写密集场景选悲观锁。
19. synchronized 和 volatile 的区别(再对比)
synchronized:互斥 + 可见性(保证原子性、互斥进入临界区、自动释放锁),并且实现了内存可见性(通过 monitorenter/monitorexit)。volatile:只保证可见性与一定的指令序(禁止某些重排序),不保证原子性。不能用来保护复合操作。
总结:volatile 适合标志位等轻量同步;synchronized 适合需要原子修改共享状态的场景。
20. ReentrantLock 的定义和特性
定义:ReentrantLock 是 Lock 接口的可重入实现(基于 AQS)。
主要特性
- 可重入:同一线程可多次获取,AQS
state记录重入次数。 - 可中断获取锁:
lockInterruptibly()支持响应中断。 - 支持超时获取:
tryLock(long timeout, TimeUnit unit)。 - 支持公平/非公平策略:构造器接受
fair标志。 - Condition 支持:
lock.newCondition()提供比 Object.wait/notify 更灵活的多个条件队列。
示例
1 | ReentrantLock lock = new ReentrantLock(); |
21. ReentrantReadWriteLock 的使用场景
用途:读多写少场景:允许多个线程并发读,但写时独占(读写互斥)。
使用场景:
- 缓存/内存共享资源频繁读、偶尔写:例如配置缓存、只读数据查询等。
注意点: - 写锁获取时会等待所有读锁释放,读锁在写等待时可导致写饥饿(默认实现有写锁优先或公平选项可用)。
- 读锁内部实现较复杂(基于 AQS 的 state 高 16 位或低位用于计数,实际设计细节会随 JDK 版本微调)。
示例
1 | ReentrantReadWriteLock rw = new ReentrantReadWriteLock(); |
22. ThreadLocal 内存泄露如何导致的?
具体机理:
Thread对象持有ThreadLocalMap,该 map 的 key 是WeakReference<ThreadLocal<?>>,value 是强引用。- 若 ThreadLocal 实例被外部丢弃(例如设置为 null),key 弱引用会被 GC 回收 →
ThreadLocalMap中该 entry 的 key 变为null,但 value 仍然是强引用,不会被回收,导致内存泄露。 - 在使用线程池时,线程会被复用,不会结束,entry 永远存在,产生长期泄露。
防范
- 在使用
ThreadLocal的地方确保remove()(尤其在线程池中使用时)。 - 避免把 ThreadLocal 当成静态缓存存放大量对象,或确保在任务结束时清理。
- 使用 try/finally:
1 | threadLocal.set(obj); |
23. 线程池常用的阻塞队列(BlockingQueue)
ArrayBlockingQueue:有界、基于数组、固定容量、可选择公平策略。LinkedBlockingQueue:常用,可有界或无界(默认无界),吞吐高。SynchronousQueue:不存储元素,直接交接,适合短任务,配合maximumPoolSize扩展线程。PriorityBlockingQueue:优先级队列,元素需实现Comparable(或传入 Comparator),注意是无界队列(默认)。DelayQueue:延迟队列(任务带延迟),常和调度/延时任务配合。LinkedTransferQueue:高性能无界队列,支持 transfer semantics。
要点:队列的选择强烈影响线程池行为(是否会扩容、是否会阻塞生产者等)。
24. 设计一个线程池,使其按任务优先级运行(思路 + 注意)
思路:使用 PriorityBlockingQueue<Runnable> 作为任务队列,任务实现 Comparable(或包装一个 PriorityRunnable)。
问题/注意:
PriorityBlockingQueue默认是无界的,可能导致maximumPoolSize无效(因为队列永远不满,不会触发扩容),通常搭配 bounded wrapper 或自定义拒绝策略。- 由于优先级队列不保证相同优先级的 FIFO 顺序,若需要稳定顺序需在比较器中包含序号。
实现示例
1 | class PriorityRunnable implements Runnable, Comparable<PriorityRunnable> { |
更好方案:若要有界行为且保持优先级,使用 PriorityBlockingQueue + Semaphore 或自定义 bounded priority queue。
25. Callable 和 Future(区别与使用)
Callable<V>:任务接口,V call()可返回结果并抛异常。Future<V>:表示异步计算的结果句柄,常用方法:get()(阻塞拿结果)、cancel()、isDone()、isCancelled()。FutureTask<V>:同时实现Runnable和Future,可被Executor执行并支持get()。
示例
1 | ExecutorService pool = Executors.newFixedThreadPool(2); |
26. Semaphore 有什么用?(原理与常见用途)
概念:信号量,用来控制访问某类资源的并发数量(许可数 permits)。可以公平或非公平。内部基于 AQS(共享模式)。
常见用途
- 连接池并发控制:限制同时获取 DB 连接的线程数。
- 限流:例如并发请求数控制。
- 保护稀缺资源。
示例
1 | Semaphore sem = new Semaphore(10); |
27. CountDownLatch 有什么用?(用途、内部与示例)
概念:一次性计数器,初始化一个计数 N,调用 countDown() 将计数减 1;await() 阻塞直到计数为 0。底层基于 AQS(共享模式)。
用途
- 等待多个初始化任务完成(主线程等待多个子线程加载资源)。
- 简单的线程同步点(一次性的 barrier)。
示例
1 | CountDownLatch latch = new CountDownLatch(3); |
不可重用:CountDownLatch 一旦计数到 0 就不能复位(若需复用用 CyclicBarrier 或 Phaser)。
附:一些常见面试问答扩展(精选应答)
- 如何检测死锁:用
ThreadMXBean.findDeadlockedThreads()或jstack多份堆栈分析。 - 如何避免索引/线程池级别死锁或线程饥饿:统一锁顺序、使用
tryLock(timeout)、合理配置池大小和队列。 - 何时用 volatile vs Atomic vs synchronized:
volatile:只需可见性/禁止重排序的标志位;Atomic*:需要原子更新但无复杂互斥;synchronized/Lock:需要复杂的互斥逻辑、条件等待或复合操作原子性时使用。
- 为什么 prefer ExecutorService:线程复用、统一异常处理、资源控制、监控与伸缩。
测试理论基础-牛客面经八股
好的 ✅,这一组问题涉及 软件测试基础、测试设计方法、Bug管理、性能测试、接口测试 等核心知识点。我会逐题展开,保证细节和深度,适合面试八股 + 实际场景。
1、黑盒测试与白盒测试的区别是什么?
- 黑盒测试(功能测试)
- 关注点:功能是否符合需求说明书,不关心内部实现。
- 特点:输入 → 输出,测试员像用户一样。
- 方法:等价类划分、边界值、因果图、判定表。
- 优点:贴近用户,容易发现功能缺陷。
- 缺点:覆盖率有限,不能发现内部逻辑错误。
- 白盒测试(结构测试)
- 关注点:程序代码逻辑、语句、分支、条件。
- 特点:需要了解源码。
- 方法:语句覆盖、分支覆盖、条件覆盖、路径覆盖。
- 优点:能发现隐藏的逻辑漏洞。
- 缺点:需要开发技能,难以覆盖大规模系统。
👉 实际项目中:黑盒为主,白盒为辅。
2、什么是冒烟测试?
- 定义:冒烟测试是一种快速验证构建质量的测试方式,验证核心功能是否正常。
- 目标:确保系统的基本功能可用,构建稳定,适合进一步测试。
- 特点:
- 测试范围小,但覆盖核心功能。
- 常常自动化(CI/CD 中构建后立即跑冒烟测试)。
- 比喻:像开机时先通电 → 如果冒烟,就说明问题大,没必要继续测试。
3、测试用例设计时需要注意什么?提Bug需要注意哪些点?
- 测试用例注意点:
- 覆盖需求的每个点。
- 既考虑正常场景(正向用例),也考虑异常输入(逆向用例)。
- 优先级划分(P0/P1/P2)。
- 可复现、可执行、结果可验证。
- 提Bug注意点:
- 完整性:复现步骤、期望结果、实际结果、环境信息。
- 准确性:确认是 Bug,而不是需求不符或环境问题。
- 复现率:提供最小复现条件。
- 影响评估:说明 Bug 的严重性、优先级。
4、了解Bug的逃逸率吗?怎么降低?
- Bug逃逸率:指 测试未发现而用户发现的Bug / 总Bug数。
- 公式:Bug逃逸率 = 生产环境发现的Bug数 ÷ 总Bug数 × 100%
- 降低方法:
- 需求评审:保证需求清晰。
- 测试用例设计全面,覆盖边界、异常场景。
- 加强自动化测试(单测、接口、UI)。
- 增加性能、兼容、异常测试。
- 回归测试保证修复不引入新Bug。
5、测试报告是怎么写的?
一个完整的 测试报告 包括:
- 背景:测试版本、时间、测试范围。
- 测试内容:功能点列表,覆盖情况。
- 测试执行结果:
- 用例数:总数 / 执行数 / 通过 / 失败。
- Bug数量:总数、已解决、未解决、按严重级别分类。
- 风险与遗留问题:哪些Bug未解决,可能影响哪些功能。
- 结论与建议:是否建议上线,注意事项。
6、你有没有接触一些和AI相关的自动化测试?
- AI在自动化测试中的应用:
- 智能元素识别:传统 UI 自动化容易因 DOM 变化失败,AI 可做视觉识别(OCR + 图像识别)。
- 智能用例生成:基于需求文档、日志分析,自动生成测试用例。
- 异常检测:AI 可基于日志或监控,自动识别异常模式。
- 智能 Bug 分析:根据历史数据,预测 Bug 可能的根因。
👉 越来越多企业用 AI + 自动化测试平台(Selenium、Appium + AI 辅助)。
7、性能测试怎么做?需要关注哪些指标?
- 性能测试目标:验证系统在高并发、大数据量情况下的表现。
- 方法:
- 使用工具:JMeter、LoadRunner、Locust。
- 模拟用户请求,逐步加压。
- 关注指标:
- 吞吐量(TPS/QPS)
- 响应时间(RT,P90/P95/P99)
- 并发用户数
- CPU、内存、IO、带宽
- 错误率
- 场景:
- 压力测试:极限承载。
- 负载测试:逐渐增加并发。
- 稳定性测试:长时间运行。
8、如何判断一个Bug是前端还是后端引起的?
- 判断思路:
- 接口测试:
- 如果接口返回异常 → 后端问题。
- 接口正常但页面展示错误 → 前端问题。
- 抓包 / 调试工具:Fiddler、Postman、浏览器 Network。
- 日志分析:
- 前端控制台报错。
- 后端日志报错(异常栈、SQL错误)。
- 复现路径:
- 单接口调试通过,前端渲染有问题 → 前端。
- 单接口调试失败 → 后端。
- 接口测试:
9、接口测试工具及方法、接口自动化框架搭建及参数化实现
- 接口测试工具:Postman、JMeter、Swagger、Apifox。
- 方法:
- 验证请求参数、返回值、状态码。
- 验证业务逻辑、异常处理。
- 安全性(SQL注入、越权访问)。
- 接口自动化框架:
- 语言:Java(RestAssured + TestNG)、Python(pytest + requests)。
- 框架结构:用例层 → 数据驱动层 → 公共方法层 → 报告层。
- 参数化实现:用 Excel/CSV/JSON/YAML 存储数据,框架读取并循环执行。
👉 最终实现 持续集成(CI)+ 持续交付(CD)。
10、除了功能测试、性能测试,还有什么测试类型?
- 安全测试:SQL注入、XSS、CSRF。
- 兼容性测试:不同浏览器、不同设备。
- 可用性测试:用户体验。
- 接口测试。
- 回归测试。
- 可靠性测试。
- 并发测试。
- 灰度测试 / A/B 测试。
11、发现了支付成功但后台订单未生成的问题,从发现到提交Bug会做哪些工作?
- 确认现象:
- 支付是否真实成功(第三方支付回调成功?)。
- 是否是单次还是批量问题。
- 排查前端:
- 看请求是否正确发出。
- 参数是否正确传递。
- 排查后端:
- 查看日志(支付回调、订单生成流程)。
- 是否卡在消息队列 / 数据库。
- 复现Bug:
- 在测试环境复现,确认稳定。
- 提交Bug:
- 标题:支付成功订单未生成。
- 复现步骤:支付流程、支付工具。
- 期望结果:支付成功后生成订单。
- 实际结果:未生成。
- 环境信息:测试环境 / 生产环境。
- 附加信息:接口请求/响应、日志。
HTTP/HTTPS-牛客面经八股
太好了 ✅,这组题目涉及 HTTP 协议全家桶(1.0 → 3.0 演进、状态码、缓存、HTTPS、WebSocket、SSE),是前端/后端/运维面试的高频考点。我逐个给你讲,保证深入、细节全,既能应对面试,也能真正理解。
1、HTTP/1.0、HTTP/1.1、HTTP/2.0、HTTP/3.0 的区别?
- HTTP/1.0(1996)
- 短连接:每次请求都要建立 TCP 连接。
- 只支持
GET/POST/HEAD方法。 - 缺少 Host 头,不支持虚拟主机。
- HTTP/1.1(1999)
- 长连接(Connection: keep-alive),复用 TCP。
- 新增方法:
PUT/DELETE/OPTIONS。 - 支持 管道化(Pipelining),但容易队头阻塞。
- 缓存控制:
Cache-Control。
- HTTP/2.0(2015,基于 SPDY)
- 二进制分帧,效率更高。
- 多路复用:一个 TCP 连接上并发多个请求,解决队头阻塞(但仍受 TCP 队头阻塞影响)。
- 头部压缩(HPACK),减少带宽。
- 服务端推送。
- HTTP/3.0(2022,基于 QUIC/UDP)
- QUIC 协议(UDP + TLS 1.3),彻底解决 TCP 队头阻塞。
- 连接迁移(换 IP 也不中断)。
- 更快的握手(1-RTT / 0-RTT)。
👉 总结:1.0 短连接 → 1.1 长连接 → 2.0 多路复用 → 3.0 基于 UDP。
2、HTTP 常见状态码有哪些?
- 1xx:信息(100 Continue)
- 2xx:成功(200 OK,201 Created,204 No Content)
- 3xx:重定向(301 永久,302 临时,304 Not Modified)
- 4xx:客户端错误(400 Bad Request,401 Unauthorized,403 Forbidden,404 Not Found,405 Method Not Allowed)
- 5xx:服务端错误(500 Internal Server Error,502 Bad Gateway,503 Service Unavailable,504 Gateway Timeout)
3、HTTP 请求头中到底包含什么?
常见请求头分为几类:
- 通用头:
Date,Connection - 请求头:
Host,User-Agent,Accept,Referer,Cookie - 响应头:
Server,Set-Cookie,Location - 实体头:
Content-Type,Content-Length,Content-Encoding
4、HTTP 是基于 TCP 还是 UDP?
- HTTP/1.0 & HTTP/1.1 & HTTP/2.0 → 基于 TCP
- HTTP/3.0 → 基于 QUIC(UDP)
👉 所以,HTTP 主要基于 TCP,但最新版本用 UDP。
5、HTTP 常见字段有哪些?
- 缓存相关:
Cache-Control,Expires,ETag,Last-Modified - 内容相关:
Content-Type,Content-Length,Content-Encoding - 连接相关:
Connection,Keep-Alive - 安全相关:
Cookie,Set-Cookie,Authorization
6、HTTP 的缓存机制,服务器如何判断缓存是否过期?
- 强制缓存(Expires / Cache-Control)
Expires: Wed, 21 Oct 2025 07:28:00 GMT(绝对时间)Cache-Control: max-age=3600(相对时间)
👉 未过期 → 直接用本地缓存。
- 协商缓存(ETag / Last-Modified)
ETag(文件唯一标识) → If-None-MatchLast-Modified→ If-Modified-Since
👉 服务器校验后返回 304 Not Modified。
7、HTTP 长连接 vs 短连接的区别是?
- 短连接(1.0):一次请求/响应就关闭连接。
- 长连接(1.1 Keep-Alive):多个请求复用一个 TCP 连接,减少握手开销。
8、从「敲下一个 URL」到「页面出现在屏幕」整条链路全景
- 浏览器解析 URL,检查缓存(强缓存/协商缓存)。
- DNS 解析域名 → 得到 IP。
- 建立 TCP/UDP 连接(TLS 握手)。
- 发送 HTTP 请求。
- 服务器处理请求,返回响应(HTML/CSS/JS)。
- 浏览器解析 HTML,构建 DOM 树、CSSOM 树 → 渲染树。
- 执行 JS,可能发起 AJAX 请求。
- 页面渲染到屏幕。
9、什么是重定向?重定向与请求转发的区别?
- 重定向(Redirect):
- 服务器返回
3xx,告诉浏览器去新地址。 - 二次请求,地址栏改变。
- 服务器返回
- 请求转发(Forward,服务端内部行为):
- Web 服务器内部转发到另一个资源。
- 一次请求,地址栏不变。
10、GET 与 POST 有什么区别?
1. 语义(核心区别)
- GET:获取资源
- 语义上用于“查询 / 读取”资源,不会修改服务器状态。
- 要求是幂等(多次请求结果一样)和安全(不会改变数据)。
- POST:提交资源
- 语义上用于“新增 / 修改”资源,会对服务器状态造成影响。
- 通常非幂等(多次提交会重复写入数据)。
👉 面试回答点:
HTTP 语义层面,GET 与 POST 的区别远大于“参数放在 URL 还是 Body”,核心是幂等性与安全性。
2. 参数传递方式
- GET
- 参数拼接在 URL,格式为
?key=value&key2=value2。 - 长度限制:HTTP 协议本身无限制,但 浏览器 / 服务器 / 代理 一般限制在 2KB ~ 8KB。
- 适合少量参数、查询条件。
- 参数拼接在 URL,格式为
- POST
- 参数放在 请求体 (Body),理论上无限制,适合大数据提交。
- 但部分服务器或代理仍会限制 Body 大小(通常在 2MB ~ 50MB)。
👉 总结:GET 传输小数据(查询),POST 传输大数据(表单、文件)。
3. 缓存机制
- GET
- 天生支持缓存:浏览器、CDN、代理服务器可缓存 GET 请求结果。
- 结合 Etag、Last-Modified、Cache-Control 等头部,减少重复请求。
- POST
- 默认不缓存,每次都会提交到服务器。
- 可以强行配置缓存(但很少这样做)。
👉 考点:为什么搜索接口一般用 GET?——为了利用浏览器 / CDN 缓存,提高性能。
4. 安全性
- GET
- 参数暴露在 URL,可能被浏览器历史记录、日志、书签记录。
- 不适合传输敏感信息(密码、token)。
- POST
- 参数在请求体里,不会出现在 URL,但仍然可能被抓包工具获取。
- 只是安全性略好,并不是绝对安全。
- 真正安全要依赖 HTTPS 加密传输。
👉 面试时要强调:GET 和 POST 安全性本质上没有区别,安全取决于 HTTPS,而不是请求方法。
5. 性能与 TCP 层面
- TCP 层面:
- GET 与 POST 底层都是 TCP,没有性能差异。
- 区别只在于 请求格式 和 浏览器处理。
- 性能差异的根源:
- GET 请求更容易被缓存,性能更高。
- POST 请求每次都要到服务器处理,性能稍差。
👉 面试陷阱:有人说“POST 会比 GET 多一次 TCP 握手”其实是 误解。
- 事实是:HTTP/1.1 默认长连接,不会重复握手。
6. 应用场景
- GET
- 查询数据、获取资源(如搜索、文章详情)。
- 可被书签保存,可直接分享 URL。
- POST
- 提交数据(如表单提交、文件上传、支付下单)。
- 需要传输复杂或大量数据。
🔑 面试高频总结回答
面试官常问:“GET 和 POST 有什么区别?” 你可以这样答:
- 语义不同:GET 用于获取资源(幂等、安全),POST 用于提交资源(非幂等)。
- 参数传递不同:GET 参数在 URL,有长度限制;POST 在 Body,适合大数据。
- 缓存机制:GET 默认可缓存,POST 默认不缓存。
- 安全性:GET 参数暴露在 URL,POST 参数在 Body,安全性稍高,但真正安全要靠 HTTPS。
- 性能:底层都是 TCP,无本质性能差异,GET 主要因缓存而更快。
- 应用场景:GET 用于查询,POST 用于提交和修改数据。
11、HTTP vs. HTTPS 有什么区别?
- HTTP:明文传输,不安全。
- HTTPS:HTTP + TLS/SSL,数据加密。
- 区别:
- 端口不同(80 vs 443)。
- HTTPS 需要证书。
- HTTPS 有握手过程,性能略低。
12、HTTPS 的「秘钥交换 + 证书校验」全流程
- 浏览器请求 HTTPS 网站。
- 服务器返回 证书(包含公钥 + 签名)。
- 浏览器验证证书合法性(CA 签发、域名匹配、未过期)。
- 客户端生成 随机对称密钥,用服务器公钥加密,发给服务器。
- 服务器用私钥解密,得到对称密钥。
- 后续通信用 对称加密(AES)。
13、HTTPS(TLS)里都用到了哪些加密算法?
- 对称加密:AES、ChaCha20(数据加密)。
- 非对称加密:RSA、ECC(秘钥交换)。
- 摘要算法:SHA-256(完整性校验)。
- 数字签名:RSA-SHA256 / ECDSA。
14、WebSocket 简介 & 与 HTTP 的核心区别
- WebSocket:全双工通信协议,运行在 TCP 之上。
- 与 HTTP 的区别:
- HTTP 是 请求-响应模式。
- WebSocket 是 双向通信,服务端可主动推送数据。
- 建立时通过 HTTP Upgrade 头,从 HTTP 升级为 WebSocket。
15、WebSocket 的工作过程是什么样的?
- 客户端发起 HTTP 请求,带
Upgrade: websocket。 - 服务器同意,返回 101 Switching Protocols。
- 双方升级为 WebSocket 协议,保持 TCP 长连接。
- 客户端 & 服务端可以互相发送消息(Text/Binary Frame)。
16、SSE(Server-Sent Events)与 WebSocket 有什么区别?
- SSE(服务器推送事件):
- 基于 HTTP 协议。
- 单向:服务器 → 客户端。
- 适合实时数据推送(股票、消息提醒)。
- WebSocket:
- 独立协议。
- 双向通信(客户端 & 服务端都能主动发送)。
- 适合聊天室、在线游戏。
👉 总结:
- SSE:轻量级,单向推送。
- WebSocket:强大,双向通信。
分布式-牛客面经八股
1. 缓存穿透 / 缓存击穿 / 缓存雪崩 — 区别与防护
定义
- 缓存穿透:请求查询的 key 在缓存未命中且数据库也不存在(或是恶意请求大量不存在 key),导致大量请求直接打到 DB。
- 缓存击穿(又称 cache breakdown):某个热点 key 的缓存过期或被淘汰,短时间内大量并发请求同时去读 DB,造成 DB 峰值压力。
- 缓存雪崩:缓存层在短时间内大量 key 同时失效(例如同一 TTL 或重启导致),整体流量穿透到 DB,造成服务雪崩。
防护策略(实战)
- 穿透:
- 使用 布隆过滤器 预过滤不存在的 key(内存小、允许一定误报),把合法 key 的集合放入布隆过滤器。
- 对不存在的结果做 负缓存(empty cache):把空结果也缓存,但 TTL 较短(例如 30s~5min),避免无限缓存错误数据。注意 TTL 应短且带随机抖动避免同时过期。
- 击穿:
- 使用 互斥锁 / singleflight:一个请求去 DB 构建缓存,其他请求等待或返回旧值;例如 Redis 的
SETNX+ value-token + Lua 验证释放锁。 - 提前重建 / 热点预热:对已知热点提前刷新或延长 TTL。
- 使用 永不过期缓存 + 后台刷新(主动刷新策略)。
- 使用 互斥锁 / singleflight:一个请求去 DB 构建缓存,其他请求等待或返回旧值;例如 Redis 的
- 雪崩:
- 给 TTL 加 随机抖动(使 key 不会同一时刻失效)。
- 限制缓存穿透到 DB 的 QPS(熔断/降级、限流)。
- 多级缓存(本地 + 分布式)与冷备(备用 DB 副本、读副本)。
- Cache warming(重启后先行预热重要 key)。
- 穿透:
实现要点 / 伪代码
负缓存示例(伪):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18val = redis.get(key)
if val != null:
if val == "__EMPTY__":
return 404
return val
// miss
lock = redis.set("lock:"+key, uuid, NX, PX, 30000)
if lock:
val = db.query(key)
if val:
redis.set(key, val, TTL)
else:
redis.set(key, "__EMPTY__", shortTTL)
redis.del("lock:"+key)
return val
else:
sleep(50ms) // 或者等待 singleflight 返回
retry get from cache
常见面试追问:布隆误报率如何计算?NX+PX 的锁为什么还要校验 value?为什么负缓存 TTL 要短?singleflight 的实现细节。
你这几个问题都是高频追问,答得要够深入,面试官才会认可。下面我分点逐一展开:
1. 布隆过滤器的误报率计算
原理
布隆过滤器由一个 长度为 m 的 bit 数组和 k 个哈希函数组成。
- 插入一个元素时,计算 k 次 hash,将结果位置置为 1。
- 查询一个元素时,若有任意一个位置为 0,则一定不存在;若全部为 1,则可能存在(误报)。
误报率公式
插入 n 个元素时,某个 bit 位保持为 0 的概率:
$$
[
\left(1 - \frac{1}{m}\right)^{kn} \approx e^{-\frac{kn}{m}}
]
$$某个 bit 位为 1 的概率:
$$
[
1 - e^{-\frac{kn}{m}}
]
$$查询时,k 个 hash 都命中的概率(即误报概率):
$$
[
P_{false} = \left(1 - e^{-\frac{kn}{m}}\right)^k
]
$$
最佳 k 值(哈希函数个数)
为了降低误报率,k 要适配:
$$
[
k = \frac{m}{n} \ln 2
]
$$
关键点总结(面试答法)
误报率 ≈
$$
(\left(1 - e^{-\frac{kn}{m}}\right)^k)
$$哈希函数数量
$$
k ≈ (m/n) * ln 2
$$误报率随 m 增大、k 合理时下降;但不会为 0。
2. Redis 分布式锁 NX+PX 为什么还要校验 value?
问题背景
Redis 分布式锁常见写法:
1 | SET key value NX PX ttl |
NX:只在 key 不存在时设置,避免重复获取。PX ttl:过期时间,避免死锁。
为什么还要校验 value?
- 多客户端竞争锁时,可能会出现 锁被误删 的问题:
- 客户端 A 拿到锁(key=lock,value=uuidA,ttl=5s)。
- A 执行时间过长,锁过期自动释放。
- 客户端 B 拿到锁(key=lock,value=uuidB)。
- A 任务结束,执行
DEL lock,结果把 B 的锁删掉了。
这样会导致 并发安全问题。
解决方式
删除时必须 先比对 value 是否属于自己:
1 | if redis.call("get", KEYS[1]) == ARGV[1] then |
👉 总结一句话:校验 value 的原因是避免删除其他客户端的锁。
3. 负缓存(缓存空值)TTL 为什么要短?
场景
- 缓存穿透时(大量查询不存在的数据),常用做法是 缓存空值,避免频繁打到数据库。
- 但空值可能未来会变成真实存在的数据(例如用户刚注册)。
为什么 TTL 要短?
- 如果负缓存 TTL 太长,新插入的数据会长时间无法被访问(缓存一直返回空)。
- TTL 短可以在一段时间后自动过期,让新数据有机会被查询到。
取舍
- 短 TTL:避免数据延迟太长。
- 太短会让缓存命中率下降。
- 一般设置 几秒到几十秒(依业务场景权衡)。
👉 一句话总结:负缓存 TTL 短,是为了兼顾抗穿透和数据及时性。
4. singleflight 的实现细节(Go 中的典型方案)
背景
- 常见于缓存击穿问题:同一时间大量请求打到 DB。
- singleflight 让同一个 key 的请求,只执行一次函数,其它请求等待结果。
Go 官方实现(sync/singleflight)
核心结构:
1 | type Group struct { |
执行流程
- 请求到来时,先加锁,检查 key 是否已有 call:
- 如果没有:新建 call,
wg.Add(1),异步执行 fn。 - 如果有:说明已有请求在跑,当前请求等待
wg.Wait()。
- 如果没有:新建 call,
- fn 执行完成,存储结果
val, err,wg.Done()唤醒等待的请求。 - 所有等待请求拿到同一个结果。
伪代码
1 | func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) { |
特点
- 保证同一 key 只执行一次,减少 DB 压力。
- 其他请求等待结果,避免击穿。
- 等待线程很多时可能放大延迟,但比打 DB 好。
✅ 面试答法总结:
- 布隆误报率:公式 + 最佳 k 值。
- NX+PX 校验 value:避免误删他人锁。
- 负缓存 TTL 短:兼顾抗穿透和数据实时性。
- singleflight 实现:map+waitgroup,核心是请求合并。
2. Redis 与数据库保持双写一致性的常见方案(权衡与实现)
- 几类常见模式
- Cache-Aside(旁路缓存)(最常见)
- 应用先读缓存(miss 去 DB 并回填缓存);写操作先写 DB,再删除/更新缓存(delete-then-write 或 write-then-delete 都有争议)。
- Write-Through / Read-Through
- Write-through:应用写缓存,由缓存层负责同步写 DB(同步或异步)。优点:简单的一致性模型;缺点:写延迟高或缓存写失败复杂。
- Read-through:缓存 miss 自动去 DB 并回填(由 cache 框架处理)。
- Write-Behind(异步回写)
- 写入缓存并异步写入 DB(高吞吐但风险:崩溃可能丢数据)。
- 消息队列 + Eventual Consistency(推荐在分布式系统中)
- 写 DB -> 产生事件(消息) -> 异步消费者更新/失效缓存。或写 DB 后删除 cache,再通过队列异步再次确认/回写。
- Cache-Aside(旁路缓存)(最常见)
- 常见一致性问题(race 条件)
- 写 DB 后竞争:A 写 DB 并删除缓存;B 并发读 DB 后写回旧值到缓存(导致缓存旧数据)。解决方法:
- 操作顺序:常见做法是
DB write->delete cache,但需要加锁或使用版本号/时间戳来避免竞态。 - 利用消息队列:DB 写完成后发消息,消费者串行/有序地更新缓存或删除;保证缓存更新顺序。
- 带版本号的数据:在缓存中存入版本号或时间戳,写入时比较版本仅写入更新的值。
- 分布式锁:在更新缓存/DB 时获得锁,防止并发回写旧数据(但影响并发性能)。
- 操作顺序:常见做法是
- 写 DB 后竞争:A 写 DB 并删除缓存;B 并发读 DB 后写回旧值到缓存(导致缓存旧数据)。解决方法:
- 推荐实践
- 优先采用 Cache-Aside + 消息队列:对写操作先写 DB,产生日志/事件,缓存由消费者异步处理(保证最终一致)。读路径仍是先缓存。
- 对强一致性要求极高的场景考虑 数据库为主、缓存为辅(或使用 DB 的二级索引、Materialized View)。
- 使用 幂等、重试与版本控制 来降低竞态带来的不一致风险。
3. 布隆过滤器(Bloom Filter)原理、公式、变体与实战
基本原理
- 使用一段位数组(m 位)和 k 个独立哈希函数。添加元素时对 k 个哈希位设为 1;查询时检查对应的 k 个位是否都为 1。如果有位为 0,则肯定不存在(无假阴性)。若全部为 1,说明“可能存在”(存在假阳性)。
关键公式
在插入 n 个元素,使用 m 位和 k 个哈希下,假阳性率近似为:
$$
p \approx \left(1 - e^{-kn/m}\right)^k
$$最优 k(使 p 最小)约等于
$$
(k = \frac{m}{n} \ln 2)
$$
变体
- Counting Bloom Filter:计数器代替位数组,支持删除(通过减计数),但内存大。
- Scalable Bloom Filter:当元素增长时,动态增加子过滤器来控制误报率。
- Partitioned Bloom / Blocked Bloom:减少缓存行冲突、提高并发性能。
实现与应用
- 常用于:缓存穿透防护、数据库去重、web 去重、分布式系统快速判断存在性。
- 实现注意:哈希函数必须分布均匀、独立(可用双哈希技术衍生多个哈希)。
示例(伪)
1
2
3
4
5
6
7
8
9
10
11
12m = 10_000_000
k = 7
bitarray = [0]*m
def add(x):
for i in range(k):
idx = hash_i(x, i) % m
bitarray[idx] = 1
def might_contain(x):
for i in range(k):
if bitarray[hash_i(x,i)%m] == 0:
return False
return True面试追问:如何选择 m,k?怎样在分布式环境共享布隆过滤器(位图分片、Redis bitmap)?
1. 如何选择 m(位数组大小)和 k(哈希函数个数)?
目标
已知:
- n = 预计插入的元素数
- p = 允许的误报率
求:
- m(bit 数组长度)
- k(哈希函数个数)
公式推导
布隆过滤器误报率公式:
$$
[
p \approx \left(1 - e^{-\frac{kn}{m}}\right)^k
]
$$
最优哈希函数个数(推导结论):
$$
[
k = \frac{m}{n} \ln 2
]
$$
位数组大小:
$$
[
m = -\frac{n \ln p}{(\ln 2)^2}
]
$$
代入后,误报率约等于:
$$
[
p = \left(0.6185\right)^{\frac{m}{n}}
]
$$
举例
比如:
- 预计存 1000 万个 key(n=10^7)
- 希望误报率 p=1%
计算:
$$
[
m = - \frac{10^7 \times \ln(0.01)}{(\ln 2)^2} \approx 9.6 \times 10^7 \text{ bit} \approx 12 MB
]
$$
$$
[
k = \frac{m}{n} \ln 2 \approx 7
]
$$
👉 所以要配置一个 12MB 的位数组,7 个 hash 函数,就能在千万级数据下保证 1% 的误报率。
2. 分布式环境如何共享布隆过滤器?
单机内存版布隆过滤器没法直接支撑分布式系统,常见有两种思路:
方案 A:位图分片(分布式切片存储)
- 将布隆过滤器的位数组 拆分成多个分片,存放在不同节点。
- 插入/查询时,用 hash 定位到具体分片,然后设置/检查位。
- 类似 一致性哈希 的思路,每个节点存自己的一部分。
优点:
- 横向扩展,突破单机内存限制。
- 节点可以独立存储,减少单点瓶颈。
缺点:
- 跨节点网络开销大(需要路由)。
- 容错要处理(某个节点挂掉可能丢失一部分位信息)。
方案 B:共享存储(Redis bitmap 最常见)
把布隆过滤器的 bit 数组直接放在 Redis,利用 Redis 的 bitmap 操作。
插入:
1
SETBIT bloom key offset 1
查询:
1
GETBIT bloom key offset
Redis 本身就是分布式的,可以通过 Cluster/分片 方式存储超大 bit 数组。
优点:
- 使用 Redis 内建的持久化和高可用,省去自己管理分片。
- 简单易用,社区有现成实现(如 Redisson 提供布隆过滤器)。
缺点:
- Redis 成为性能瓶颈(高并发下 bitmap 操作频繁)。
- 网络 IO 增加延迟(相比本地内存)。
其他方案
- RocksDB + bitmap:适合本地持久化布隆。
- Kafka Streams / Flink:流式场景下,用布隆做过滤,分片交给框架本身的 state 管理。
- Counting Bloom Filter:用计数器代替 bit,可支持删除(但占用更多空间)。
🔑 面试答法总结
- 选择 m,k:
- m = (-n \ln p / (\ln 2)^2)
- k = (m/n) ln 2
- 共享布隆过滤器:
- 位图分片(类似一致性哈希,节点分片存储)。
- Redis bitmap(集中式存储,利用 Redis 的 SETBIT/GETBIT)。
4. 消息队列如何保证顺序消费?(策略与代价)
- 保证顺序的基本思路
- 顺序消费需要对一组相关消息在单一顺序流(partition/queue)中处理:把同 key 的消息映射到同一个分区/队列,并由该 partition 的单一消费者或单线程序列化消费。
- 常见实现
- Kafka:按
key分区,单个 partition 内消息有序;由同一 consumer instance 顺序消费(注意重平衡时可能短暂中断)。 - RabbitMQ / 传统队列:把相关消息放在同一队列,由单一消费者顺序消费(但单一消费者可能成为瓶颈)。
- SQS FIFO:提供
MessageGroupId保证组内顺序。
- Kafka:按
- 要点与陷阱
- 顺序与吞吐量冲突:单 partition/单消费者限制吞吐量;为兼顾吞吐需要分 key 粒度切分。
- 消费失败与重试:若失败导致重复消费或延迟,会影响全局顺序(需要 careful 设计,如顺序重试队列或把失败消息单独挪出)。
- 消费者水平扩展时要保持 key 到 partition 的映射稳定(避免重分区导致不必要的重新排序)。
- 实践建议
- 分配合适的 partition 数量与 key 设计(热点 key 可能成为瓶颈)。
- 对需要严格全局顺序的场景(较少)考虑单线程处理或全局序列号系统。
- 使用幂等消费逻辑与事务/offset 管理保证在重试时仍能正确处理。
5. 消息队列如何保证消息不丢?(持久化、复制、ACK)
- 关键机制
- 持久化(durable):消息写入磁盘(或持久日志),即使 Broker 重启消息仍在。
- 副本/复制:将消息复制到多个 broker 节点(例如 Kafka 的 ISR),至少写入多数副本才算成功(降低单点丢失)。
- 确认机制(ACK):消费者处理后返回 ACK;Broker 在确认后才删除消息(或提交 offset)。
- 重试与死信队列(DLQ):失败的消息重试若超过阈值发往 DLQ。
- 事务/幂等生产者:保证生产端的重复发送不会丢或重复计数(Kafka 的幂等 producer + transactional)。
- 系统参数(以 Kafka 为例)
acks=all(生产者要求 leader 等待 ISR 中多数副本确认)min.insync.replicas(要求写入的最小同步副本数)replication.factor(副本数)
- 设计权衡
- 更高的持久性 → 写延迟上升、吞吐下降。
- 同步复制 vs 异步复制的选择:异步快但有丢数据风险。
- 实战建议
- 对关键数据启用同步复制、持久化、且配置合适的
min.insync.replicas。 - 使用事务/幂等保证端到端一致性(当需要 exactly-once 或低丢失)。
- 对关键数据启用同步复制、持久化、且配置合适的
6. 消息队列如何保证不重复消费?(幂等、去重、事务)
常见目标与模式
- 通常消息传递模型是 at-least-once(可能重复),需要消费者保证幂等或使用外部去重。
实现方法
- 幂等处理:业务操作本身设计为幂等(例如使用 PUT 替代增量操作,或根据消息 id 做一次性处理)。
- 去重表(Dedup store):消费者在处理消息前检查消息 ID(例如
msgId存入 Redis/DB 的集合/表),若已存在则跳过。需要 TTL 或清理策略。 - 事务性写入 + 提交 offset 的原子性(exactly-once):
- Kafka 提供事务 API:消费者读取、处理并把结果写回 Kafka,再原子提交 offset(实现端到端 exactly-once 在一定场景下)。
- Outbox Pattern:在 DB 事务中把消息写入 outbox 表,事务提交后异步将 outbox 的消息发到消息队列;消费者消费幂等写入到 DB。
复杂性与代价
- 去重存储是状态式,可能成为瓶颈;需要高性能的去重存储(Redis、Cassandra)。
- 完全 exactly-once 跨服务极难,通常用幂等+去重+事务组合来实现近似 exactly-once。
示例(伪)
1
2
3
4
5
6if redis.sismember("processed", msg.id):
ack and return
process business
record = db.write(...)
redis.sadd("processed", msg.id); set TTL
ack
7. 消息队列:Push(推)与 Pull(拉)使用场景对比
- Push(Broker 推送到 Consumer)
- 优点:低延迟、实现简单(事件驱动),适用于消费端能快速处理或有背压机制的场景;常见于 RabbitMQ(broker push 模式)、webhooks。
- 缺点:消费者容易被突发流量压垮(需要流量控制、限速、QoS)。
- 场景:实时通知、webhook、低延迟实时事件。
- Pull(Consumer 拉取消息)
- 优点:消费者控制消费速率(自然背压),易于扩展消费者并发;适合高吞吐、批量处理场景。常见于 Kafka、SQS。
- 缺点:拉取轮询或长轮询会增加实现复杂度、延迟稍高。
- 场景:日志收集、大数据批量处理、消费者需要控制批量大小或处理速度(例如按窗口消费)。
- 混合/折中
- 长轮询(SQS long polling)或 push + client-side window 控制提供折中方案。
- Broker 可以根据 consumer 的能力调整推送速率(Flow control / QoS)。
8. 分布式锁:原理与常见实现
核心目标:在分布式环境下对共享资源做互斥控制(同一时刻只有一个客户端持有锁)。
常见实现方式
- Redis + SET NX PX:
SET key value NX PX ttl:原子取得锁并设置超时,释放锁需检查 value(防止误删别人的锁)。- 释放锁用 Lua 脚本保证原子性(先比较 value,再删除)。
- RedLock(多 Redis 实例交叉锁定):
- 在多个独立 Redis 节点上尝试加锁,过半成功则认为获得锁;争议:理论上在网络分区下可能不安全,需谨慎使用。
- Zookeeper:
- 使用临时顺序节点(ephemeral sequential)实现锁,节点删除或会话断开时自动释放锁;ZK 提供强一致性(推荐用于强一致性场景)。
- etcd / Consul:
- 基于 Lease + Compare-And-Swap(CAS)实现,且有自动延续 lease 的机制。
- 数据库行锁(SELECT … FOR UPDATE / update with condition):
- 简单但可能影响 DB 性能,适用于不高并发或已有 DB 保证版场景。
- Redis + SET NX PX:
注意点
- 锁超时要合理,避免持有锁的客户端长时间阻塞(但若过短又可能被误抢)。
- 锁的可重入、可续租(renew)、可释放性设计。
- 要保证释放锁的操作是原子且只释放自己的锁(比较 value)。
示例:Redis 释放 Lua(伪)
1
2
3
4
5if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end面试追问:RedLock 的争议是什么?为什么 ZK/etcd 更安全(因为它们使用强一致的 consensus)?
1. RedLock 的背景
RedLock 是 Redis 作者 antirez 提出的分布式锁算法:
- 在 N 个 Redis 节点上尝试获取锁(例如 5 个节点)。
- 至少在多数节点(N/2+1)成功才算加锁成功。
- 通过设置过期时间(TTL)防止死锁。
- 用于容错,避免单机 Redis 挂掉导致锁失效。
2. RedLock 的争议点
虽然 RedLock 在 Redis 场景下很火,但它并不被业界普遍认为是严格安全的分布式锁,主要争议:
(1) 基于过期时间的安全性不足
- RedLock 依赖锁的 TTL,防止持有者宕机导致死锁。
- 但如果 GC 停顿 / 网络分区 / 客户端挂起,锁可能在 TTL 到期后被其他进程获取。
- 原持有者恢复后,可能“误以为自己还持有锁”,导致两个客户端同时认为自己有锁 → 安全性问题。
(2) Redis 本身是 AP 系统(高可用优先)
- Redis 集群主从复制是 异步 的。
- 当写入锁 key 后,主节点宕机、从节点切换为主节点时,可能丢失锁记录(数据还没同步到从节点)。
- 导致锁丢失 → 另一个客户端能重新加锁。
(3) 复杂环境下正确性无法保证
- Martin Kleppmann(分布式系统专家,《Designing Data-Intensive Applications》作者)在博客里批评过 RedLock:
- RedLock 没有给出严格的形式化证明,不能保证在网络分区、时钟漂移等场景下一致性。
- 认为 RedLock 在需要“强安全性”的业务(例如金融转账、支付)里不合适。
3. 为什么 Zookeeper / etcd 更安全?
(1) 基于强一致性共识协议(Consensus)
- Zookeeper:基于 ZAB(Zookeeper Atomic Broadcast) 协议,本质类似 Paxos。
- etcd:基于 Raft 共识算法。
- 这类系统保证:
- 写入数据必须经过多数派确认。
- 所有节点对锁的状态有强一致性保证。
- 不会出现“一个客户端认为有锁,另一个客户端也认为有锁”的情况。
(2) 锁释放/会话管理更可靠
- ZK/etcd 支持 临时节点(Ephemeral Node):
- 客户端与服务端保持会话心跳。
- 一旦客户端宕机或网络断开,临时节点会自动删除,锁自动释放。
- 这比 Redis 的 TTL + value check 更强健,避免了 GC 停顿、长延迟导致的锁误删/锁漂移问题。
(3) 阻塞/顺序保证
- Zookeeper 的 有序节点(Sequential Node) + Watch 机制,可以实现 公平锁(按顺序排队获取锁)。
- Redis 分布式锁一般只能实现“谁抢到就是谁的”,无法实现严格的排队公平性。
4. 总结面试答法
如果面试官问:
“RedLock 争议在哪里?为什么用 ZK/etcd 更安全?”
你可以这么答:
RedLock 的核心问题在于它依赖 TTL 和 Redis 的异步复制,在 GC 停顿、网络分区或主从切换时,可能导致多个客户端同时认为自己持有锁;而 Redis 本身更偏向 AP,不能保证强一致性。
相比之下,Zookeeper 和 etcd 基于强一致性共识协议(ZAB / Raft),锁的状态必须经过多数派确认,并且利用临时节点和会话机制确保锁自动释放,因此不会出现 RedLock 的安全性漏洞,更适合需要严格分布式一致性的场景。
✅ 简化记忆版:
- RedLock 争议:基于过期时间,不抗 GC/网络分区/主从切换;Redis 异步复制可能丢锁。
- ZK/etcd 优势:强一致(共识协议)、临时节点(会话自动释放)、顺序保证(公平锁)。
9. 分布式事务与常见解决方案
- 问题定义:跨多个服务 / 数据源的事务一致性(ACID)难以直接用单体数据库事务保证。
- 常见方案
- 2PC(Two-Phase Commit):
- 协调者先询问参与者是否准备提交(prepare),若都准备则提交(commit);问题:阻塞、实现复杂、对性能影响大。
- 3PC(Three-Phase Commit):在 2PC 基础上缓解阻塞,但复杂性更高,实际少用。
- Saga 模式(推荐):
- 把一个长事务拆成多个本地事务,各自提交并通过补偿事务回滚(两类实现:choreography(事件驱动)或 orchestration(集中编排器))。
- 优点:无全局锁、易扩展;缺点:实现补偿逻辑复杂、最终一致性而非强一致。
- TCC(Try-Confirm-Cancel):
- 三阶段:try(资源预留),confirm(实际提交),cancel(回滚)。适合需要明确资源预占的场景。
- Outbox Pattern + Message Relay / CDC:
- 在本地 DB 事务中写入业务数据 + outbox 表(原子),事务提交后异步把 outbox 发送给消息总线,其他服务消费。避免消息丢失与跨服务事务问题。
- 基于事件驱动的最终一致性:事件来源(event sourcing)+消费端对事件进行处理。
- 2PC(Two-Phase Commit):
- 选择标准
- 强一致性 vs 可用性权衡:业务是否能容忍最终一致性?
- 复杂度和运维成本:2PC 很难扩展到微服务环境,Saga/Outbox 更现实。
- 面试追问:如何保证 Saga 的补偿能成功?如何处理补偿失败(人工干预/补偿队列)?
10. CAP 理论(与扩展 PACELC)
- CAP 三要素
- Consistency(一致性):所有节点在同一时间看到相同数据(读到最新写入)。
- Availability(可用性):每个请求都能在有限时间内得到成功或失败响应(系统持续可用)。
- Partition tolerance(分区容忍性):系统在出现网络分区(分节点间通信失败)下仍可继续运行。
- 定理结论:在网络分区发生时,分布式系统只能在一致性(C)和可用性(A)间做权衡(只能保证其中之一 + partition)。
- 现实系统的取舍
- CP 系统(优先一致性):例如 HBase 在分区期选择不可用以保证一致性。
- AP 系统(优先可用性):例如 Cassandra 在分区期仍提供服务,但数据可能最终一致。
- PACELC 扩展
- PACELC:在 Partition(P)发生时在 A 与 C 之间取舍;Else(E)在正常情况下在 Latency(L)和 Consistency(C)之间取舍。
- 面试要点
- 不要直接说某系统“遵循 CAP”,而是说明在何种故障场景选择了哪种折中。
- 系统常采用复制策略、Quorum 写/读策略来在一致性/可用性间做灵活配置(例如 quorum 写多数策略)。
11. 数据库连接池:是什么、为何需要、关键配置项
- 概念:在应用中维护一组可复用的数据库连接,避免频繁创建/销毁连接的开销。
- 为什么需要
- 建立数据库连接开销大(TCP 握手、认证、会话建立)。
- 限制并发连接数,防止 DB 被过多连接冲垮。
- 提高性能(连接复用、预热好处),并可缓存 PreparedStatements。
- 重要配置
maxPoolSize(最大连接数)、minIdle、maxIdle、connectionTimeout、idleTimeout、validationQuery、leakDetectionThreshold。testOnBorrow/testOnReturn(是否在借出/归还时检测连接健康)。
- 实现注意
- 连接泄露监测:若开发者忘记关闭连接需能检测并回收。
- 事务边界:确保在事务结束时释放连接(尤其在框架/中间件层)。
- Pool 与 DB 的匹配:maxPoolSize 不应超过 DB 能支持的最大并发连接数。
- 常见连接池实现:HikariCP(推荐,性能优)、Tomcat JDBC pool、Druid、c3p0。
- 面试追问:为什么
maxPoolSize不能设太大?如何排查连接泄漏?如何检测连接是否活着(validation)?
12. 一致性哈希(Consistent Hashing)详解
- 问题背景:节点增删时,如何尽量减少 key 重映射(降低缓存失效带来的重建压力)。
- 基本机制
- 把整个哈希空间想成环(0..2^32-1),每个节点映射到环上的若干位置(虚拟节点 vnodes)。Key 的 hash 决定它在环上的位置,向顺时针找到第一个节点作为该 key 的负责节点。
- 优点
- 节点加入/删除只影响相邻片段的 key(只需迁移少部分 key)。
- 使用虚拟节点能均衡负载(一个真实节点挂多个 vnode)。
- 实现要点
- 选择稳定且分布均匀的哈希函数(例如 MurmurHash)。
- 使用足够多的虚拟节点根据节点权重分配(权重高的节点分配更多 vnode)。
- 支持副本(复制到环上连续的下 k 个 vnode)保证容错。
- 应用场景
- 缓存分片(Memcached/Ketama)、分布式存储/查找(DHT)。
- 面试追问:如何处理节点权重?为什么需要虚拟节点?如何在一致性哈希上做数据迁移?
13. 负载均衡(LB)
- 分类
- DNS 负载均衡:把域名解析到多个 IP(粗粒度,受 DNS 缓存影响)。
- L4(传输层)负载均衡:基于 IP/端口(如 LVS、Nginx 的 stream 模式)。
- L7(应用层)负载均衡:基于 HTTP 信息(URI、Header、Cookie)做路由(如 Nginx、Envoy、Traefik)。
- 全局负载均衡(GSLB):跨区域/数据中心调度。
- 常见调度算法
- 轮询(Round Robin)、加权轮询、最少连接、源地址哈希(IP hash)、一致性哈希、响应时间加权。
- 功能
- 健康检查(主动 probe、被动探测)、会话保持(sticky session)、SSL 终止、速率限制、熔断、路由规则。
- 实现细节
- 健康检查频率、超时和失败阈值设定直接影响可用性和故障转移速度。
- 粘性会话:通过 cookie 或源 IP 维持会话,但影响水平扩展和容错。
- 与自动扩缩结合:LB 应感知实例的加入/移除(服务发现)。
- 面试点:L4 与 L7 的区别、何时使用粘性会话、负载均衡的瓶颈与调优参数(连接池、keepalive)。
14. 限流算法(详述:Token Bucket, Leaky Bucket, Fixed Window, Sliding Window)
- Fixed Window(固定窗口计数)
- 将时间划分到固定窗口(例如每分钟),用计数器统计请求数。实现简单但边界窗口会导致突发流量(例如窗口末尾+窗口开始)。
- Sliding Window Log(滑动窗口日志)
- 记录每个请求时间戳,精确但内存消耗大。
- Sliding Window Counter(滑动计数器)
- 把时间分成多个小桶,近似滑动窗口精度与性能的折中。
- Token Bucket(令牌桶)(常用)
- 系统以固定速率向桶中放令牌,消费请求取令牌;允许短时间突发(桶有存量)。
- Leaky Bucket(漏桶)
- 请求进桶,按恒定速率漏出消费;更偏向平滑输出,抑制突发。
- 分布式实现
- Redis + 原子脚本(Lua)实现计数与令牌发放,或使用内置限流中间件(Envoy rate limit)。
- 要保证原子性(避免 race),通常使用 Lua 脚本在 Redis 上实现令牌桶。
- 示例 Redis Lua(令牌桶思路,伪)
- 检查并更新时间戳与令牌计数,返回允许/拒绝。
- 选择建议
- 需要短突发能力用 Token Bucket;要求严格平滑输出用 Leaky Bucket;简单限速可用 Fixed Window。
- 面试追问:如何在分布式部署下实现全局限流?(使用 centralized Redis、或 local token + periodic refill)
15. 分布式 ID(生成方案:UUID / Snowflake / DB sequence / Redis)
- 常用方案对比
- UUID:全局唯一,冲突概率极低,但长度大、不可顺序排序(影响索引)。
- Snowflake(Twitter):时间戳 + dataCenterId + workerId + sequence —— 有序(按时间近似排序),高吞吐,常见实现。
- 优点:有序、短小、可解码(包含时间),高性能。
- 风险:时间回退会导致 ID 冲突,机器 ID 管理困难,sequence 溢出需要等待下一毫秒。
- 数据库 Sequence:简单、强一致(如果用单 DB),但单点与性能受限。
- Redis INCR:高性能、分布式,但跨实例同步与持久性需注意(及分区问题)。
- KSUID / ULID / Sonyflake:支持排序与更长时间范围的变种。
- Snowflake 典型位分配(示例)
- 1 bit unused | 41 bits timestamp | 10 bits machine id | 12 bits sequence
- 实践注意
- 时间回退问题:使用 NTP,要对时钟回退做防护(拒绝、等待或使用逻辑时钟)。
- 机器 ID 分配:静态配置或通过注册中心分配;需避免冲突。
- 高可用:可使用多个发号服务并保证不同范围/前缀来避免冲突。
- 面试追问:如何解决 Snowflake 在时钟回退情况下的冲突?如何保证全局唯一与高性能并行发号?
一、Snowflake 在时钟回退(clock rollback / clock drift)下的常见风险
核心风险是:如果节点本地时钟回退(比如 NTP 同步、虚拟机迁移、系统时间被改、短暂的时钟回拨),生成的 timestamp 可能小于之前生成的 lastTimestamp,导致:
- 生成重复 ID(如果 timestamp 部分变小而 sequence 又从 0 开始),或
- 生成“时间倒序”的 ID,破坏单调性,影响有序性依赖的系统(日志、排序、DB 分区键等)。
二、常用的解决策略(按从简单到稳健排序)
1) 最简单:拒绝/等待(Recommended first-line)
- 实现:检测到
now < lastTimestamp时,阻塞并等待直到now >= lastTimestamp(spin/sleep 少量毫秒)。 - 何时用:回退幅度很小(几十毫秒 ~ 几百毫秒)。
- 缺点:如果回退较大,会导致服务阻塞;不能在低可用场景无限等待。
伪码
1 | now := currentMillis() |
2) 使用备用 sequence 空间(短期“虚拟时间”)
- 思路:当
now < lastTimestamp且差值小于阈值时,继续使用 lastTimestamp,但把 sequence 推进到一个高位段(使在同一 timestamp 下仍产生唯一 id)。 - 要点:sequence 位要足够(例如 12 位),但这种做法在 long rollback 情况下会耗尽 sequence 导致失败。
- 风险:破坏严格的时间语义(ID 看起来像是同一毫秒生成),但仍保证唯一。
伪码
1 | if now < lastTimestamp { |
3) 用逻辑时钟 / Hybrid Logical Clock (HLC)
- 思路:维护一个
logicalCounter,当物理时间回退时用lastTimestamp和logicalCounter++作为时间拓展。HLC 能保证单调的“时间戳”且兼顾部分真实时间。 - 优点:不必长时间阻塞,能在分布式系统中保持因果单调性。
- 代价:需要把 timestamp 的低位/额外位划给 logical counter(减少可用时间位或 sequence 位)。
伪码(核心)
1 | if physicalNow > lastTimestamp: |
4) 持久化 lastTimestamp(重启/迁移安全)
- 将
lastTimestamp(或最近分配的 max id)写到本地磁盘(或 etcd)在进程启动时读取; - 启动时保证新的
lastTimestamp> persisted 值(若物理时钟后退导致当前时间小于 persisted 值,可选择等待或使用 persisted+1 作为基准)。 - 优点:避免重启后重复分配旧 ID。
- 缺点:增加 IO;写入策略要保证性能(可异步定期 flush,但要兼顾安全)。
5) 严格策略:主控/仲裁或切换到强一致时钟来源
- 利用外部服务(NTP 高精度 / GPS / 时间服务器)或用共识系统(etcd/zookeeper)来校验时间或分配时间段。
- 也可把时间戳分配成 “逻辑时间 + nodeRange”,将时间分配的责任集中化(牺牲一点可用性换强一致性)。
6) 退避到备用发号方案(failover)
- 当检测到严重回退(超过阈值)时,切换到备用发号器:
- 从数据库获取一个批次/段(HiLo),或
- 请求 central allocator(有状态)给出一段 ID_range。
- 好处:稳妥但依赖中心化服务(可做主备)。
三、如何保证全局唯一且高性能并行发号(设计模式与实作建议)
目标:在全球分布、多实例场景下,保证唯一性、低延迟、高吞吐、并尽量保留可排序性。
1) Snowflake 本身的可扩展性点
- 每个实例(节点)只需有唯一的 workerId(和 datacenterId)。
- 本地只需维护
lastTimestamp和sequence,不需要中心协调 -> 本地化、低延迟、高并发(每 ms 用 sequence 分配)。 - 扩容:增加 workerId 数目(需要更多位),或增加数据中心标识位。
要点:workerId 必须严格唯一且稳定(见下文如何分配)。
2) 保证 workerId 唯一的常用方案
- 静态配置:部署时人为分配(小规模)——简单但运维复杂。
- 服务注册中心:用 etcd / Zookeeper / consul 在启动时获取唯一 ID(基于租约/序号)。常见做法:注册并获得自增序号或 ephemeral node 的序号。
- 云环境元数据:使用实例 ID / MAC / 私有 IP hash 但要避免冲突并处理重启后的重复问题(需要加 lease)。
- 持久化绑定:把 workerId 与机器或容器绑定并持久化,避免重启/迁移造成重复。
推荐:用 etcd/zookeeper 做带租约的分配(启动登记获得唯一 id,断开后租约释放可重新分配),这样可以自动避免长期重复。
3) 提升并发能力的方法(水平扩展与局部优化)
- 增加并行节点数(更多 workerId),每节点本地速度不受影响。
- 增加 sequence 位数(如果业务允许,扩大同 ms 内可分配的数量),但会减少给 timestamp/worker 位的比特数,要权衡。
- 批量/批次分配(prefetch / HiLo / Segment):
- 中央分配器(DB/etcd)分配一段 ID range(high),本地用 low 指针消费(HiLo/Segment 模式)。优点:中央压力低、本地发号速度极高。
- 适合需要全局严格唯一但不强要求按时间严格排序的场景。
- 使用更短时间粒度或更大时间位长度:例如把时间单位从 ms 改为 µs(需要更多位),理论上提高并发量但实现复杂。
- 批量生成:API 返回一批 ID 给上层,减少频繁请求。
4) 典型替代/改进实现(在生产中常见)
- Sonyflake(由日本开发者):解决了 Snowflake 的一些时钟回退问题,使用单调递增的时间戳(利用 monotonic clock),并在 nodeId 管理上更友好。
- ULID / KSUID / UUIDv1:在可排序与分布式唯一上提供替代,但会牺牲部分特点(例如 ULID 可排序)。
- HiLo / Segment ID:数据库或 coordinator 分配高位,节点本地分配低位;适合超高并发与全球分布。
5) 实战推荐(工程化的一套做法)
- workerId 分配:使用 etcd/zk 的 ephemeral 序号绑定(启动注册获得唯一 id + lease)。
- 持久化 lastTimestamp:周期性或关键点写到本地(崩溃/重启后读取以防回退复用)。
- 回退策略:
- 若回退幅度小(< X ms),spin/wait;
- 若在一个安全阈值内,采用 HLC/逻辑计数器;
- 若超阈值,报警并走备用发号(从 central allocator 获取 ID 段)。
- 监控与告警:监控本地时间跳变、sequence 耗尽、分配延迟、租约失效等指标。
- 可配置位宽:根据业务预估设定 time/worker/sequence 的位数(并留扩展计划)。
- 测试:在 VM 快照回滚 / NTP 停顿 / 随机调整系统时间 的场景做压力测试。
四、面试中如何快速回答(2–3 句话总结)
- “要防止 Snowflake 在时钟回退下冲突,基本思路是检测回退并采取等待/逻辑时钟(HLC)或备用 sequence 空间,并在启动时持久化最近时间戳以避免重启复用。生产级做法常结合 etcd/zookeeper 为节点分配唯一 workerId(带租约),并在严重回退时切换到中心化的段分配(HiLo)作为兜底。这样既保证全局唯一,又能通过本地化发号+批量预分配来实现高并发性能。”
五、补充:关键权衡(可作为面试追问的答案)
- 一致性 vs 可用性:集中 allocator 强一致但单点/延迟高;本地 Snowflake 高可用低延迟但需处理时钟问题。
- 有序性 vs 吞吐:保留时间有序性会限制每 ms 可发 ID 数量;若吞吐优先可以牺牲严格时间排序(用分段/HiLo)。
- 运维复杂度:使用 etcd/zookeeper 分配 workerId 增加运维成本,但能显著降低重复风险。
16. 服务降级与熔断(如何实现、度量与实践)
- 目标:当下游或某功能异常时,迅速降级/保护系统,保证核心功能可用并快速恢复。
- 常见机制
- 超时与重试:设置合理超时,避免请求挂死。重试配合指数退避。
- 熔断器(Circuit Breaker):典型三态(Closed/Open/Half-Open)
- 当失败率或响应延迟高于阈值,熔断器打开(Open),停止调用下游并立即返回降级结果;过一段时间进入 Half-Open 试探。
- 降级策略:返回缓存数据、默认值、功能降级(只展示基础信息)或返回错误提示。
- 隔离(Bulkhead):资源隔离(线程池/连接池)防止一个服务耗尽整个系统资源。
- 实现工具:Hystrix(已停止维护)、Resilience4j、Istio/Envoy 等服务网格提供熔断与限流能力。
- 监控指标
- 错误率、延迟 P95/P99、并发/线程使用率、熔断打开次数。
- 实战建议
- 熔断阈值不要设得太敏感;结合业务重要度定制降级策略(核心业务更保守)。
- 使用自动回退 & 慢启动(half-open 试探时限流)。
- 面试追问:熔断与限流的不同?如何设计 Half-Open 的试探策略?
1. 熔断 vs 限流 的区别
限流(Rate Limiting)
- 目标:保护系统 不被流量压垮。
- 触发条件:基于请求速率/并发数 → 超过阈值则拒绝/排队。
- 典型实现:令牌桶、漏桶、计数器。
- 场景:应对突发流量,比如秒杀、大促。
- 本质:流量“闸门”。
熔断(Circuit Breaker)
- 目标:保护调用链路,避免“雪崩效应”。
- 触发条件:调用错误率、超时率等指标超过阈值 → 熔断(拒绝请求,快速失败)。
- 典型实现:Netflix Hystrix、Resilience4j。
- 场景:调用下游服务不稳定时,避免请求堆积拖垮自己。
- 本质:健康检测 + 快速失败。
👉 一句话区分:
- 限流解决的是“请求太多”。
- 熔断解决的是“服务太烂”。
2. Half-Open 状态与试探策略
熔断器常见 3 态:
- Closed(正常)→ 所有请求放行。
- Open(熔断)→ 拒绝所有请求,快速失败。
- Half-Open(半开)→ 允许少量探测请求,看服务是否恢复。
设计 Half-Open 的试探策略
关键问题:
- 多少请求允许通过?
- 什么时候恢复 Closed?
- 如何避免流量“洪峰”瞬间打回下游?
策略一:单请求试探
- 在 Half-Open 时,只允许一个请求通过。
- 成功 → 进入 Closed,恢复流量。
- 失败 → 回到 Open,继续等待。
- 优点:安全,避免大流量打崩。
- 缺点:恢复速度慢。
策略二:小流量试探(推荐)
- 在 Half-Open 阶段,允许部分流量通过,比如 1% 或固定 QPS。
- 持续采集成功率 → 达到阈值(如 80% 成功)则关闭熔断。
- 优点:恢复平滑。
- 缺点:实现更复杂。
策略三:指数回退试探
- 第一次允许 1 个请求 → 成功则放 2 个 → 4 个 → 8 个 …
- 指数扩张直到完全恢复。
- 优点:既平滑又快,动态调整恢复速度。
- 缺点:需要精心调参数。
3. 面试答题要点
如果被问:
“熔断和限流区别?Half-Open 怎么设计?”
你可以答:
限流主要针对流量过大,避免系统被压垮,本质是“闸门”;熔断主要针对下游服务故障,本质是“保险丝”,快速失败避免雪崩。
Half-Open 阶段的核心在于小心探测服务是否恢复。常见策略有:
- 单请求试探(安全但恢复慢),
- 小比例流量试探(常用,平滑恢复),
- 指数回退试探(恢复速度和安全性兼顾)。
实际工程里,会结合失败率阈值和时间窗口来决定是否切换状态。
17. 单体架构 vs 微服务架构(区别、优劣、迁移策略)
- 单体(Monolith)
- 单一部署包(应用 + UI + DB schema)。开发简单、事务管理方便、性能调优集中。
- 缺点:团队协作瓶颈、难以按模块独立扩展、发布周期长、代码库复杂。
- 微服务(Microservices)
- 按业务域拆分为多个小服务,独立部署、独立扩缩、独立数据库(去中心化数据)。
- 优点:团队自治、按服务扩展、技术选型灵活、故障隔离。
- 缺点:分布式系统复杂(网络延迟、分布式事务、观察性、部署复杂度、运维成本)。
- 选择建议
- 初创/小团队或产品早期:倾向单体(快速迭代)。
- 业务复杂、团队规模大、需要独立扩展与技术异构:考虑微服务。
- 迁移技巧
- Strangler Pattern:逐步把单体功能提取到微服务,外层路由切换到新服务。
- 先做服务划分、定义清晰的边界与 API,建立统一的服务发现、认证和监控体系。
- 面试追问:微服务如何做事务?怎么做服务发现与熔断?如何做日志聚合与链路追踪?
18. 防抖(Debounce)与 节流(Throttle)及适用场景
防抖(Debounce)
含义:在事件停止触发后等待一段时间才执行函数;多次触发只执行最后一次。
场景:输入联想、搜索框(用户停止输入后才触发搜索)。
JS 伪代码:
1
2
3
4
5
6
7function debounce(fn, wait) {
let t;
return function(...args){
clearTimeout(t);
t = setTimeout(()=>fn.apply(this, args), wait);
}
}
节流(Throttle)
含义:在固定时间间隔内只执行一次函数(如果持续触发则按间隔执行)。
场景:滚动、窗口 resize、按键长按等需要限制频率的操作。
JS 伪代码:
1
2
3
4
5
6
7
8
9
10function throttle(fn, limit) {
let inThrottle = false;
return function(...args){
if (!inThrottle) {
fn.apply(this, args);
inThrottle = true;
setTimeout(()=> inThrottle = false, limit);
}
}
}
选择原则:需在事件结束后执行 → 用防抖;需均匀限制调用频率 → 用节流。
19. CDN(内容分发网络)详解:原理、优化与安全
- 基本原理:把静态资源缓存到离用户更近的边缘节点(PoP),用户请求被路由到最近/最优节点,降低延迟、减轻源站压力。
- 主要能力
- 静态内容缓存(图片、JS/CSS、视频分片)、动态内容加速(通过智能路由/连接复用)、SSL 终止、WAF、DDoS 防护、负载均衡、边缘计算(边缘函数/Workers)。
- 缓存控制
Cache-Control(max-age, public/private, s-maxage),ETag/Last-Modified,stale-while-revalidate。- 缓存失效策略:基于 URL 版本(内容哈希)、时间 TTL、手动 purge。
- 优化技巧
- 用内容哈希做文件名(避免复杂的 purge)。
- 使用
prefetch/preload/edge caching提升体验(尤其首屏)。 - Origin Shield(中间层缓存)保护源站免击穿。
- 安全
- 边缘 WAF、速率限制、地理封禁、签名 URL(短期授权)保护私有资源。
- 面试追问:如何缓存动态内容?CDN 缓存穿透到源站怎么办?如何做 CDN cache invalidation 最优策略?
1. 如何缓存动态内容?
很多人以为“动态内容不能缓存”,其实不是。常见方法:
(1) 页面片段缓存(Fragment Caching)
- 把页面拆分为 可缓存部分(例如导航栏、热门榜单)和 实时部分(例如购物车、账户余额)。
- 可缓存部分走 CDN/Redis,实时部分通过 AJAX / ESI(Edge Side Includes) 动态加载。
- 典型应用:门户网站首页、新闻频道。
(2) API 缓存(Response Cache)
- API 的响应虽然是动态生成的,但常常有幂等/可预测的场景(如商品详情、榜单)。
- 可以在 CDN/边缘节点缓存几秒/几十秒,大幅削峰。
- 电商详情页通常设置 短 TTL(10s~60s),保证新价格能及时更新。
(3) 参数化缓存(Key Normalization)
- 对动态请求,很多参数并不影响最终内容。
- 通过 Vary Header / 参数归一化(例如只关心
?id=123,忽略utm_source),让 CDN 命中率提升。
(4) “Stale-while-revalidate” / “Stale-if-error” 策略
- 先返回旧缓存(快速响应),后台异步刷新新内容。
- 出错时(源站挂了)也能兜底返回过期内容。
- Cloudflare / Fastly / Nginx 都支持。
👉 一句话总结:动态内容不是不能缓存,而是要拆分/短 TTL/容忍旧数据/按需刷新。
2. CDN 缓存穿透到源站怎么办?
所谓 穿透源站 = CDN 缓存没有命中,所有请求都打到源站 → 源站被打爆。
常见原因
- 请求参数多样化 → cache key 太分散(
?timestamp=xxx、?random=xx)。 - 恶意攻击 / 爬虫 → 故意制造不命中的 key。
- 缓存 TTL 太短 → 经常 miss。
- 动态内容未合理拆分。
解决方案
- 参数归一化:只对真正影响结果的参数参与缓存。
- 缓存缺省值:对无效参数/不存在数据,缓存一个“空值”(短 TTL),避免透传。
- CDN 层限流 / WAF:对恶意爬虫或异常请求先拦截。
- 热点 Key 预热:秒杀/大促前预先把热门内容推到 CDN 节点。
- 多级缓存架构:CDN → 边缘缓存 → 应用层本地缓存 → DB,逐级兜底。
👉 经验法则:能在 CDN 命中的,尽量别让它穿到源站。
3. CDN Cache Invalidation(缓存失效)的最优策略
缓存更新是最难的地方,因为 缓存更新 vs 性能/成本是矛盾。常见策略:
(1) TTL 驱动(时间驱动)
- 给资源设置 TTL,到期后自动失效。
- 优点:简单,性能好。
- 缺点:实时性差(例如价格变化要等 60s)。
(2) 主动刷新(Push Invalidation)
- 应用在数据变更时,调用 CDN API 主动刷新或 Purge。
- 优点:强一致性。
- 缺点:成本高,刷新频繁会拖慢性能(尤其全站刷新)。
(3) Key 版本号(Cache Busting)
- 热点资源:短 TTL + Stale-while-revalidate,兼顾实时性和性能。
- 冷门资源:长 TTL,减少源站压力。
- 数据敏感(价格/库存):主动刷新或 Key 版本号。
👉 最佳实践:
- 静态内容 → 长 TTL + 版本号(Cache Busting)。
- 动态内容 → 短 TTL + 主动刷新 + SWR(延迟刷新)。
- 核心数据(库存/支付) → 基本不走 CDN,而是走直连服务。
✅ 面试答题思路:
动态内容可以通过片段缓存、短 TTL、参数归一化、Stale-while-revalidate 等方式缓存。
当 CDN miss 穿透到源站时,要通过参数归一化、空值缓存、多级缓存和 WAF 限流来防御。
Cache invalidation 的最优解没有银弹,通常是 TTL 驱动 + 主动刷新 + 版本号策略的组合。静态资源走版本号,动态资源走短 TTL + SWR,关键业务则走直连。
20. RBAC(Role-Based Access Control)详解
- 核心概念
- 角色(Role):代表一组权限(Permission)。
- 权限(Permission):通常是对资源的操作(read/write/delete)。
- 用户(User):被赋予角色,从而继承权限。
- 模型特性
- 支持 角色继承/层级(例如 Admin 包含 User 权限)。
- 强调最小权限原则(least privilege)。
- 设计要点
- 把权限映射到资源/操作(资源 + 操作作为权限单元)。
- 支持动态权限(例如 ABAC)用于属性/上下文判断(时间、IP 等)。
- 缓存权限(例如 ACL cache)以加速鉴权,但需处理权限变更的失效。
- 实现数据库模式(简化)
- tables: users, roles, permissions, user_roles, role_permissions。
- 扩展:ABAC(Attribute-Based)、PBAC(Policy-Based)当权限复杂时使用策略引擎(OPA)。
- 面试点:RBAC 的优缺点、如何在分布式系统快速授权(token 携带权限/JWT、或网关做中央鉴权)。
21. Cookie(概念、属性、安全实践)
概念:浏览器用来在客户端储存和跨请求携带少量数据(如 session id、偏好设置)。
重要属性
Name=Value、Domain、Path、Expires/Max-Age、Secure(仅 HTTPS)、HttpOnly(JS 不能访问)、SameSite(None/Lax/Strict)。
安全实践
HttpOnly防止 XSS 直接窃取 Cookie(但 CSRF 仍可能触发)。SameSite设置合理值减少 CSRF(Strict 最严格但影响跨站场景,Lax 常用)。- 与
Secure配合,Cookie 只在 HTTPS 下传输。 - 对敏感数据不直接存储在 Cookie 中(只存 session id 或 token 的引用)。
大小与数量限制:浏览器对单个 cookie 与域名下的 cookie 数量有上限(实现时要注意)。
面试追问:Cookie 与 localStorage 的区别?如何用 SameSite 防 CSRF?如何设置过期时间?
Cookie和Session的区别?
1. Cookie vs localStorage
Cookie
- 作用:主要用于服务端与客户端交互(尤其是携带身份信息)。
- 特点:
- 每次请求自动携带到服务端(在请求头里)。
- 可设置
HttpOnly(JS 无法访问,防止 XSS 窃取)。 - 可设置
Secure(仅 HTTPS 传输)。 - 可设置
SameSite(防 CSRF)。
- 大小限制:单个域名约 4KB。
- 过期时间:可设置
Expires或Max-Age,到期浏览器删除。
localStorage
- 作用:纯前端存储,浏览器本地缓存数据。
- 特点:
- 仅在客户端使用,不会自动随请求发送。
- 容量较大(5MB 左右)。
- API 简单:
localStorage.setItem/getItem。 - 没有过期时间,除非手动清除。
- 安全性:易受 XSS 攻击窃取(不能设置 HttpOnly)。
👉 一句话总结:
- Cookie 适合 和服务端交互的会话信息。
- localStorage 适合 存放纯前端用的配置/缓存。
2. SameSite 防 CSRF
SameSite 是 Cookie 的一个属性,用来限制跨站请求时 Cookie 的发送:
SameSite=Strict:最严格,只有在同域请求时才会带 Cookie。跨站点请求一律不带。SameSite=Lax:默认模式,跨站点 GET 请求 会带 Cookie,但 POST/PUT/DELETE 不会带。SameSite=None:允许跨站点请求携带 Cookie,但必须搭配Secure(仅 HTTPS)。
👉 防 CSRF 的思路:
CSRF 攻击依赖于“攻击者页面发请求时,浏览器自动带上受害者的 Cookie”。
通过 SameSite=Lax/Strict,跨站点的请求大多数情况下不会携带 Cookie,从而阻断 CSRF 攻击。
3. Cookie 的过期时间
Session Cookie:没有设置过期时间,浏览器关闭就删除。Persistent Cookie:设置了Expires(绝对时间)或Max-Age(相对时间),到期自动失效。
示例:
1 | Set-Cookie: token=abc123; Max-Age=3600; HttpOnly; Secure; SameSite=Strict |
👉 表示 token 有效期 1 小时,HttpOnly 防 XSS,Strict 防 CSRF。
4. Cookie vs Session
Cookie
- 存在客户端,由浏览器管理。
- 大小限制(4KB 左右)。
- 安全性相对低(可能被窃取、篡改)。
Session
- 存在服务端,通常存储在内存/Redis/数据库。
- 客户端只保存 SessionID(一般放在 Cookie 里)。
- 服务端可存放更多、更安全的数据。
- 可集中管理(比如用户强制下线时,只需删服务端 session)。
👉 核心区别:
- Cookie:存储在客户端,可能被窃取篡改。
- Session:存储在服务端,客户端只保存 ID,更安全。
面试答法总结
Cookie 用于客户端和服务端的状态传递,支持过期时间、HttpOnly、Secure、SameSite 等安全属性;localStorage 是纯前端存储,不会自动带到服务端,容量更大但不安全。
CSRF 可以用 Cookie 的 SameSite 属性来防御,配合
Strict/Lax限制跨站请求携带 Cookie。Cookie 有过期时间(Session Cookie / Persistent Cookie),而 localStorage 默认没有过期。
Session 是存储在服务端的状态信息,客户端只保存一个 SessionID(通常在 Cookie 中),比直接把敏感信息存在 Cookie 里更安全。
22. Session(服务器端会话管理)
- 基本模式
- 服务器端 Session:服务器保存 session 状态(内存、Redis、DB),客户端仅持有 session id(cookie)。
- 无状态 Token(如 JWT):状态保存在 token 本身,服务器不保存 session(但牺牲了即时下线/撤销能力)。
- Session 存储
- 本地内存(单实例)、共享存储(Redis 常用)、数据库(持久但慢)。
- 对于分布式多实例,建议用 Redis 或数据库持久化 session,或使用 sticky session(不推荐)。
- 安全与实践
- Session 固定攻击防护(Session Fixation):登录后旋转 session id。
- 会话过期、滑动过期(每次活动延长过期时间),并支持登出时的立即失效(需要服务端存储)。
- 持久化/清理旧 session:TTL + 定期清理。
- 面试追问:为什么 JWT 无法轻易实现强撤销?如何在微服务中共享 session(Token 认证 + introspection 或集中认证服务)?如何设置过期时间?
1. 为什么 JWT 无法轻易实现强撤销?
原因
- JWT(JSON Web Token)是无状态的:
生成后 Token 本身携带所有认证与授权信息(通常有sub, exp, scope等),服务端只需验证签名和有效期即可,不必访问数据库。 - 签发后不可变:
除非你更换签名密钥或让 Token 过期,否则服务端无法单方面使其失效。 - 难撤销场景:
- 用户主动注销(Logout)
- 密码修改 / 权限变更
- Token 被盗用
- 管理员紧急冻结
这就是为什么 JWT 适合 高性能分布式认证,但在安全和撤销上天然存在缺陷。
2. 解决强撤销的常见思路
2.1 Blacklist / Revocation List(黑名单)
- 做法:服务端维护一个被撤销的 JWT
jti(JWT ID)或用户 ID 列表,每次验证时查询。 - 缺点:查询会降低性能;如果存储在 Redis,还会增加网络开销。
2.2 短生命周期 + Refresh Token
- 思路:
- Access Token 只活几分钟(5~15min),即使被盗影响也有限。
- Refresh Token 长生命周期,但服务端可存储并随时撤销。
- 优点:大幅降低撤销的复杂度,只要拒绝 Refresh Token 就能彻底阻止后续访问。
- 缺点:需要额外的 Refresh 流程,复杂度增加。
2.3 Introspection(令牌内省)
- OAuth2 标准:客户端提交 Token 给认证服务,认证服务实时返回其有效性和权限信息。
- 实现:Token 变成“有状态”,服务端能立即撤销。
- 缺点:性能不如纯 JWT,需要调用认证服务。
2.4 Key Rolling(密钥轮换)
- 方式:定期更换 JWT 的签名秘钥,旧 Token 一律失效。
- 适用场景:管理员强制全员下线。
- 缺点:全量失效,粒度粗。
3. 微服务中如何共享 Session?
方案 1:Token 认证(JWT)
- 每个微服务只需验证签名即可,无需共享状态。
- 优点:高性能、分布式友好。
- 缺点:撤销困难,如上所述。
方案 2:Introspection / 中央认证服务
- 所有请求先交给 网关 / Auth Service,由其验证 Token 是否有效。
- 服务内部调用时使用服务间信任(例如 mTLS / 内部短期 Token)。
- 优点:可即时撤销,权限可动态变更。
- 缺点:增加认证服务负载。
方案 3:集中式 Session(Redis / DB)
- 传统 Session 存储在 Redis,全局共享。
- 优点:支持强撤销、实时变更。
- 缺点:与 JWT 的无状态理念相悖;性能依赖 Redis。
4. 如何设置过期时间?
JWT Access Token:建议 5~15 分钟
Refresh Token:7 天 ~ 30 天(可配置,支持续签)
Session:一般 30 分钟不活跃就过期,可以 Sliding Expiration(续命策略)
1.在 Servlet 中动态设置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
public class SessionExampleServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
// 获取当前会话(如果不存在则创建)
HttpSession session = request.getSession();
// 设置过期时间为30分钟(单位:秒)
// 注意:这是从最后一次请求活动开始计算的非活动时间
session.setMaxInactiveInterval(30 * 60);
// 存储数据到Session
session.setAttribute("username", "admin");
response.getWriter().println("Session已创建,过期时间30分钟");
}
}2.在 web.xml 中全局配置
1
2
3
4
5
6
7<!-- web.xml -->
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="4.0">
<!-- 设置所有Session的默认过期时间(单位:分钟) -->
<session-config>
<session-timeout>30</session-timeout> <!-- 30分钟 -->
</session-config>
</web-app>3.使用 Spring 框架时的配置
1
server.servlet.session.timeout=1800 # 30分钟
setMaxInactiveInterval(int seconds)设置的是非活动过期时间,即从用户最后一次访问服务器开始计时- 当设置为
-1时,表示 Session 永不过期(不推荐在生产环境使用) - web.xml 中
session-timeout的单位是分钟,而setMaxInactiveInterval的单位是秒 - 动态设置(代码中)的优先级高于 web.xml 中的全局配置
黑名单策略:可以保留一段时间,比如存储在 Redis 并设置 TTL。
✅ 总结一句话:
- JWT 高性能但难撤销 → 用 短生命周期 + Refresh Token 缓解;
- 需要强撤销场景 → 用 Introspection 或集中认证服务;
- 微服务共享会话 → 要么 JWT 自带权限,要么集中式认证。
23. Token(JWT、Opaque Token、OAuth2、刷新与安全)
Token 类型
- Opaque token(不透明):随机字符串,服务器需校验/查询(例如 introspection endpoint)。
- JWT(JSON Web Token):自包含,
header.payload.signature,服务可离线验证签名并读取声明(claims)。
JWT 结构
- Header(类型、算法) | Payload(claims:sub, exp, iat, scopes) | Signature(HMAC 或 RSA/ECDSA)。
优缺点
- JWT:无状态验证、性能好;缺点:难以即时撤销(需黑名单/JTI)、token 体积较大、滥用风险高。
- Opaque token:撤销/控制更容易(服务器查),但需状态存储和额外网络开销。
OAuth2 & Flow
- 常见 flows:Authorization Code(推荐带 PKCE 用于 browser + SPAs)、Client Credentials(服务间)、Resource Owner Password(不推荐)。
- 使用 refresh token 刷新 access token(短期 access token + 更长 refresh token)。
安全实践
- Access token 短期有效、Refresh token 使用 rotation(每次刷新发新 refresh token 并使旧一个失效)。
- 存储在浏览器:若放 Cookie,应用
HttpOnly+Secure+SameSite;若放 localStorage 则易被 XSS 窃取。 - 使用
jti或 token 黑名单/撤销机制在必要时撤销 token。 - 签名算法使用非对称(RS256)可以方便公钥验证;密钥管理与轮换非常重要。
实现细节
- 在微服务中常使用 Token Introspection / Auth Service:服务接到 token 时向 auth server 校验或直接验证 JWT 签名。
- 结合 OAuth scopes 与 RBAC 做精细权限控制。
面试追问:如何安全存储 refresh token?JWT 怎么做 token 撤销?什么是 token binding?
双刷新策略详细讲一下?Token和Session的比对?
1. 如何安全存储 Refresh Token
Refresh Token 是长期有效的凭证,如果泄露风险高,因此存储安全非常重要:
客户端存储方式
- 移动端/桌面应用
- 安全存储在系统提供的Keychain / Keystore / Secure Storage
- 不要存入普通本地文件或 SharedPreferences/NSUserDefaults 明文
- Web 前端
- 不要存 localStorage(易被 XSS 窃取)
- HttpOnly + Secure Cookie 最安全
- 可结合 SameSite=Strict/Lax 防止 CSRF
服务端存储方式
2. JWT 怎么做 Token 撤销
JWT 默认无状态,不依赖服务器,所以强撤销有难度。常见解决方案:
(1) 短生命周期 + Refresh Token
- Access Token 5–15 分钟
- Refresh Token 7–30 天
- 通过拒绝 Refresh Token 刷新来实现撤销
(2) Token 黑名单
- 维护被撤销的 JWT ID(
jti)列表 - 每次验证 JWT 时检查是否在黑名单
- 可结合 Redis TTL 自动过期
(3) Introspection / 中央认证
- 微服务验证 Token 时调用 Auth Service 查询有效性
- 支持即时撤销
(4) Key Rolling(签名密钥轮换)
- 更换 JWT 签名密钥 → 所有旧 Token 失效
- 用于全局紧急下线
3. Token Binding
Token Binding 是一种安全机制,用来防止 Token 被盗用。核心思想:
- 将 Token 与客户端的 特定密钥 / TLS 会话 绑定
- 攻击者即使窃取 Token,没有对应的客户端密钥,也无法使用
- 优势:防止中间人攻击 / Token 被 XSS / CSRF 盗用
类似于“钥匙只能在原来的锁上使用”,增加了 Token 安全性。
4. 双刷新策略(Double Refresh / Sliding Session)
解决问题:短生命周期 Access Token + 长生命周期 Refresh Token 的安全与可用性平衡
核心思想
- 两个 Token:Access Token + Refresh Token
- 滑动刷新(Sliding Refresh)策略:
- Access Token 到期 → 使用 Refresh Token 获取新的 Access Token
- 同时刷新 Refresh Token(生成新 Refresh Token)
- 保证:
- Token 被盗用时,旧 Token 在很短时间内失效
- 用户活跃时,Token 可持续滑动续期
- 用户不活跃 → 自动过期
流程示意
- 登录 → 返回
{access_token, refresh_token} - Access Token 到期 → 请求刷新
- Auth Service 验证 Refresh Token → 签发新的 Access Token + Refresh Token
- 原 Refresh Token 标记作废(服务端存储或哈希验证)
好处:即使 Refresh Token 被窃取,只能使用一次,减少长期滥用风险。
5. Token 和 Session 对比
| 维度 | Token (JWT) | Session |
|---|---|---|
| 存储位置 | 客户端(可无状态) | 服务端(存储 SessionID + 数据) |
| 状态 | 无状态,可横向扩展 | 有状态,需共享存储(Redis/DB) |
| 验证方式 | 签名验证,无需访问 DB | 查 Session 存储 |
| 撤销策略 | 难撤销,需黑名单/短生命周期/刷新机制 | 容易撤销,删除 Session 即失效 |
| 安全性 | 易受 XSS,如果存 localStorage | 更安全,客户端只存 SessionID,可 HttpOnly Cookie |
| 可扩展性 | 高,可横向扩展 | 需共享 Session 存储,跨微服务稍复杂 |
✅ 面试答法总结
Refresh Token 应该安全存储(Web 用 HttpOnly+Secure Cookie,移动端用 Keychain/Keystore),并支持撤销。
JWT 本身难以强撤销,可以用短生命周期 + 黑名单 + Refresh Token + 中央 introspection。
Token Binding 可以绑定 Token 与客户端密钥,防盗用。
双刷新策略可以在滑动刷新 Access Token 的同时刷新 Refresh Token,提高安全性并保持用户在线体验。
Token 与 Session 本质差异在于“无状态 vs 有状态”,Token 更适合分布式横向扩展,Session 更容易撤销和管理敏感数据。
